데이터베이스
- 데이터베이스 : 데이터의집합
- 관련있는 대용량의 데이터 집합을 체계적으로 구성해 놓은 것
- DBMS : 데이터베이스를 관리
- MySQL : 무료 & 유료
- MariaDB : 무료
- Oracle : DBMS 점유율시장에서 1등
- DB2 : 메인 프레임 시장 1등
- SQL Server
- Postgres
데이터베이스 특징
- 무결성Integrity (안의 데이터가 오류가 있어서는 안된다)
- 제약조건(constraints)을 이용해서 데이터의 무결성을 유지한다
- 데이터의 독립성을 보장해야 한다
- 데이터베이스의 크기나 위치 등을 변경해도 기존에 사용하고 있는 소프트웨어는 영향을 받지 않아야한다
- 보안
- 데이터 중복은 최소화 시킨다
- 무결성에 문제가 생기게된다
- 안전성 (백업 backup/재업로드restore)기능을 제공
DBMS의 변화
- 계층형 데이터베이스
- 네트워크 데이터베이스
- IBM ⇒ 만든 관계형 데이터베이스
- 객체지향 데이터베이스
- 객체-관계형 데이터베이스 : Oracle(선두주자)
관계형 데이터베이스
- 여기서 관계는 테이블이다
- 데이터를 저장하기위한 표형태의 구조
- PK: 각각의row(행)을 unique(유일)하게 식별할 수 있도록 하는 컬럼(colum)의 집합
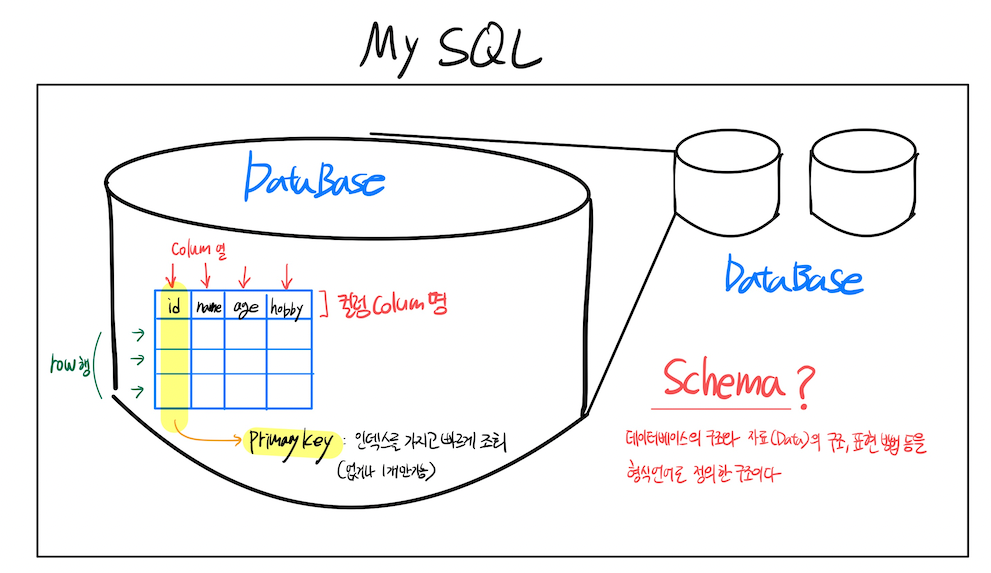
- Schema : 데이터베이스 안에 datad의 구조, data의 표현방법, data 타입, data 관계
- 형식 언어를 이용해서 정의한 구조
- 관점에 따라서 크게 3가지로 나뉘어진다
- external schema(외부스키마) : 어플리케이션단에서 최상위에서 데이터베이스를 보는경우
- 테이블 형태로 봄
- conceptual schema(개념스키마): 데이터베이스안에 데이터를 논리적인 구조로 정리된 것
- Internal schema(내부스키마) : 데이터를 하드웨어 시스템에 어떤 형태로 저장되어있는지 기술하는 것
- external schema(외부스키마) : 어플리케이션단에서 최상위에서 데이터베이스를 보는경우
- MySQL에서는 Schema를 데이터베이스와 동일하게 이야기 한다
- 데이터베이스는 대소문자를 구별하지 않는다
- 테이블이름TBL ← 테이블을 구분하기위한 관례로 쓰기도 함
MySQL 세팅
- 환경설정
