사건발단
k8s인프라 구성중에 haproxy와 pcsd를 설치했다.
이유는 vip를 사용하여 다중클러스터링에서
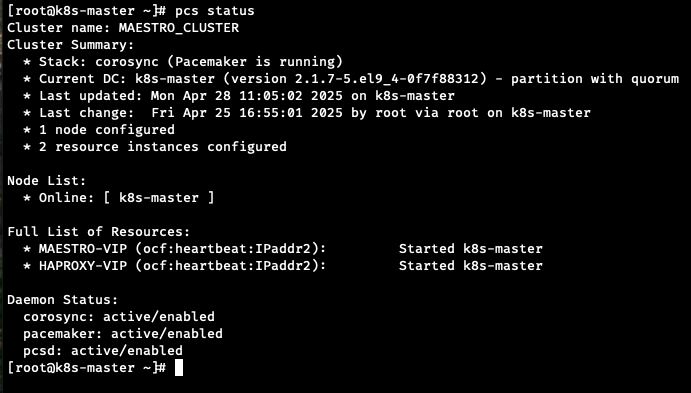
-
haproxy가 running일때
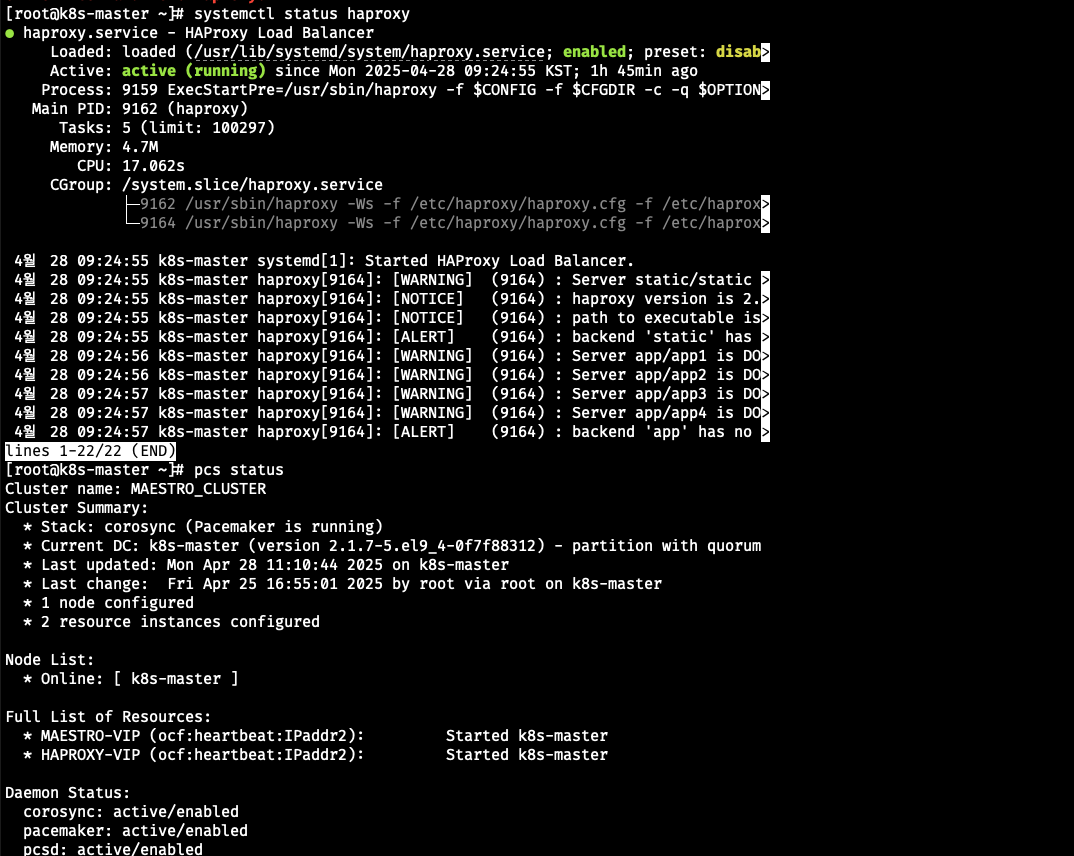
-
haproxy가 stop일때

나는 당연히 pacemaker가 health체크를 하고 해당 부분을 반영시키는 줄 알았음
haproxy를 systemctl stop haproxy로 멈추면 haproxy 서비스(프로세스)만 죽는 거야. 하지만 VIP 리소스는 여전히 살아 있어.
