
개요
본격적으로 프로젝트 개발에 들어가기 전, 마지막으로 MongoDB에 대해 알아보고 MongoDB의 성격에 맞게 데이터를 모델링하는 시간을 가져보도록 하자.
MongoDB란?
MongoDB는 NoSQL, Docuemnt Database이다.
NoSQL이란?
NoSQL이란, 전통적인 RDBMS 모델을 따르지 않고 새로운 메커니즘을 사용하는 데이터베이스를 칭한다. NoSQL은 주로 테이블간 관계를 가지지 않으며 유연한 데이터 모델을 제공한다.
또한 RDBMS는 ACID 속성으로 인해 스케일아웃이 어려운데 반해 BASE 속성을 가지고 있어 대용량 데이터 처리와 스케일아웃 측면에서 유리하다.
Document Database란?
mongoDB는 JSON 형식으로 데이터를 관리하는 도큐먼트 데이터베이스로 분류된다. 도큐먼트는 필드와 값의 쌍으로 구성되며, 관계를 갖는 데이터를 중첩 도큐먼트와 배열을 사용하여 1개의 도큐먼트로 표현할 수 있다.
데이터 입출력 시에는 JSON 형식의 도큐먼트를 사용하고, 데이터베이스 저장 시에는 이진 포맷으로 인코딩한 BSON 형식의 도큐먼트로 변환되어 저장된다.
MongoDB 기본 용어
| MongoDB | MySQL | 설명 |
|---|---|---|
| Collection | Table | 동일한 타입의 문서(또는 BSON 객체)를 그룹화하는 컨테이너 |
| Document | Row | 데이터의 기본 단위, 키-값 쌍 또는 JSON 형식의 문서 |
| Field | Column | 문서의 속성 또는 키에 해당하는 데이터 |
MongoDB 모델링 전략
MongoDB는 스키마라는 개념이 없지만, 우리가 데이터를 활용하기 위해서 없지만 있는 것이라고 볼 수 있다. 그렇다면 MongoDB에서는 어떻게 데이터를 모델링할 수 있을까?
대표적으로 다음과 방법들을 사용한다.
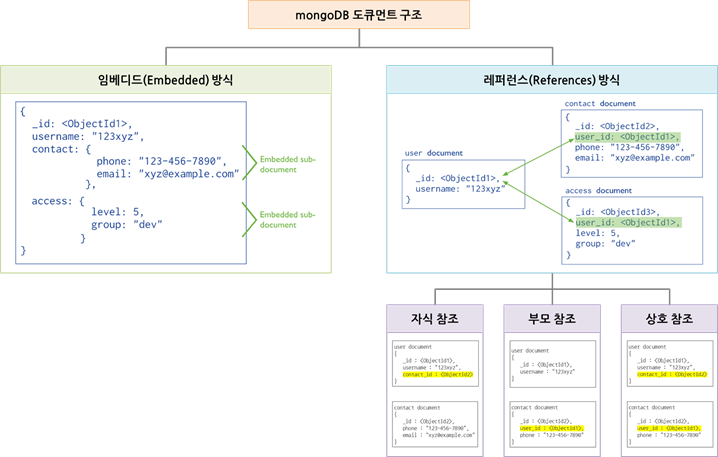
이미지 출처 : NHN Cloud - 김정민님, mongoDB Story 3: mongoDB 데이터 모델링
임베디드 방식 (Embedded)
임베디드 방식은 문서 내부에 다른 문서를 포함하는 방식이다.
장점
- 데이터를 하나의 문서로 저장하므로 읽기 속도가 빠르고 쿼리 성능이 향상된다.
- 한 번의 데이터베이스 조회로 모든 관련 정보를 얻을 수 있다.
단점
- 중복 데이터가 발생할 수 있으며, 데이터가 자주 변경될 경우 유지보수가 어려울 수 있.
- 문서의 크기가 커지면 쿼리 성능이 저하될 수 있다.
