js 기반의 인공지능 라이브러리를 쓴다고? face-api.js로 얼굴 인식 및 분류하기(face recognition and classification)

js 기반의 인공지능 라이브러리를 사용한다고? 존재하긴 해?
처음 얼굴인식을 위한 라이브러리를 찾던 중, js 기반의 라이브러리를 사용하겠다고 말했을 때 주변인들로부터 가장 많이 들은 말이다. 나 역시도 혹시나 하는 마음에 찾아봤을 뿐 쓸만한 정보를 기대하진 않았다.
현재 수강중인 캡스톤디자인프로젝트, 이하 컴퓨터공학과 졸업프로젝트에서 내가 속한 팀은 네컷사진 아카이빙 서비스 '모음'을 런칭하고자한다. 모음은 react js와 node js 기반의 서비스이며, 나는 그 중 기술 구현과 백엔드 파트를 맡아 진행 중이다. 기술 구현에 이용되는 대부분의 인공지능 라이브러리들은 파이썬 기반이라고 익히 들어 알고 있었기에 기술에 관한 구글링을 진행하기 이전부터
"node js에서 파이썬 코드 사용하기"
"javascript에서 python 코드 사용"
"js에서 python 라이브러리 사용하기"
등과 같은 문장들이 최근 검색어란을 꽉 채웠다.
js에서 어떻게 파이썬 라이브러리를 설치하고 돌리나 걱정하던 와중, 너무나 다행히도 끝없는 구글링 끝에 javascript 기반의 얼굴 인식 라이브러리를 찾을 수 있었다.
꽤나 다양한 얼굴 인식 라이브러리들이 존재했는데, 그 중 내가 선택한 라이브러리는 face-api.js이다.
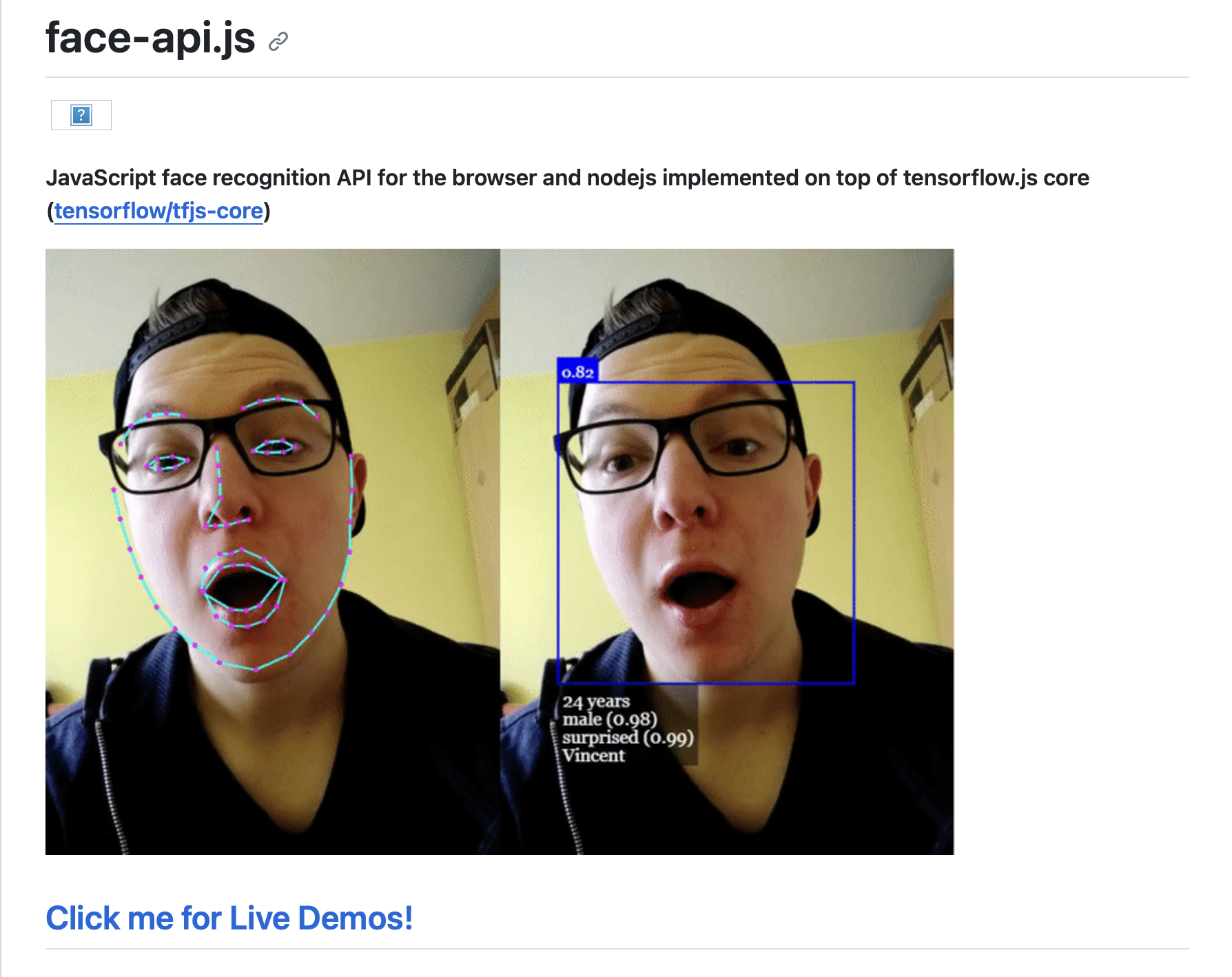 GitHub Link
GitHub Link