VIP(MAESTRO-VIP, HAPROXY-VIP)는 haproxy랑은 별개로 pacemaker가 관리하거든. VIP는 그냥 "IP주소를 이 서버에 붙여주는 것"이야. haproxy랑 직접 연결된 건 아님.
즉, haproxy 프로세스는 죽어도, pcs status 보면 VIP는 여전히 Started 상태로 있을 거야. 클러스터 입장에서는 VIP를 모니터링할 뿐, haproxy 프로세스를 모니터링하지는 않아.
haproxy 프로세스까지 모니터링하고 싶다면?
그냥 VIP 모니터링만 하면 haproxy 죽은 걸 감지 못하잖아?
그래서 haproxy 프로세스를 감시하는 리소스를 별도로 추가할 수도 있어.
예시: ocf:heartbeat:haproxy 에이전트 사용
pcs resource create HAPROXY ocf:heartbeat:haproxy op monitor interval=30s 이런 식으로 등록하면 돼.
이렇게 하면 haproxy 죽으면 자동 failover(다른 노드로 VIP 이동)도 가능해.
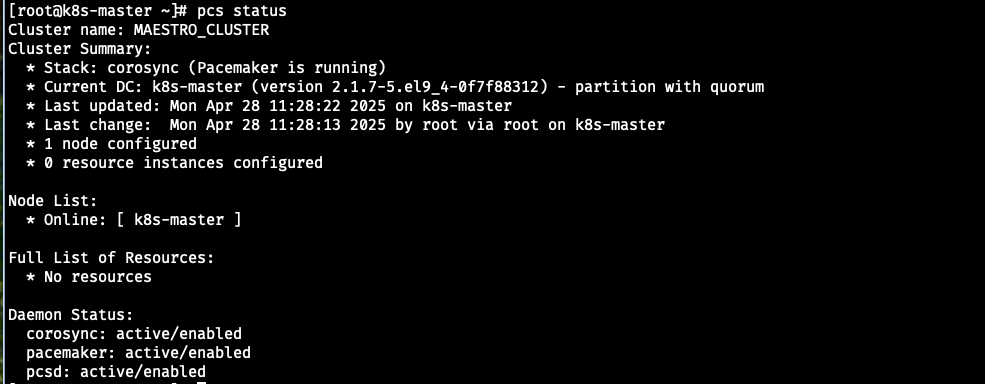
안전하게 vip를 삭제하는 법
[root@k8s-master ~]# pcs resource disable MAESTRO-VIP
[root@k8s-master ~]#
[root@k8s-master ~]# pcs resource delete MAESTRO-VIP
Removing Constraint - location-k8s-master-mavip
Deleting Resource - MAESTRO-VIP
[root@k8s-master ~]# pcs status
Cluster name: MAESTRO_CLUSTER
Cluster Summary:
* Stack: corosync (Pacemaker is running)
* Current DC: k8s-master (version 2.1.7-5.el9_4-0f7f88312) - partition with quorum
* Last updated: Mon Apr 28 11:27:05 2025 on k8s-master
* Last change: Mon Apr 28 11:20:57 2025 by root via root on k8s-master
* 1 node configured
* 1 resource instance configured
Node List:
* Online: [ k8s-master ]
Full List of Resources:
* HAPROXY-VIP (ocf:heartbeat:IPaddr2): Started k8s-master
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled안전하게 삭제됨!

개발기록