remind
- Hypothesis =>
- Cost Function =>
- => 가 생략되어 간략화 됨.
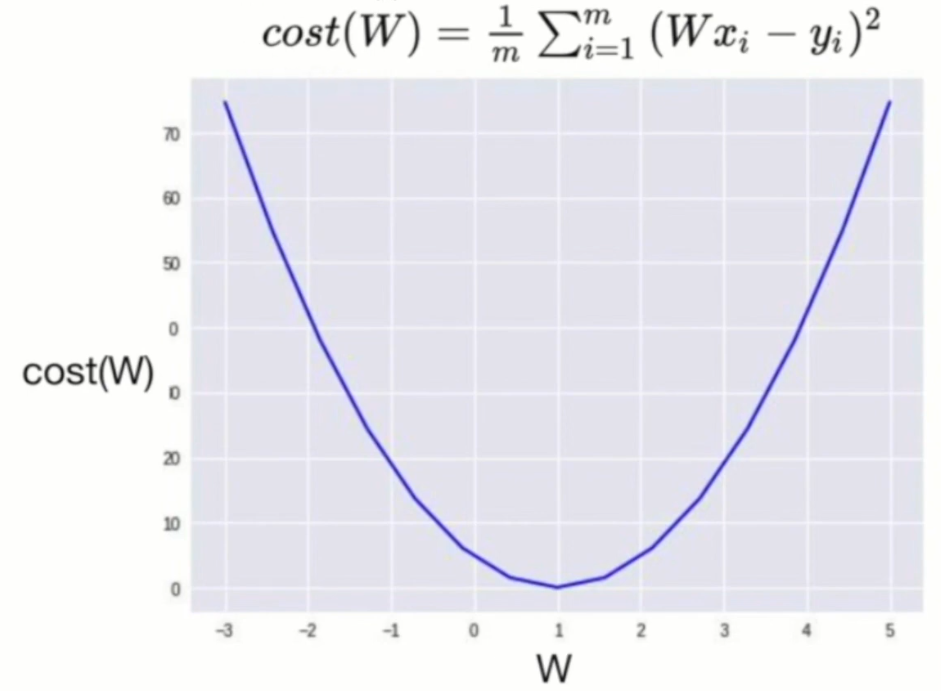
cost가 어떻게 생겼는가?
-
data
-
-
-
-
-
즉, 일 때 가장 크기가 작다!
-
가장 작은 값(1)을 이제 기계적으로 찾아야 한다.
-
Gradient descent algorithm
=> 최소값을 찾는 가장 유명한 방법
- 손실(비용) 최소화 방법
- 변수가 여러개일 때도 사용할 수 있다.
사용 방법
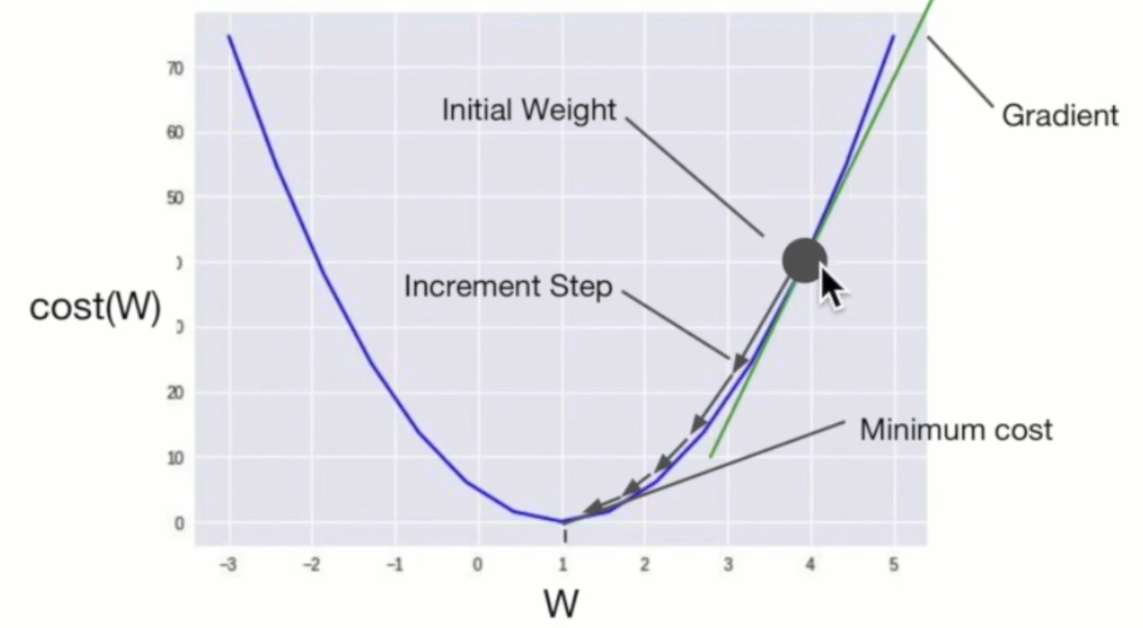
- 임의의 초기값에서 시작한다.
- 초기값 (혹은 임의의 값)에서 시작한다.
- 그리고 가 조금씩 줄어들도록 와 의 값을 바꾼다.
- 값을 줄일 때 기울기 값을 구해서 가 줄어들게 한다.