해당 라이브러리를 선택한 이유는 다음과 같다.
첫째로, 꽤나 직관적인 사용법에 높은 정확도를 보여줬으며 둘째로, 네컷사진 아카이빙이라는 서비스 특성상, 인식하고자 하는 인물의 사진이 한 장만 저장되어 있더라도 명확히 인물 분류가 가능해야 하는데 이 조건을 만족하는 몇 안되는 선택지 였다. 두번째 이유를 고려하며 선택지가 확 줄은 것은 사실이나 이와 별개로 좋은 퍼포먼스를 보여주며 사용하기 편리한 라이브러리인 것도 사실이다. 사진 하단에 깃허브 링크를 함께 첨부해두었다.
백엔드 단에서 돌려보는 방법을 소개한다면 더욱 좋겠지만 간단한 튜토리얼을 소개하는 포스트이므로, 조금 더 간단하게 따라해볼 수 있는 프론트로 해당 라이브러리를 돌려보는 방법을 소개하려 한다.
시작하기 전
본격적으로 시작하기에 앞서, 이 글은 react를 베이스로 한 튜토리얼이다. 'npx create-react-app'과 같이 react app 생성부터를 가르쳐주는 튜토리얼이 아니라 'javascript 기반의 얼굴 인식 라이브러리 사용하기'에 중점을 두고 설명하고자 한다.
우선, 다음과 같이 작업하고자 하는 위치의 디렉토리를 설정해두자. 해당 라이브러리의 경우 npm으로 설치할 수도 있지만 나는 깃허브에서 직접 파일을 가져와 사용하고자 한다. 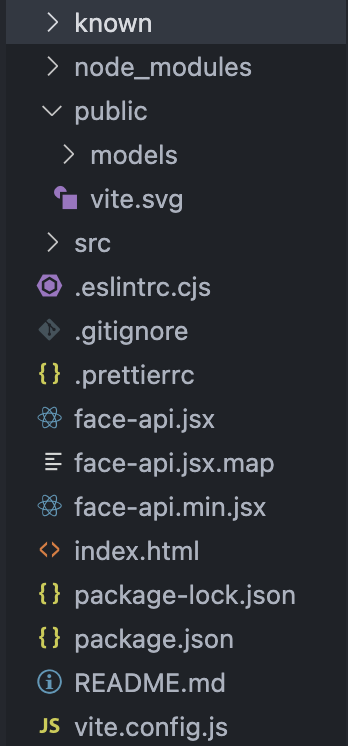
'known'은 얼굴을 인식하고자 하는 인물의 사진을 넣어둔 폴더이다.이때 한 인물 당 한 장의 사진만 들어있으면 된다. 나같은 경우엔 '박명수.jpeg'와 '유재석.jpeg', 총 두 장의 사진을 넣어두었다.
