ELB & ASG 로 들어가기전에 몇가지 AWS의 특징들에 대한 용어정리를 하고 넘어가자
-
💡Scalability
확장성은 응용 프로그램이 적응을 통해 더 큰 로드를 처리할 수 있는 능력을 의미합니다. 이는 수직 확장(인스턴스의 크기 증가)과 수평 확장(인스턴스의 수 증가)으로 나뉩니다.
예를 들어, 수직 확장은 t2 인스턴스를 더 큰 인스턴스로 변경하는 것을 포함하며, 주로 단일 시스템이나 데이터베이스에 적용됩니다.
반면, 수평 확장은 더 많은 인스턴스를 추가하여 처리 능력을 늘리는 것으로, 웹 응용 프로그램이나 분산 시스템에서 일반적입니다. -
🔔 High Availability
고가용성은 응용 프로그램과 시스템이 여러 가용성 영역에 걸쳐 실행되어 재난이나 데이터 센터 손실에도 서비스를 지속할 수 있도록 하는 개념입니다. 예를 들어, 콜센터가 여러 지역에 분산되어 있어 한 지역에 문제가 생겨도 다른 지역에서 서비스를 계속 제공할 수 있습니다.
-
🌀Elasticity
탄력성은 클라우드의 또 다른 핵심 개념으로, 시스템이 수요에 따라 자동으로 sclae up(확장)하거나 scale down(축소)할 수 있는 능력을 의미합니다. 탄력성은 비용 최적화와 긴밀히 연관되어 있으며, 필요에 따라 리소스를 적절히 조정하여 사용량에 기반한 비용만 지불하게 합니다.
ELB(Elastic Load Balancing)
ELB는 Elastic Load Balancer로 서버혹은 서버셋으로 트래픽을 백엔드나 다운스트림 EC2 인스턴스 혹은 서버들로 나눠서 전달하는 역할을 합니다.
AWS는 세 가지 유형의 부하 분산기를 제공합니다:
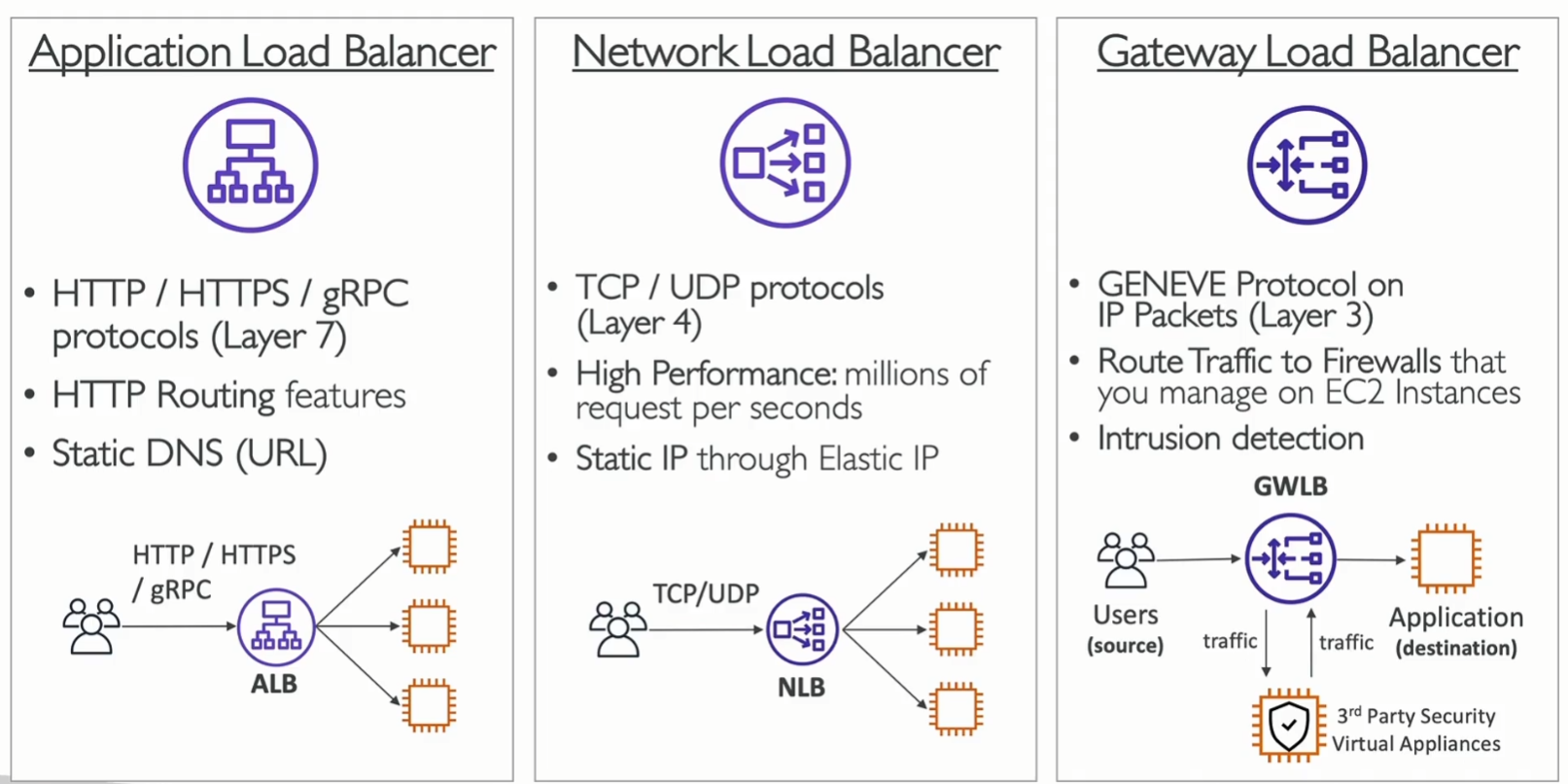

-
응용 프로그램 부하 분산기 (ALB): HTTP 및 HTTPS 트래픽에 최적화되어 있으며, 레이어 7에서 동작합니다. HTTP, HTTPS, GRPC 프로토콜을 지원하며, HTTP 라우팅 및 정적 DNS 기능을 제공합니다.