- 이 과정을 최소점에 도달했다고 판단될때까지 반복한다.
- 2차 함수의 임의의 한 점에서 기울기를 구한다. (예시에서는 양수값이다)
- 이 기울기 값을 에 곱해 에서 빼주면 weight는 조금 내려오게 된다.
- => 반복
- => 언젠가 기울기가 이 되어 더 이상 줄어들지 않는다.
- => 이 기울기(Gradient)는 이 점에서 이 함수의 미분값이다.
Formal definition
- =>
- 나누는 값을 에서 으로 변경했다. 이 나누는 숫자는 무엇을 하든 cost의 특성에는 영향이 없다.
- 이는 cost 함수를 미분 시 뒤의 제곱이 앞으로 나오면서 과 약분되도록 하기 위함이다.
최종
- (Gradient descent algorithm은 의 값을 지속적으로 업데이트 하게 된다.)
- learning rate : 알파값. 작은 상수이다. 이 값을 얼마나 반영할지를 결정한다. 값이 클수록 크게 변하게 된다.
- : 편미분. 에 대해서 미분
- 즉, cost function을 에 대해서 미분해서 알파값을 곱한 값을 에서 빼준 값으로 업데이트 한다.
- 미분 결과:
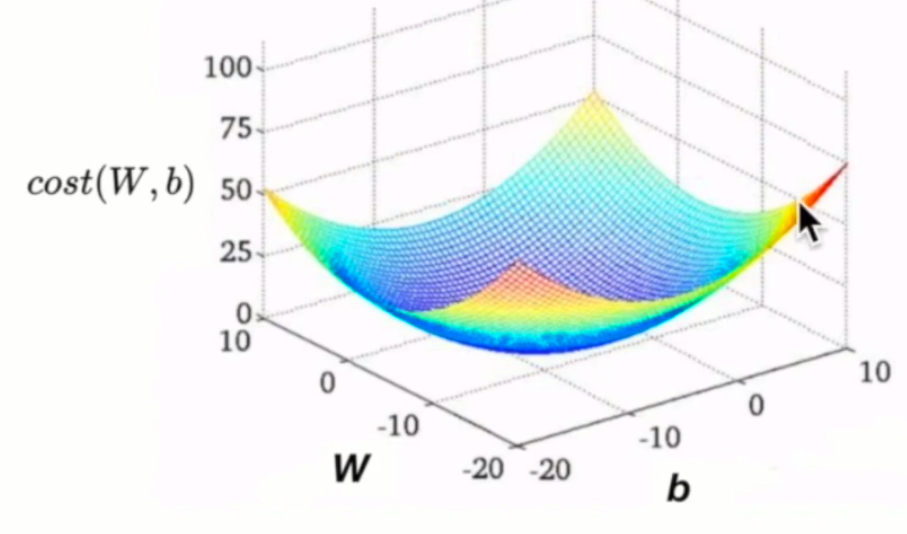
Convex function
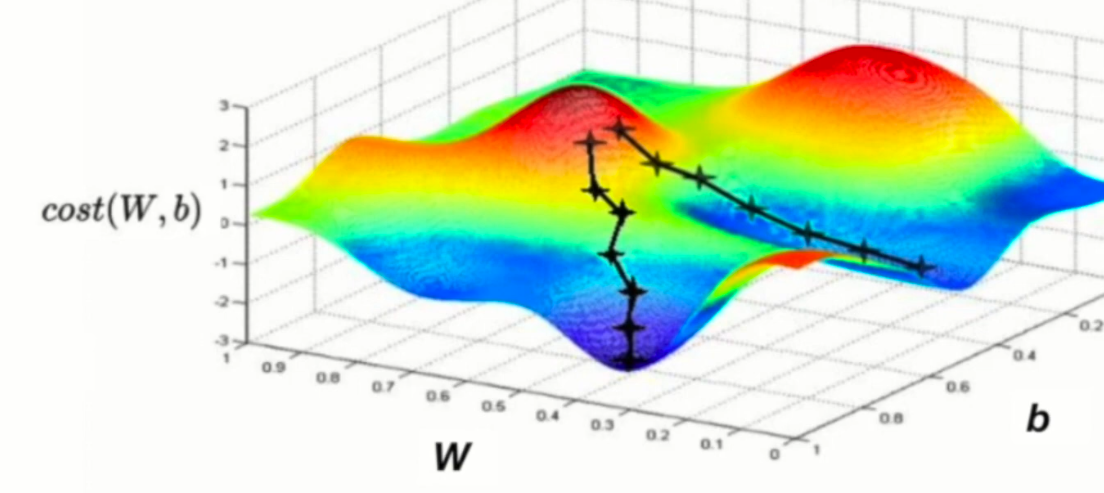
: Gradient descent 알고리즘은 주변 경사를 따라서 더 낮은 지점을 찾는 알고리즘이다.
- 그러나 이미지와 같은 경우라면, 아무리 많이 해도 전체에서의 최저점을 찾지 못할 수도 있다.
- 로컬 미니멈이 있는 상황에서는 쓸 수 없다!
- 그러나 로컬 미니멈이 없다면 이상적으로 사용할 수 있다.
출처: 모두를 위한 딥러닝 강좌 2
https://www.youtube.com/watch?v=7eldOrjQVi0&list=PLQ28Nx3M4Jrguyuwg4xe9d9t2XE639e5C