'src' 폴더 내부의 'models' 디렉토리 역시 해당 라이브러리를 적용하기 위하여 따로 추가한 폴더인데, 글 상단에 걸어둔 깃허브 링크의 'weights' 폴더를 그대로 다운받아서 넣어주었다.
디렉토리의 가장 바깥에 'face-api.js'파일도 넣어주자. 나의 경우엔 vite를 사용하기에 모두 .jsx 확장자를 사용하고 있는데, 확장자가 .js이어도 상관 없으니 편한대로 이용해주면 되겠다. 해당 파일 역시 깃허브에서 다운 받을 수 있다.
<script type="module" src="face-api.jsx"></script>마지막으로, 위와 같은 코드를 디렉토리 가장 바깥에 존재하는 index.html 파일에 적어주면 가장 기본적인 세팅은 끝이 난다. 야호!
js 파일에서 코드 작성하기
모델 불러오기
이제 디렉토리 내부에 본인이 원하는 곳에 js 파일을 생성하여, 혹은 이미 존재하는 js 파일에 덧붙여 아래의 튜토리얼을 따라하면 되겠다.
useEffect 함수를 하나 만들고 내부에 아래와 같은 코드를 작성해주자.
useEffect(() => {
async function loadModels() {
await Promise.all([
faceapi.nets.faceRecognitionNet.loadFromUri('/models'),
faceapi.nets.ssdMobilenetv1.loadFromUri('/models'),
faceapi.nets.faceLandmark68Net.loadFromUri('/models'),
]);
}이 코드는 face-api 라이브러리를 사용하기 위한 가장 필수적인 코드이다. 각 모델은 loadFromUri 함수를 통해 지정된 경로(/models)에서 비동기적으로 로드되며, 이렇게 모델을 미리 로드해 두면 이후에 실제로 얼굴을 감지하거나 인식하는 작업을 수행할 때 더 빠르게 사용할 수 있다. 더불어, 이 loadModels 함수는 useEffect 안에서 호출되어 컴포넌트가 렌더링되거나 업데이트될 때 한 번만 모델을 로드한다.
async function start() {
// loadLabeledImage 함수를 호출하여 labeledFaceDescriptors 설정
const labeledFaceDescriptors = await loadLabeledImage();
setLabeledFaceDescriptors(labeledFaceDescriptors);
// FaceMatcher 초기화
const faceMatcher = new faceapi.FaceMatcher(labeledFaceDescriptors, 0.4);
setFaceMatcher(faceMatcher);
setLoaded(true);
}위 코드 역시 useEffect 함수 내부에 적어주자. loadLabeledImage 함수를 호출하여 얼굴에 대한 레이블링된 디스크립터를 가져와 setLabeledFaceDescriptors를 통해 상태에 설정한다. 그 후, 이 디스크립터를 사용하여 FaceMatcher를 초기화하고, setFaceMatcher 및 setLoaded 함수를 통해 상태를 업데이트하기 위한 함수이다. 말이 조금 복잡해보여도 라이브러리를 사용하기 위한 준비 단계이니, 복붙해주자!
async function loadModelsAndStart() {
await loadModels(); // 모델 로딩
await start(); // 모델 로딩 후 실행
setLoaded(true);
}
loadModelsAndStart();loadModels와 start를 순차적으로 호출하여 얼굴 인식 모델을 로드하고 초기화한다. 위 코드까지 useEffect 함수 내부에 적은 후, 함수를 닫아주자!
자, 이번엔 두번째 useEffect문이 필요하다.
const [loaded, setLoaded] = useState(false);
useEffect(() => {
if (loaded) {
handleImageChange({ target: { files: [location.state.img] } });
}
}, [loaded, location.state.img]);loaded가 true이면서 location.state.img가 변경될 때마다 handleImageChange 함수가 호출되게 하는 함수이다. handleImageChange함수도 함께 작성해볼까?