일방향 참조 방식
자식 참조 혹은 부모 참조로 나뉘지만 비슷한 접근 방법이라고 생각된다.
이 방식은 한 방향에서만 다른 컬렉션을 참조하는 방식이다. 마치 RDBMS에서의 FK를 활용하는 방식과 유사하다.
장점
- 데이터 정규화를 유지하므로 중복 데이터가 없다.
- 문서 간의 관계가 명확하게 유지된다.
단점
- 데이터베이스에서 참조된 문서를 가져오기 위해 추가적인 쿼리가 필요하다.
상호 참조 방식
상호 참조 방식은 두 문서가 서로를 참조하는 방식이다.
장점
- 관련된 데이터를 빠르게 검색하고 탐색할 수 있다.
- 문서 간의 관계가 명확하게 유지된다.
단점
- 순환 참조 및 데이터 정합성 문제가 발생할 수 있다.
- 임베디드 방식 만큼은 아니지만 데이터 수정이 복잡해질 수 있다.
데이터 모델링하기
앞서 살펴본 MongoDB의 특징과 모델링 전략을 통해서 각각 도메인에 적절한 데이터 모델링을 적용해 보도록 하자. 사용자 도메인은 인증 인가를 위한 최소한의 정보만 저장하여 독립된 서비스에서 관리할 예정이므로 설명을 생략하였다.
음악 데이터 모델링
서비스에서 가장 우선순위가 높은 음악부터 모델링을 해보도록 하자.
음악은 다음과 같은 요구사항을 가지고 있다고 가정하였다.
하나의 음악은 하나의 앨범에만 수록될 수 있으며 여러 명의 아티스트가 음악 발매에 참여할 수 있다. 상세 크레딧 정보는 구현하지 않는다.
음악은 아티스트와 앨범 정보를 함께 가지고 있으며, 결합도가 굉장히 높다. 그렇다면 음악에 아티스트와 앨범 정보를 모두 포함한 Embedded 방식으로 모델링을 하는 것은 어떨까?
music Collection은 다음과 같은 데이터 형식을 가지게 될 것이다.
{
_id : ...
name: ...
...
album: { ... }
artists: [
{ ... },
{ ... }
]
}위와 같이 모델링을 하게 된다면, 다음과 같은 화면을 구성하기는 좋을 것이다.
노래 목록을 조회할 때, 앨범과 아티스트 정보가 흩어져있지 않기 때문에 다른 컬렉션을 추가로 조회할 필요가 없다.
하지만 앨범을 검색을 하는 기능을 구현해야 한다면? 아티스트의 모든 앨범과 노래 정보를 조회하고 싶다면?
이러한 시나리오를 생각하면 각각의 embedded 문서에도 id를 부여하고 굉장히 많은 필드에 Index를 부여해야 하며 앨범이나 아티스트의 정보가 변경되는 일이 적다고 해도 데이터 정합성을 관리하는데 굉장히 큰 어려움이 있을 것이다.
MongoDB의 비정규화를 통한 이점은 적절히 활용하면서 데이터 정합성 관리에 필요한 비용도 타협하려면 다음과 같이 모델링을 하는 것이 더 좋아보인다고 생각하였다.
음악
음악은 주로 앨범 이름과 아티스트 이름 정보를 포함하여 화면에 표시된다. 따라서 부분적으로 embedded 방식을 채택하였다.
즉, 음악은 음악 본질적인 정보와 아티스트 목록(id, 이름), 앨범(id, 이름) 정보를 embedded 하는 것으로 결정하였다.
앨범
앨범은 목록 페이지에서는 앨범 정보와 아티스트들의 정보가 보여진다. 상세 페이지에서는 앨범에 수록된 모든 노래 목록이 표시된다.
하나의 앨범에 한 명의 아티스트만 참여하는 경우도 많지만 다음과 같이 여러 아티스트가 참여하는 경우도 있다.