- server, workbench, connectors → J, Samples and Examples
MySQL의 utility
- 예약어 대문자로 세팅하기 : edit → format → update Keyword
- 자동완성하기 :
ctrl + space- 주석 :
ctrl + space( - - 사용하기)- SQL 표준형태로 바꾸기 :
ctrl + b- 사용자과 생성과 권한
Index
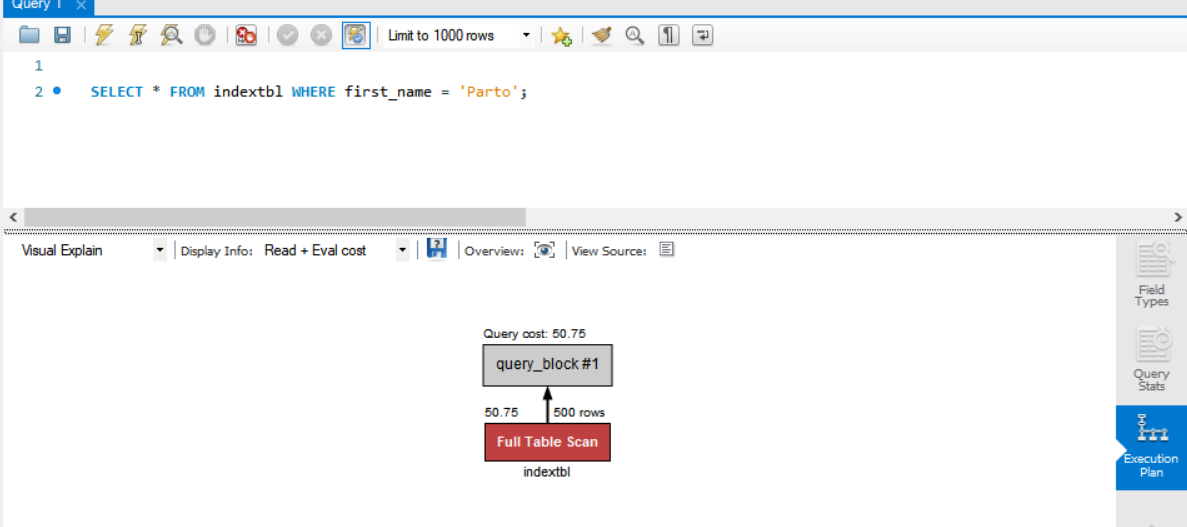
- 일반 쿼리문의 경우
SELECT * FROM indextbl WHERE first_name = 'Parto';
일반 쿼리문을 한 경우 ExecutionPlan을 보면 결과값을 나오기까지 얼마나 시간이 걸렸는지 확인할 수 있다. 쿼리의 작업방식을 확인할 수 있음
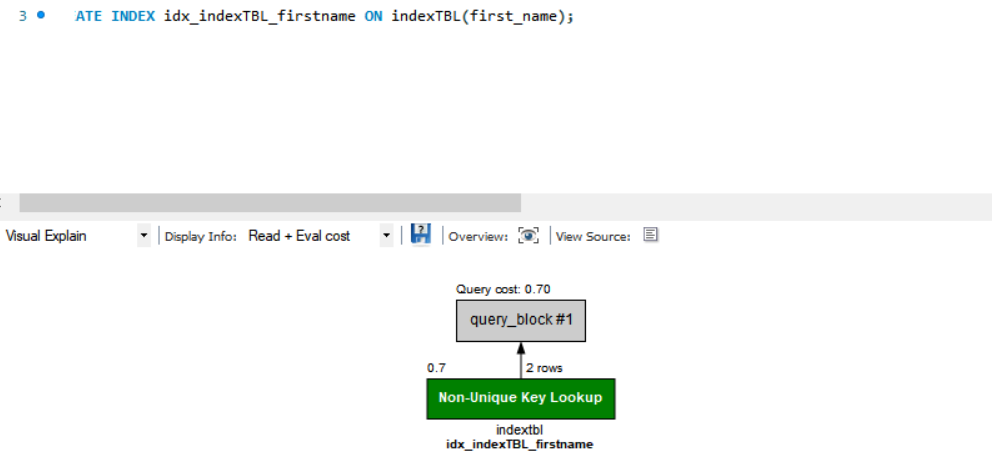
- 인덱스를 적용하고 난 뒤의 경우
인덱스는 테이블의 데이터를 조회할 때 빠르고 효과적으로 조회할 수 있도록 도와주는 역활을 하는 데이터 구조이다. 조회는 빠르지만 INSERT, UPDATE등을 수행할 때는 느려지기 때문에 조회가 많은 테이블을 기준으로 설정하여야 한다SELECT * FROM indextbl WHERE first_name = 'Parto'; CREATE INDEX idx_indexTBL_firstname ON indexTBL(first_name);
인덱스를 적용하고 난 뒤 속도가 더 빨라진것을 확인할 수 있다
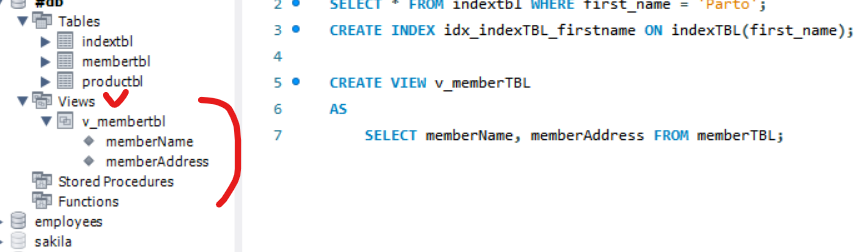
View 가상의 테이블
- 가상의 테이블
- 실제로 데이터를 가지고 있다
- 데이터를 가지고있는 것은 테이블 뿐이다
memberName과 memberAddress를 가지고 가상의 view를 만든다CREATE VIEW v_memberTBL AS SELECT memberName, memberAddress FROM memberTBL;
View를 쓰는 이유는?
- 데이터를 안전하게 유지하기 위해서
- 개발자들에게 직접적으로 노출시키지 않게 하기 위해서
- 데이터의 보안을 위해서
- 사용의 편리성
테이블은 단위로 나눠져있는데 비즈니스 코드를 작성할때 여러 테이블을 조인해서 작성해야한다. 이때 뷰로 원하는 테이블을 만들어 두면 쿼리작성을 용이하게 사용하기 할 수 있다