이미지 불러오기
const selectedImageObjRef = useRef(null);
const handleImageChange = async (event) => {
const image = new Image(); // 새로운 이미지 객체 생성
selectedImageObjRef.current = event.target.files[0];
image.src = URL.createObjectURL(selectedImageObjRef.current);
}handleImageChange는 이번 튜토리얼에서 가~장 중요한 함수이다. 우선 사진 받기부터 시작해보자. 나의 경우엔, 이전 페이지에서 input 태그를 이용하여 사진을 받아왔다. 여기서 문제가 발생한다. 사진이 항상 바로바로 업로드 되는 것은 아니다. 용량과 크기에 따라 한참 걸리는 사진들도 존재한다. 이러한 경우를 위해 async-await 문법을 이용한 사진 로딩 함수를 아래에 작성해주자.
//이미지 로드가 완료될 때까지
image.onload = async () => {}handleImageChange 함수의 대부분의 내용은 image.onload 내부에 들어간다. 이미지 로드가 완료될 때까지 무얼 먼저 해주어야 할까?
캔버스 그리기
const canvas = faceapi.createCanvasFromMedia(image);
FaceContainer.current.appendChild(canvas);
const ctx = canvas.getContext('2d');
canvas.width = image.width;
canvas.height = image.height;
ctx.drawImage(image, 0, 0, image.width, image.height);
const displaySize = {
width: 350,
height: 350 / (image.width / image.height),
};
faceapi.matchDimensions(canvas, displaySize);바로 canvas 생성해주기이다. 우리는 사진 위에 얼굴 인식 결과를 나타내주기 위하여 사각형과 label을 출력해줄건데, 이를 위해 canvas 태그를 사용하려고 한다.
우선 faceapi 라이브러리에서 제공되는 createCanvasFromMedia 함수를 사용하여 새로운 캔버스 엘리먼트를 생성하고 이미지 위에 캔버스를 얹는다. 이렇게 생성된 캔버스를 그려주고자 하는 컴포넌트에 추가해주면 되는데, 나의 경우엔 'FaceContainer'라는 이름의 항목에 추가해주었다.
<PictureContainer>
<img
src={URL.createObjectURL(location.state.img)}
style={{ position: 'relative', width: 350 }}
alt="선택한 이미지"
/>
<div
style={{
position: 'absolute',
top: 0,
}}
ref={FaceContainer}
/>
</PictureContainer>위와 같이 img와 canvas가 들어갈 태그를 병렬적으로 작성해주었으며, useRef를 사용하여 canvas를 참조하고 있다.(canvas 내부에 그려진 값이 변경될 때마다 이 값을 참조하기 위하여 useRef를 사용했다.)
다시 작성하던 코드로 돌아와서 이야기해보자. 그림을 그리기 위한 2d 그래픽 context를 불러와 주고, 원하는 displaySize를 설정해주면 된다. 이미지와 동일한 크기여야 정확히 얼굴이 있는 부분에 사각형을 그려줄 수 있으므로 캔버스의 크기를 이미지와 동일하게 설정한다.
얼굴 감지 및 인식
const detections = await faceapi
.detectAllFaces(image)
.withFaceLandmarks()
.withFaceDescriptors();
results = await Promise.all(
detections.map((d) => faceMatcher.findBestMatch(d.descriptor)),
);전반적인 코드에서 가장 핵심역할을 하는 부분이다.
detections : 이미지에서 얼굴을 감지하고 얼굴 특징 및 기술자(descriptors)를 얻는 작업을 수행
detections에서 faceapi를 사용하여 이미지에서 모든 얼굴을 감지하고, 얼굴의 랜드마크(face landmarks)와 얼굴의 기술자(face descriptors)를 추출한다. detectAllFaces는 이미지에서 모든 얼굴을 감지하고, withFaceLandmarks는 각 얼굴의 랜드마크를 제공하며, withFaceDescriptors는 각 얼굴에 대한 기술자를 제공하는 함수이다.
results : 얼굴 매칭(face matching)을 통해 각 얼굴에 대한 가장 적절한 일치 결과 탐색
results에는 detections에서 얻은 descriptors를 사용하여 얼굴 매칭을 수행한다. faceMatcher 객체를 사용하여 각 얼굴의 기술자를 비교하고, findBestMatch를 통해 각 얼굴에 대한 가장 적절한 일치 결과를 찾아 results 배열에 저장한다.