앨범에 노래 정보를 저장해야 할 지, 음악을 앨범 레퍼런스로 검색을 해야할 지 고민되었다. 음악을 앨범 레퍼런스로 검색하려면 앨범 레퍼런스 필드에 index를 추가하거나 검색 성능과의 트레이드 오프를 피할 수 없다.
하지만 index를 추가하는 것은 RAM 공간까지도 영향을 주기 때문에 가능한 꼭 필요한 필드에만 하는 것이 좋다고 생각했다. (참고: Medium - Chanjoo Lee, MongoDB의 index, 그냥 생성해도 될까?) 또한 하나의 앨범에 MongoDB에 최대 도큐먼트 크기를 초과할 만큼 많은 music 레퍼런스가 포함 될 것이라고 생각되지 않았다. 아티스트 정보 또한 도큐먼트 크기에 큰 영향을 줄 정도는 아니라고 생각했다.
결론적으로, 앨범에는 music의 레퍼런스 목록과 artist의 id, 이름 정보를 embedded 하는 방식으로 결정하였다.
아티스트
아티스트는 목록페이지에 아티스트 자체적인 정보 외에는 표시되는 것이 없다. 상세페이지에서는 아티스트의 음악 목록과 앨범 목록을 보여줄 수 있어야 한다.
따라서 앨범을 모델링 하는 것과 같은 논리로 아티스트 소유의 music의 레퍼런스 목록과 artist의 레퍼런스 목록을 참조하는 것으로 결정하였다.
CUD(저장) 구현은 어떻게?
해당 프로젝트에서 음악 도메인의 경우 조회 기능을 구현하는 것이 주 된 목표이기 때문에 실제 스포티파이가 어떻게 음악을 서비스에 등록하는지, 자동화하는지 구체적으로 생각해보지는 않았다.
그렇다고 하더라도, 비정규화한 데이터의 정합성을 유지하면서 CUD 하는 작업에 대해서는 깊이 있게 생각해볼만하다.
CUD 시나리오
아티스트와 앨범을 저장할 때에는 참조 필드에 대한 정보를 입력하지 않는다. 음악 정보를 저장할 때 어떤 앨범에 수록되었는지, 어떤 아티스트가 참여하였는지에 대한 레퍼런스를 함께 저장하도록 한다.
음악 정보를 저장할 때 관련된 아티스트의 앨범과 노래 정보를 업데이트해줘야 하며, 앨범의 아티스트와 노래 정보를 업데이트해줘야 한다.
단 세 개의 컬렉션이 비정규화되어 서로의 정보를 조금씩 참조하고 있을 뿐인데, 하나의 저장 작업을 하는데 굉장히 많은 비용이 든다. 여기서 앨범이나 아티스트 이름이 변경된다거나 기타 다른 수정, 삭제 작업을 구현하려면 이 또한 굉장히 많은 작업을 해야 할 것이다. 실수로 새로운 요구사항을 구현하는 중에 작업을 하나라도 빠뜨리면 데이터 정합성에 큰 문제가 생길 수 있다는 문제가 발생한다.
비정규화 모델링에서 데이터 정합성에 대한 문제는 당연한 것이다. 하지만, 내가 생각했던 것보다 CUD 작업에서의 비용이 더 크고 리스크가 많다고 생각되었다. 이를 해결할 수 있는 방법을 생각하던 중 CQRS 패턴에 대해 알게되었다.
우선은 MongoDB로 저장 기능만 구현한 뒤 추후에 정규화 모델의 MySQL과 비정규화 모델의 MongoDB를 동시에 사용하여 데이터의 정합성을 지키며 조회 성능 및 스케일아웃의 장점을 모두 가져갈 수 있도록 구현하는 것을 계획하게 되었다.