Stored Procedure 내장 프로시저
- 저장된 함수
- 데이터베이스를 전문적으로 사용하는 사람이 프로시저와 뷰를 사용하여 개발자에게 전달한다
DELIMITER // CREATE PROCEDURE myFUNC() BEGIN SELECT * FROM memerTBL WHERE memberName = '아이유'; SELECT * FROM productTBL WHERE productNAme = '냉장고'; END// DELIMITER ;

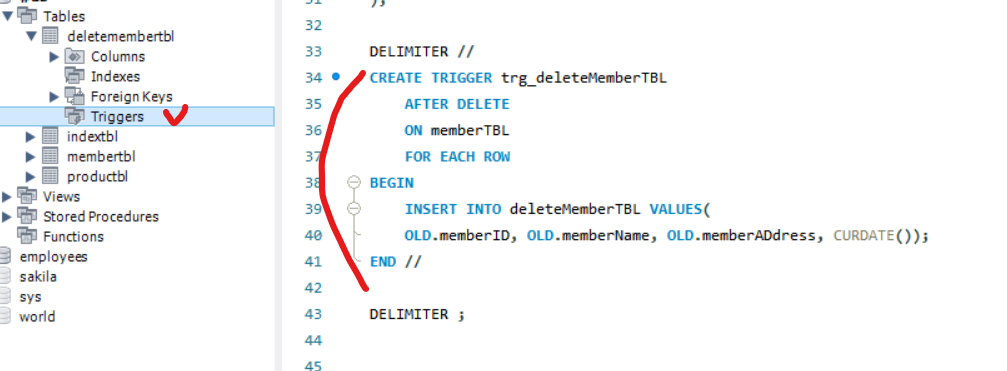
Trigger
- 테이블에 부착시키는 형식이다
- 테이블의 insert, update, delete가 발생했을때 트리거가 확인
- 일반적으로 flag 처리를한다
- 해당 사용자에 대해서 업데이트 처리를 할경우 DB가 검색하는데 오래걸린다
- after [행동] 행동이후에 실행하라
- on 붙이다
- FOR EACH ROW 각각에 해라
- old (on 옆에 붙인 테이블을 의미)
DELIMITER // CREATE TRIGGER trg_deleteMemberTBL AFTER DELETE ON memberTBL FOR EACH ROW BEGIN INSERT INTO deleteMemberTBL VALUES( OLD.memberID, OLD.memberName, OLD.memberADdress, CURDATE()); END // DELIMITER ;
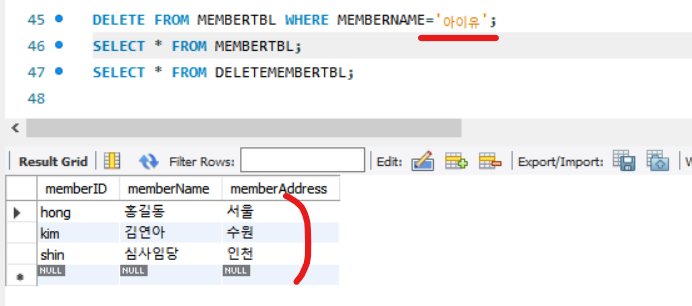
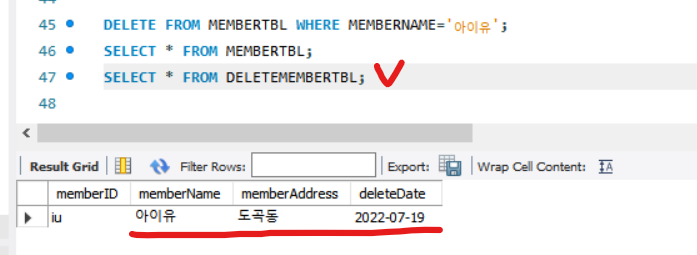
데이터를 삭제후 컬럼에서 확인해보기
- member 테이블의 아이유를 삭제하고 난 뒤
- deleteMember 테이블에 아이유가 생긴것을 확인 할 수 있다
Query
Varchar vs Char
- Char (10) : 고정문자 : 뭘쓰던 10씩 나감
- 데이터가 많이 차지 되지만 연산이 빠르다
- Varchar(10) : 들어가는 데이터에 맞춰서 데이터 사이즈가 변경됨 최대치가 10
- 구조
SELECT
*
FROM
memberTBL
WHERE
memberName = '심사임당'
GROUP BY
HAVING {group의 조건}
ORDER BY;- USE를 사용한 경우 schema를 생략 할 수 있다
-- 사용할 데이터베이스 선택