인식한 얼굴 화면에 그리기
이제 가장 마지막 단계이다!
const resizedDetections = faceapi.resizeResults(detections, displaySize);resizeResults 함수를 통해 감지된 얼굴 정보를 새로운 크기에 맞게 조정한다. 이미지 크기와 표시 크기가 서로 다를 때 얼굴 감지 결과를 알맞은 비율로 조정하기 위해 필수적인 코드이다. 크기가 조정된 얼굴 감지 정보가 반환되어 resizedDetections에 저장된다.
results.forEach((result, i) => {
const box = resizedDetections[i].detection.box;
const drawBox = new faceapi.draw.DrawBox(box, {
label: result.toString(),
});
drawBox.draw(canvas);results 배열을 순회하면서 각 얼굴에 대한 정보를 가져와야 한다.
resizedDetections 배열 내부에는 크기가 조정된 얼굴 감지 정보가 담겨져있다. detection.box는 해당 얼굴의 경계 상자(box)를 나타내며 이 정보를 box에 저장해주자. box값과 얼굴에 대한 매칭 결과를 문자열로 변환한 label 값을 DrawBox 함수에 인자값으로 입력해주어 얼굴 주변에 상자를 그린다.
마지막으로 'drawBox.draw(canvas)'를 사용하여 DrawBox의 상자들을 실제로 canvas 위에 그려준다. 야호!
저장된 인물 label 생성하기
끝이 났다는 생각에 신이 나지만, 아직 완전히 끝이 난게 아니다. 초반에 디렉토리 목록을 보여주며 인식할 인물의 얼굴 사진을 넣어둔 'known' 폴더를 기억하는가? start()함수에서 사용했던 loadLabeledImage 함수가 기억이 나는가?! 우리는 아직 해당 데이터로 label을 생성하는 함수인 loadLabeldImage()를 작성하지 않았다! 빠르게 해당 부분을 짚고 넘어가보자.
async function loadLabeledImage() {
const labels = ['박명수', '유재석'];
return Promise.all(
labels.map(async (label) => {
const description = [];
const img = await faceapi.fetchImage(`known/${label}.jpeg`);
const detections = await faceapi
.detectSingleFace(img)
.withFaceLandmarks()
.withFaceDescriptor();
description.push(detections.descriptor);
return new faceapi.LabeledFaceDescriptors(label, description);
}),
);
}이 비동기 함수는 주어진 레이블에 대한 이미지를 로드하고, 해당 이미지에서 얼굴을 감지하며 얼굴 특징을 추출하는 역할을 수행한다. 이렇게 추출된 얼굴 특징은 faceapi.LabeledFaceDescriptors 객체를 생성하여 해당 레이블과 함께 return 값으로 반환된다.
labels 배열에는 knowns 폴더에 넣어둔 인물들의 이름을 작성해주었다. 조금 더 고도화된 작업을 위해서는 폴더 내부에 있는 파일명을 가져와 배열로 생성하는 것을 추천한다.
Promise.all은 비동기 작업을 병렬로 처리하는데 사용된다. map 함수를 사용하여 각 레이블에 대한 비동기 작업을 생성하고, Promise.all은 모든 비동기 작업이 완료될 때까지 기다리는 역할을 한다. faceapi.fetchImage를 사용하여 known 폴더에서 해당 레이블에 대한 이미지를 가져온다. 이때 원하는 확장자명을 작성해주면 된다.
detectSingleFace 메서드를 사용하여 이미지에서 얼굴을 감지하고, withFaceLandmarks 및 withFaceDescriptor를 사용하여 얼굴의 랜드마크와 기술자를 추출 할 수 있다. 얼굴의 기술자를 description 배열에 추가하고, 각 레이블에 대한 LabeledFaceDescriptors 객체를 생성하여 반환한다.
끝!
결과 화면
위 코드를 모두 취합하여 입맛에 맞게 여러 기능을 추가한 후 실행한 결과화면이다.

인식하고자 했던 유재석, 박명수의 얼굴이 정확히 인식되었고, known 폴더에 저장되어 있지 않은 정준하의 경우 unknown으로 인식되었다. 야호!
이렇게 성공적으로 face-api.js를 사용할 수 있다. 아래에 사용한 전체 코드를 함께 첨부해두었으니 전반적인 플로우를 확인하면 좋을 것 같다.