음악 ERD (CQRS 미적용)
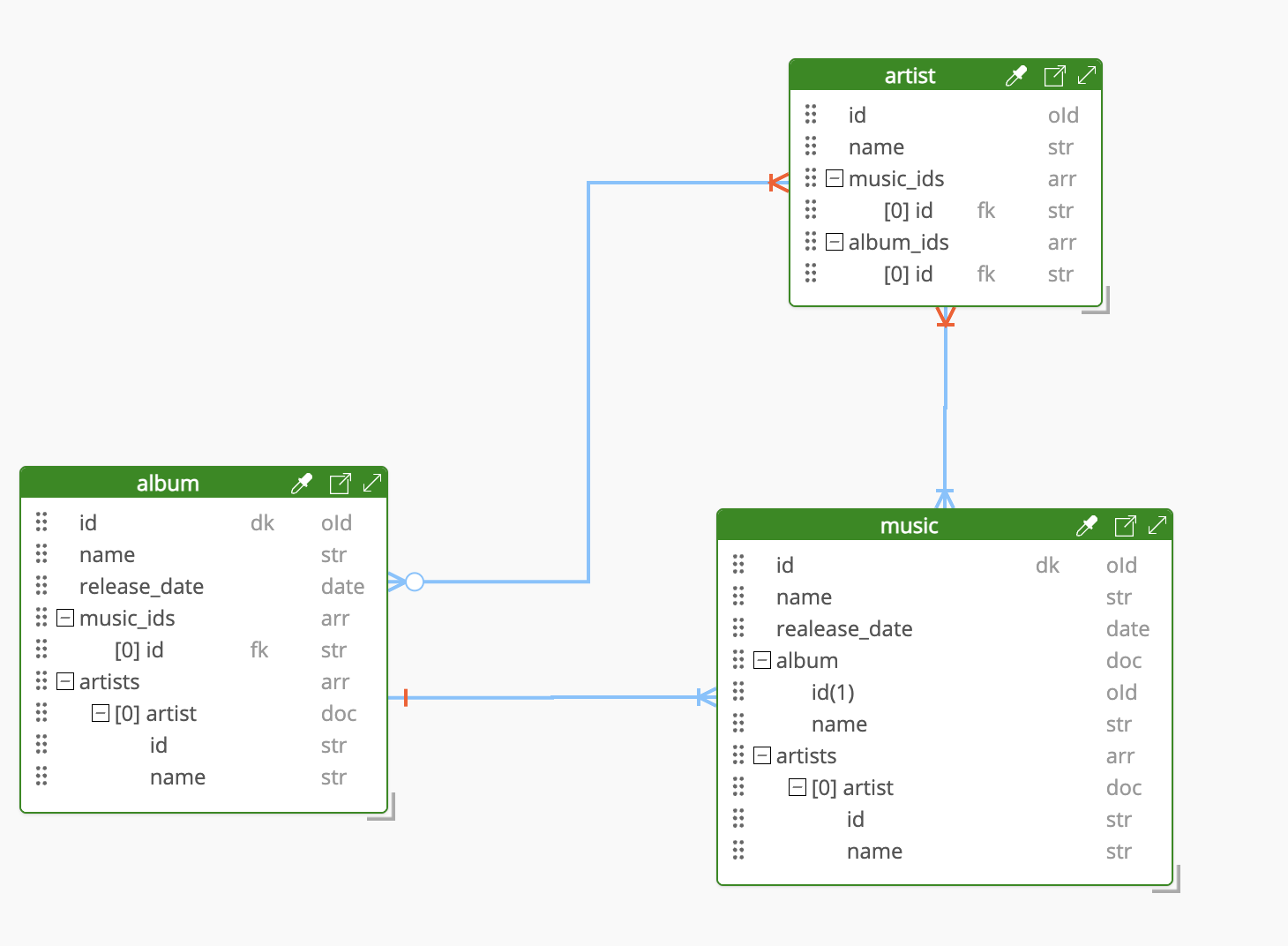
라이브러리 데이터 모델링
라이브러리는 플레이리스트, 플레이리스트 폴더, 아티스트, 앨범, 음악을 저장하고 관리할 수 있는 구조이다.