USE employees;
SELECT *FROM titles;
-- 원칙적으로는
SELECT *FROM employees.titles;- 테이블 명세 확인하기
-- 테이블 명세 확인하기
DESC titles;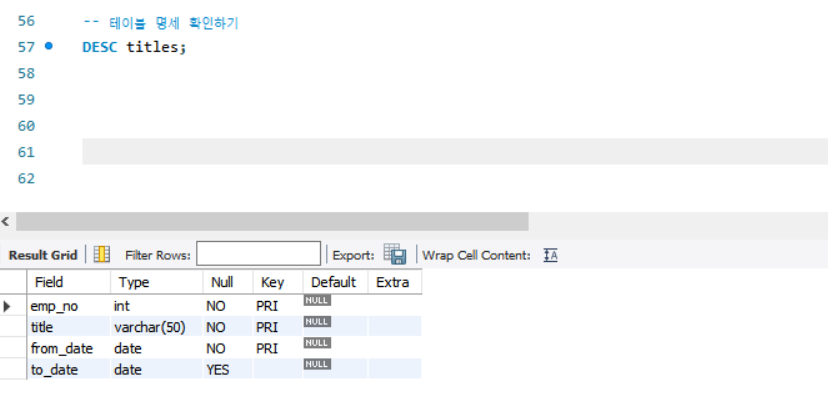
- Alias를 사용
-- Alias
select first_name AS '이름',
gender AS '성별',
hire_Date AS '입사일'
From employees;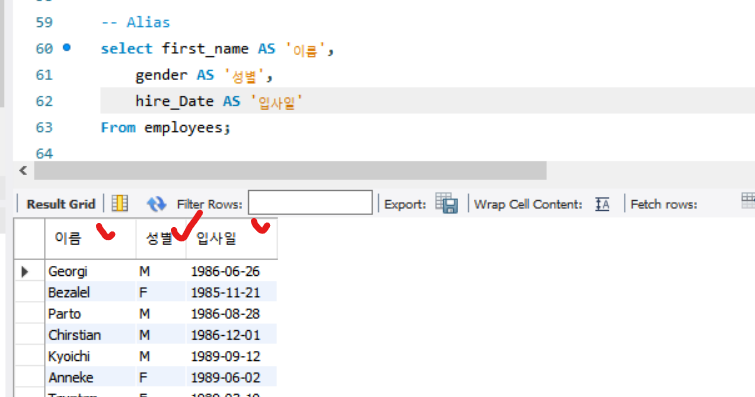
쿼리공부
-- 이름이 김경호인 사람을 찾기
SELECT * FROM usertbl WHERE name = '김경호';
-- 1970년 이후에 출생하고 신장이 182인 사람의 아이디와 이름을 조회
SELECT userID, NAME
FROM usertbl
WHERE birtYear>=1970 AND height>=182;
-- 키가 180~ 183인 이름과 키를 조회하세요
SELECT NAME, HEIGHT FROM USERTBL
WHERE HEIGHT >=180 AND HEIGHT <=183;
SELECT NAME, HEIGHT FROM USERTBL
WHERE HEIGHT BETWEEN 180 AND 183;
-- 지역이 경남, 전남 경북인 사람을 조회하세요
SELECT NAME, ADDR FROM USERTBL
WHERE ADDR='경남' OR ADDR='전남' OR ADDR ='경복';
SELECT NAME, ADDR FROM USERTBL
WHERE ADDR IN ('경남','전남','경북');
-- 성이 김씨 사람인 사람들의 이름과 키를 조사하세요!
SELECT NAME, HEIGHT FROM USERTBL
WHERE NAME LIKE '김%'; -- 김_ : 김홍, 김치 한글자를 의미
-- 먼저가입 한 순서대로 출력하세요
SELECT NAME, MDATE FROM USERTBL
ORDER BY MDATE ASC; -- 날짜가 작은게 위로가려면 오름차순 ASC / 내림차순 DESC
-- 회원들의 거주지역이 어디인가 // 데이터 중복을 피하기 위해서는?
SELECT ADDR FROM USERTBL;
SELECT distinct ADDR FROM USERTBL; -- distinct : 중복제거