끝!
import React, { useState, useEffect, useRef } from 'react';
import { useNavigate, useLocation } from 'react-router-dom';
import styled from 'styled-components';
import BackgroundContainer from '../Components/BackgroundContainer';
import {
Content,
Question,
Upper,
Num,
Down,
PictureContainer,
Pic,
FaceBox,
BtnContainer,
YesBtn,
NoBtn,
} from '../Components/NumofPeople';
import { NavBar } from '../Components/NavBar';
import LoadingScreen from './Loading';
const NumofPp = () => {
const location = useLocation();
const [selectedImage, setSelectedImage] = useState(null);
const FaceContainer = useRef(null);
const rectanglesRef = useRef([]);
const resizedDetectionsRef = useRef([]);
const selectedImageObjRef = useRef(null);
const checkCanvasRef = useRef(null);
const [loaded, setLoaded] = useState(false);
const [labeledFaceDescriptors, setLabeledFaceDescriptors] = useState([]);
const [faceMatcher, setFaceMatcher] = useState(null);
const [selectedFace, setSelectedFace] = useState(null);
const [isLoading, setIsLoading] = useState(true);
const navigate = useNavigate();
const handleFaceClick = async (selectedFace) => {
setSelectedFace(selectedFace);
const { x, y, width, height } = selectedFace.detection.box;
// 이미지를 로드하는 Promise를 생성
const loadImage = (src) => {
return new Promise((resolve) => {
const img = new Image();
img.onload = () => resolve(img);
img.src = src;
});
};
// 이미지를 로드하여 기다림
const img = await loadImage(
URL.createObjectURL(selectedImageObjRef.current),
);
// 기준이 되는 displaySize
const displaySize = {
width: 350,
height: 350 / (img.width / img.height),
};
// 이미지의 크기에 비례하여 x, y, width, height 값을 조정
const adjustedX = (x / displaySize.width) * img.width;
const adjustedY = (y / displaySize.height) * img.height;
const adjustedWidth = (width / displaySize.width) * img.width;
const adjustedHeight = (height / displaySize.height) * img.height;
const croppedFaceCanvas = document.createElement('canvas');
croppedFaceCanvas.width = adjustedWidth;
croppedFaceCanvas.height = adjustedHeight;
const croppedFaceCtx = croppedFaceCanvas.getContext('2d');
// 이미지를 클릭한 부분을 기준으로 잘라내기
croppedFaceCtx.drawImage(
img,
adjustedX,
adjustedY,
adjustedWidth,
adjustedHeight,
0,
0,
adjustedWidth,
adjustedHeight,
);
// 잘라낸 이미지의 데이터 URL 생성
const croppedFaceDataURL = croppedFaceCanvas.toDataURL('image/jpeg');
const imgURL = URL.createObjectURL(selectedImageObjRef.current);
if (!selectedFace.label.includes('unknown')) {
const parts = selectedFace.label.split(' '); // 공백을 기준으로 문자열을 나눔
const label = parts[0]; // 나눠진 첫 번째 부분이 레이블
navigate('/faceclassification3', {
state: {
img: croppedFaceDataURL,
name: label,
wholeImg: imgURL,
selectedFace: selectedFace,
canvasData: checkCanvasRef.current.toDataURL('image/jpeg'),
},
});
} else {
navigate('/faceclassification2', {
state: {
img: croppedFaceDataURL,
wholeImg: imgURL,
selectedFace: selectedFace,
canvasData: checkCanvasRef.current.toDataURL('image/jpeg'),
},
});
}
};
const handleImageSelect = (image) => {
setSelectedImage(image);
};
const moveFunc = () => {
navigate('/faceclassification2');
};
useEffect(() => {
async function loadModels() {
await Promise.all([
faceapi.nets.faceRecognitionNet.loadFromUri('/models'),
faceapi.nets.ssdMobilenetv1.loadFromUri('/models'),
faceapi.nets.faceLandmark68Net.loadFromUri('/models'),
]);
}
async function start() {
// loadLabeledImage 함수를 호출하여 labeledFaceDescriptors 설정
const labeledFaceDescriptors = await loadLabeledImage();
setLabeledFaceDescriptors(labeledFaceDescriptors);
// FaceMatcher 초기화
const faceMatcher = new faceapi.FaceMatcher(labeledFaceDescriptors, 0.4);