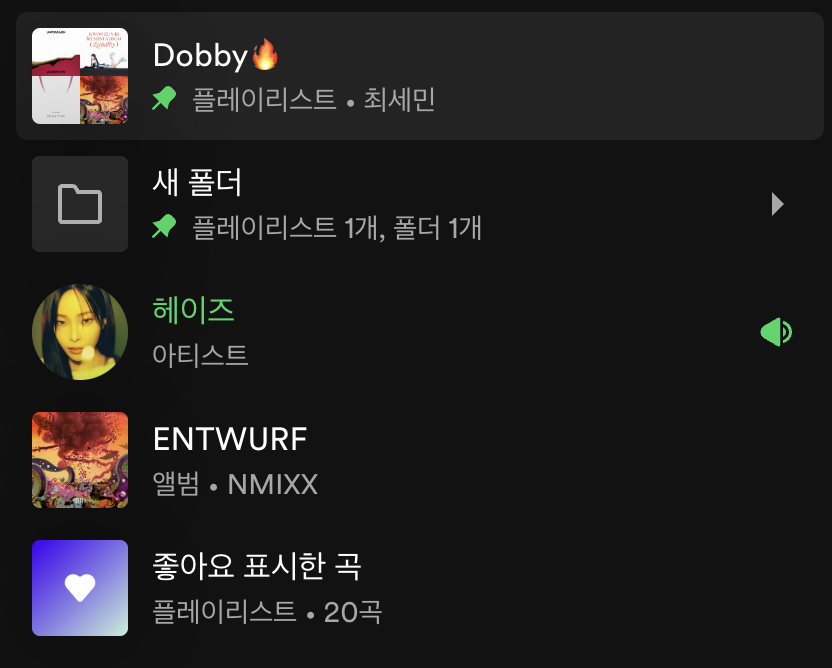
플레이리스트는 노래를 포함하며, 폴더는 또 다른 폴더나 플레이리스트를 포함할 수 있다. 마치 Tree 혹은 Composite 패턴과 같은 구조로 이루어져 있는 것이다.
Tree를 저장하고 관리하는 다양한 패턴을 공식 문서에서 제시하고 있었다.
라이브러리의 특징은 자식 노드를 빠르게 탐색할 수 있어야 하며, 리프 노드의 부모도 즉각적으로 확인할 수 있어야 한다.
여기서의 리프 노드는 더이상 child을 가질 수 없는 음악, 앨범, 아티스트 등의 요소 의미한다. 리프 노드의 부모를 빠르게 탐색할 수 있어야 하는 이유는 다음 기능때문이다.
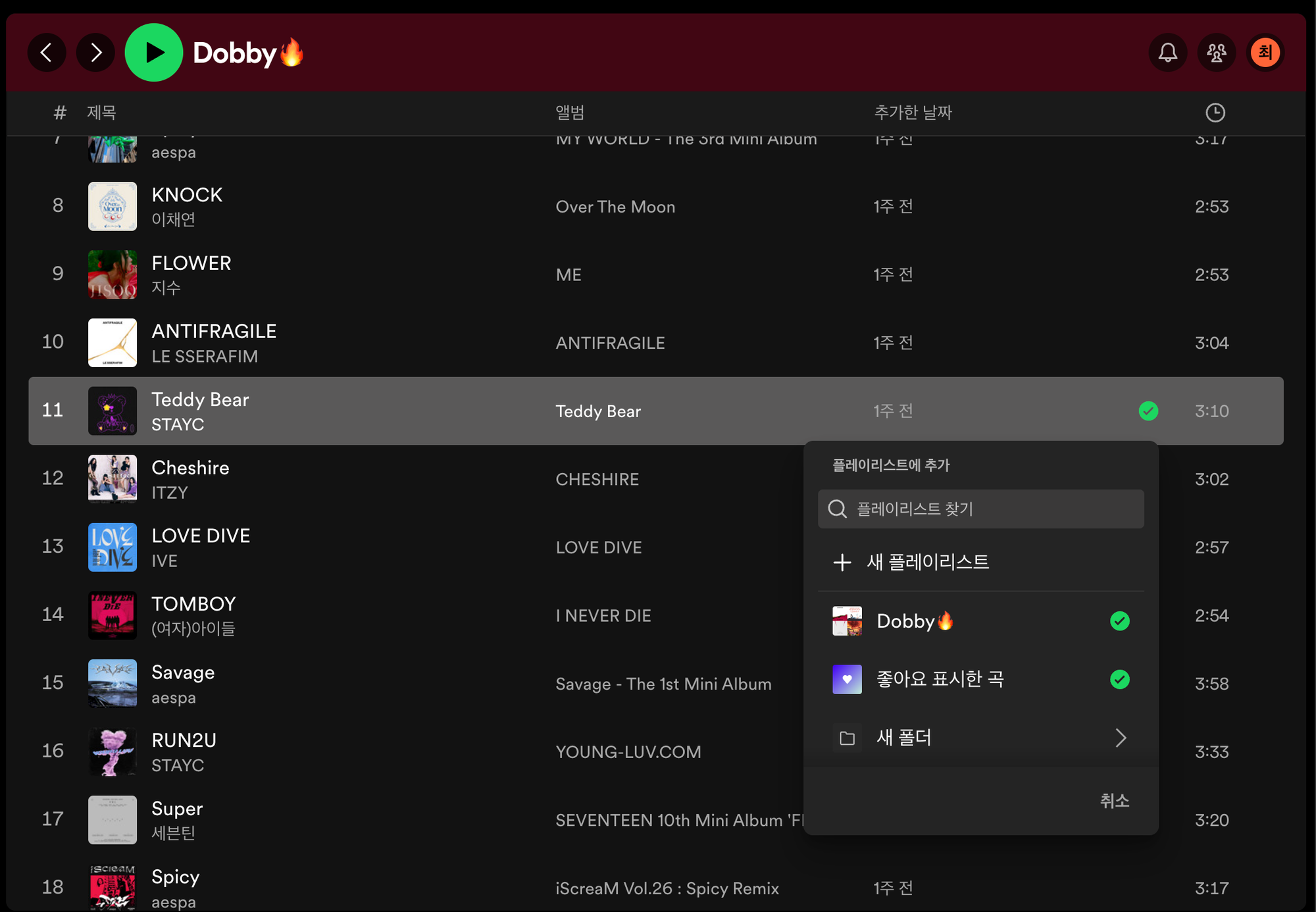