-- 먼저 가입한 순서로 4명만 출력하기
SELECT MDATE FROM USERTBL ORDER BY MDATE ASC LIMIT 4; -- // 오라클은 LIMIT가 안된다!
SELECT MDATE FROM USERTBL ORDER BY MDATE ASC
LIMIT 1,2; -- 1~2번까지만 뽑기 (INDEX 0부터 시작)서브쿼리
-- 김경호보다 키가크거나 같은 사람의 이름과 키를 조회
-- 1
SELECT NAME, HEIGHT FROM USERTBL
WHERE NAME='김경호'; -- 키가 177
-- 2
SELECT NAME, HEIGHT
FROM USERTBL
WHERE HEIGHT>=177;
-- 1+2 정답
SELECT NAME, HEIGHT
FROM USERTBL
WHERE HEIGHT>= (
SELECT HEIGHT
FROM USERTBL
WHERE NAME='김경호'
);
-- 지역이 경남인 사람의 키보다 키가 크거나 같은 사람을 조회하세요
SELECT NAME, HEIGHT FROM USERTBL
WHERE HEIGHT >= ANY( -- // ANY: 어떤것보다 ALL: 전체
select HEIGHT
FROM USERTBL
WHERE ADDR='경남'
);테이블 복사
- FK, PK와 같은 제약조건들은 복사가 안된다!
-- 테이블을 복사하는 전형적인 방법 //데이터만 복사가 된다 (fk, PK 제약조건은 복사가 안됨)
CREATE TABLE BUYTBL1(
SELECT * FROM BUYTBL1
);집계함수 & GROUP BY
- SUM
-- 구매 테이블에서 사용자가 구매한 물품의 갯수를 출력한다
-- 1. 같은 사용자끼리는 하나의 묶음으로 묶어야 한다
-- 2. 각각의 묶인 애들 별로 합을 구한다
SELECT * FROM BUYTBL;
select userId, SUM(AMOUNT) AS 구매수량
from buytbl
GROUP BY USERID;
-- 각 사용자별 구매 테이블에서 구매엑의 총합을 출력하세요
select userId, SUM(PRICE * AMOUNT) AS 총합
FROM BUYTBL
GROUP BY USERID;참고자료
https://velog.io/@ash3767/스키마란-무엇인가
https://goodgid.github.io/DB-char-vs-varchar/

개발기록