setFaceMatcher(faceMatcher);
setLoaded(true);
}
async function loadModelsAndStart() {
await loadModels(); // 모델 로딩
await start(); // 모델 로딩 후 실행
setLoaded(true);
}
loadModelsAndStart();
}, []);
useEffect(() => {
if (loaded) {
handleImageChange({ target: { files: [location.state.img] } });
}
}, [loaded, location.state.img]);
const handleImageChange = async (event) => {
let results;
const image = new Image(); // 새로운 이미지 객체 생성
selectedImageObjRef.current = event.target.files[0];
image.src = URL.createObjectURL(selectedImageObjRef.current); // 이미지 파일 로드
// 이미지 로드가 완료될 때까지
image.onload = async () => {
const canvas = faceapi.createCanvasFromMedia(image);
FaceContainer.current.appendChild(canvas);
const ctx = canvas.getContext('2d');
canvas.width = image.width;
canvas.height = image.height;
ctx.drawImage(image, 0, 0, image.width, image.height);
const displaySize = {
width: 350,
height: 350 / (image.width / image.height),
};
faceapi.matchDimensions(canvas, displaySize);
const detections = await faceapi
.detectAllFaces(image)
.withFaceLandmarks()
.withFaceDescriptors();
results = await Promise.all(
detections.map((d) => faceMatcher.findBestMatch(d.descriptor)),
);
// 좌표값 저장
const resizedDetections = faceapi
.resizeResults(detections, displaySize)
.map((detection, i) => {
detection.label = results[i].toString(); // label 추가
return detection;
});
const rectangle = resizedDetections.map((d) => d.detection.box);
rectanglesRef.current = rectangle;
resizedDetectionsRef.current = resizedDetections;
results.forEach((result, i) => {
const box = resizedDetections[i].detection.box;
const drawBox = new faceapi.draw.DrawBox(box, {
label: result.toString(),
});
ctx.strokeStyle = 'white';
ctx.setLineDash([5, 5]);
drawBox.draw(canvas);
});
canvas.addEventListener('click', handleCanvasClick);
checkCanvasRef.current = canvas;
};
};
const handleCanvasClick = (event) => {
const canvas = FaceContainer.current;
const rect = canvas.getBoundingClientRect();
const x = event.clientX - rect.left;
const y = event.clientY - rect.top;
// 클릭한 좌표와 사각형의 좌표 비교
for (const rectangle of rectanglesRef.current) {
if (
x >= rectangle.x &&
x <= rectangle.x + rectangle.width &&
y >= rectangle.y &&
y <= rectangle.y + rectangle.height
) {
// 선택한 얼굴 정보 전달
const selected = resizedDetectionsRef.current.find(
(d) =>
d.detection.box.x === rectangle.x &&
d.detection.box.y === rectangle.y &&
d.detection.box.width === rectangle.width &&
d.detection.box.height === rectangle.height,
);
if (selected) {
handleFaceClick(selected);
}
break;
}
}
};
async function loadLabeledImage() {
const labels = ['혜준', '유진', '윤선', 'unknown'];
return Promise.all(
labels.map(async (label) => {
const description = [];
const img = await faceapi.fetchImage(`known/${label}.jpg`);
const detections = await faceapi
.detectSingleFace(img)
.withFaceLandmarks()
.withFaceDescriptor();
description.push(detections.descriptor);
return new faceapi.LabeledFaceDescriptors(label, description);
}),
);
}
return (
<BackgroundContainer>
<Content>
<div style={{ display: 'none', opacity: 0, visibility: 'hidden' }}>
<NavBar onImageSelect={handleImageSelect} />
</div>
{loaded ? (
<>
<Question>
<Upper>사진 속에서 저장하고자 하는</Upper>
<Down>
<Num>친구</Num>를 선택해주세요
</Down>
</Question>
<PictureContainer>
<img
src={URL.createObjectURL(location.state.img)}
style={{ position: 'relative', width: 350 }}
alt="선택한 이미지"
/>
<div
style={{
position: 'absolute',
top: 0,
}}
ref={FaceContainer}
/>
</PictureContainer>
</>
) : (
<div>
<LoadingScreen keyword="네컷 처리중 ..." />
</div>
)}
</Content>
</BackgroundContainer>
);
};
export default NumofPp;