각 요소(리프 노드)에 좋아요를 눌렀는지, 노래의 경우 어떤 플레이리스트(부모 노드)에 추가되어 있는지 빠르게 확인할 수 있어야 하기 때문이다.
그래서 Model Tree Structures with Child References 방식과 Model Tree Structures with Parent References 방식을 혼합해서 사용하는 것으로 결정했다.
라이브러리 컬렉션 다이어그램
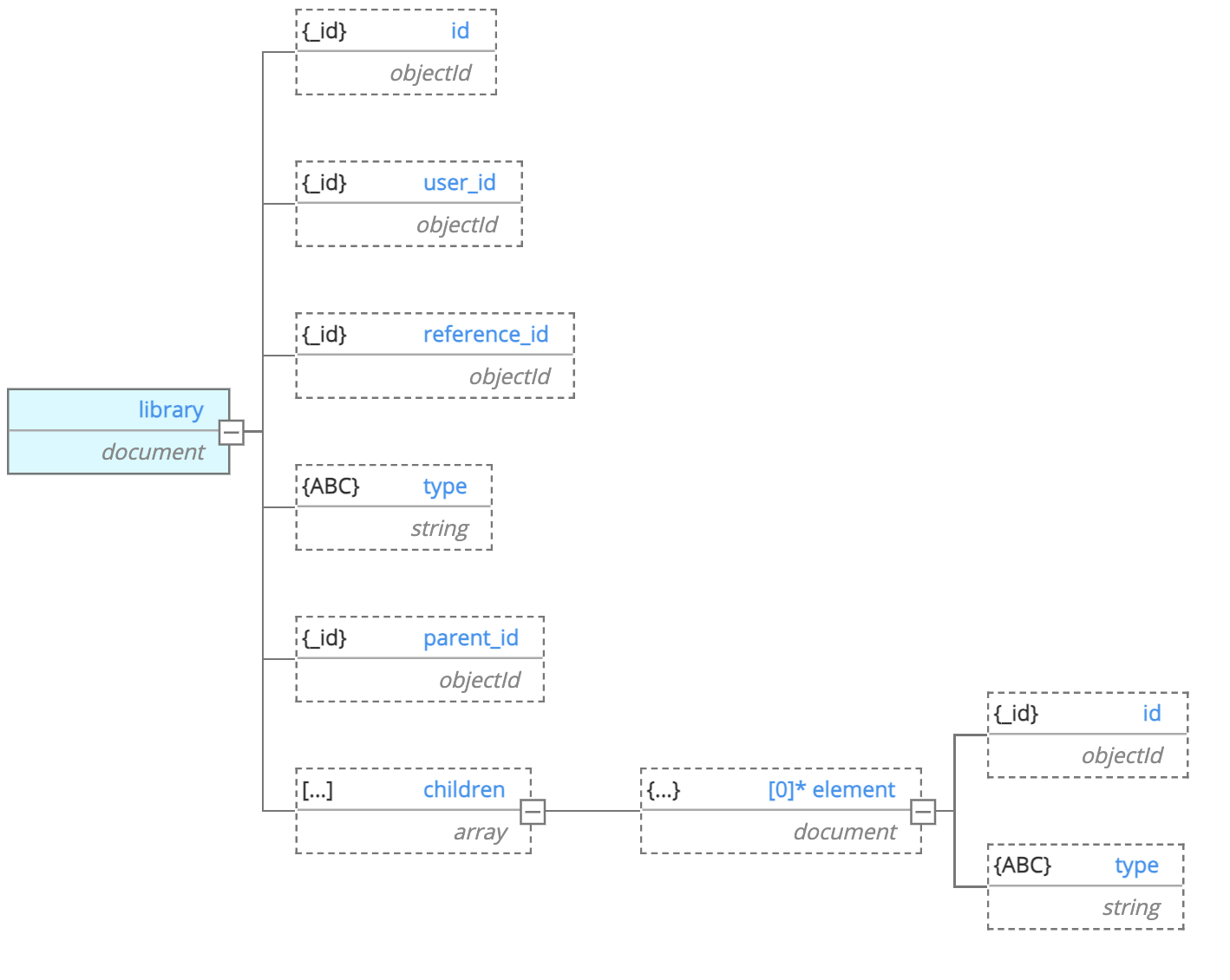
id와 uesr_id 필드를 Compound Index 로 사용하여 사용자별로 라이브러리를 빠르게 조회할 수 있도록 필드를 추가하였다.
또한, 폴더나 플레이리스트일 경우 하위의 어떤 요소가 몇 개 씩 있는지 자식 노드를 조회하지 않고 확인할 수 있도록 설계하였다.
추가로 노드의 타입이 음악, 앨범, 아티스트인 경우는 children 필드가 존재할 필요가 없으며 별도의 reference_id를 가지고 있어야 한다.
플레이리스트는 제작자, 플리 이름 플레이리스트 폴더는 폴더 이름 등의 정보가 포함되어야 한다.
이러한 노드의 다양성은 Composite 패턴을 활용해 스프링 도메인 레이어에서 처리할 예정이다.
마무리하며
MongoDB를 활용해 데이터 모델링을 하는 것은 처음인데 RDBMS보다 훨씬 자유로워서 특정 요구사항에 유리하게 모델링 할 수 있는 점이 좋았다. 하지만, 자유로움에서 오는 책임도 작지 않은듯 하다. 특히 비정규화로 인한 데이터 정합성 관리는 굉장히 신경 쓸 부분이 많고 조심스러운 부분이라고 생각되었다.
참고 문서