-
네트워크 부하 분산기 (NLB): 초고성능이 요구되는 TCP 및 UDP 트래픽에 적합하며, 레이어 4에서 작동합니다. 정적 IP를 사용하여 트래픽을 처리할 수 있습니다. AZ별로 하나의 고정IP를 가집니다.
-
게이트웨이 부하 분산기 (GWLB): 주로 방화벽과 같은 네트워크 가상 어플라이언스에 트래픽을 분산하는 데 사용됩니다. 이는 레이어 3에서 동작하며, GENEVE 프로토콜을 사용하여 IP 패킷을 처리합니다.
-
클래식 부하 분산기: 이전 세대의 부하 분산 장치로, 2023년에 서비스 종료되었습니다.
GPT의 야무진 예시

ASG(Auto Scaling Groups)
ASG란 사용자가 정의한 조건에 맞추어 EC2 인스턴스 그룹의 크기를 조절하여 비용을 최적화하는 서비스 입니다.
주요기능
-
동적 확장 및 축소: ASG는 설정된 정책에 따라 애플리케이션의 부하 변화를 감지하고 자동으로 EC2 인스턴스의 수를 늘리거나 줄여 애플리케이션의 부하를 처리합니다. 이는 예를 들어, 트래픽이 급증하는 시간에 자동으로 인스턴스를 추가하여 서비스의 안정성을 유지할 수 있게 해줍니다.
-
건강 검사 및 교체: ASG는 EC2 인스턴스의 상태를 지속적으로 모니터링하고, 실패한 인스턴스를 자동으로 교체하여 애플리케이션의 연속성을 보장합니다.
-
비용 최적화: ASG는 사용하지 않는 리소스를 자동으로 축소함으로써 비용을 절약할 수 있게 해줍니다. 예를 들어, 비수기에 자동으로 인스턴스 수를 줄여 비용을 절약할 수 있습니다.
-
스케줄 기반 확장/축소: ASG는 시간 기반의 스케줄을 설정하여 특정 시간에 인스턴스의 수를 자동으로 조절할 수 있습니다. 이는 예를 들어, 매일 특정 시간에 발생하는 트래픽 증가에 대비하여 미리 인스턴스를 확장할 수 있게 해줍니다.
Scaling strategies
Manual scaling
- ASG의 크기를 수동으로 업데이트하는 방법입니다. 예를 들어, 용량을 1에서 2로, 또는 그 반대로 변경할 때 사용됩니다.
Dynamic scaling
- 변화하는 요구에 자동으로 반응하여 ASG의 크기를 조절합니다. 동적 스케일링 내에는 여러 스케일링 정책이 있습니다.
- 단순 및 단계적 스케일링: 예를 들어, CloudWatch 알람이 작동될 때 EC2 인스턴스의 평균 CPU 사용률이 특정 기준을 초과하거나 미달할 때 ASG 용량을 자동으로 조절합니다.
- 대상 트래킹 스케일링
설명: 스케일링 정책을 통해 특정 메트릭(예: 평균 CPU 사용률)이 목표치(예: 40%)를 유지하도록 ASG가 자동으로 조정됩니다.
scheduled scaling
- 알려진 사용자 패턴이나 예상되는 트래픽 증가에 대비해 미리 스케일을 조정합니다. 예를 들어, 주요 이벤트 전에 용량을 늘리는 것입니다.
predictive scaling
- 머신 러닝을 사용하여 미래의 트래픽을 예측하고, 과거 트래픽 패턴을 기반으로 언제 ASG 용량을 조절해야 할지 결정합니다. 이 방법은 특정 시간에 로드가 정점에 이를 것으로 예측될 때 특히 유용합니다.
Amazon S3
대망의 S3입니다!
Amazon S3는 무한히 확장 가능한 저장 공간이라고 생각하시면 됩니다. 많은 웹사이트와 AWS 서비스가 백엔드 스토리지로 S3를 사용합니다. 대용량 traffic을 처리할 수 있고 각 파일에 access permission을 적어 놓아서 아무나 파일에 접근할 수 없게 합니다.
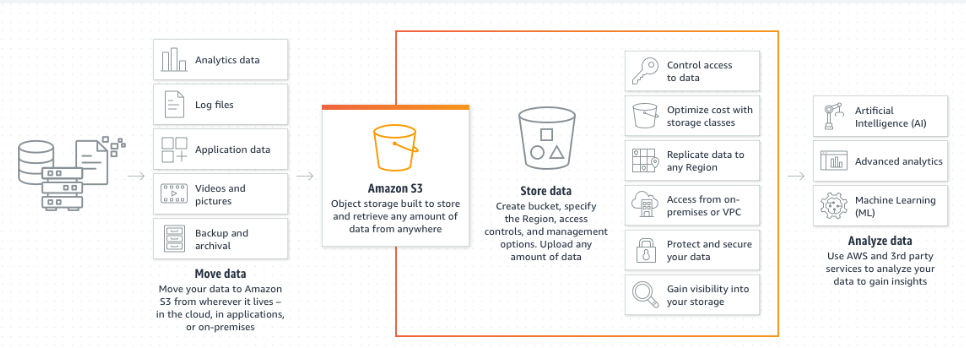
S3의 용도는 다양한데요, 파일이나 디스크의 백업 및 저장, 재해 복구를 위한 데이터 이전, 데이터 아카이빙, 하이브리드 클라우드 스토리지, 애플리케이션 호스팅, 미디어(영상, 이미지 등) 호스팅, 데이터 레이크 구축 및 빅데이터 분석, 소프트웨어 업데이트 배포, 정적 웹사이트 호스팅 등이 포함됩니다.
실제 사용 사례로는 나스닥(Nasdaq)이 S3 Glacier 서비스를 이용해 7년치 데이터를 저장하고, 시스코(Sysco)가 Amazon S3에서 데이터 분석을 통해 비즈니스 인사이트를 얻는 예가 있습니다.
S3는 파일을 '버킷'이라는 최상위 디렉토리에 저장하며, 이러한 파일들을 '객체'라고 합니다. 버킷은 전 세계적으로 유일한 이름을 가져야 하며, 특정 AWS 리전에 생성됩니다. 버킷 이름에는 대문자나 밑줄을 사용할 수 없으며, 3~63자 사이여야 하고, IP 주소 형식을 사용할 수 없습니다.
객체는 '키'와 '값'으로 구성되며, 키는 파일의 전체 경로를 나타냅니다. 객체의 최대 크기는 5TB이며, 5GB 이상의 파일을 업로드할 때는 멀티파트 업로드를 사용해야 합니다. 객체는 시스템이나 사용자에 의해 설정된 메타데이터(키와 값의 쌍), 태그, 버전 ID(버전 관리가 활성화된 경우)를 가질 수 있습니다.
Bucket Policy
S3 bucket policy
S3 콘솔에서 직접 할당할 수 있는 규칙입니다. 이를 통해 특정 사용자가 접근하거나 다른 계정의 사용자가 교차 계정 접근을 허용하여 S3 버킷에 접근할 수 있게 합니다. 또한, S3 버킷을 공개적으로 설정하는 방법도 여기에 포함됩니다.

JSON 기반의 정책으로, 리소스(적용 대상 버킷 및 객체), 행위(허용 또는 거부), 작업(API 호출 집합), 원칙(정책 적용 대상)을 정의합니다.
예를 들어, 모든 객체에 대한 공개 읽기 권한을 설정할 수 있습니다.
객체 액세스 제어 목록(ACL)
더 세분화된 보안을 제공하며 비활성화할 수 있습니다. 버킷 수준에서는 버킷 ACL이 있으나, 이는 흔하지 않으며 역시 비활성화할 수 있습니다. 현재는 S3 bucket policy를 사용한 보안이 가장 일반적인 방법입니다.
암호화
Amazon S3에서는 객체를 암호화 키를 사용하여 암호화함으로써 추가적인 보안 수준을 제공합니다.
공개 접근 및 교차 계정 접근
웹사이트 방문자와 같은 공개 사용자가 S3 버킷 내 파일에 접근할 수 있도록 S3 버킷 정책을 사용하여 공개 접근을 허용할 수 있습니다. 또한, 다른 AWS 계정의 IAM 사용자가 API 호출을 통해 S3 버킷에 접근할 수 있도록 교차 계정 접근을 허용하는 정책을 설정할 수 있습니다.
공개 접근 차단 설정
AWS에서는 데이터 유출을 방지하기 위해 공개 접근 차단 설정을 도입했습니다. 이 설정이 활성화되어 있으면, S3 버킷 정책이 버킷을 공개적으로 설정하더라도 버킷이 공개적으로 접근 가능하지 않습니다. 이 설정은 버킷이 절대 공개되어서는 안 되는 경우에 유용합니다.
Versioning
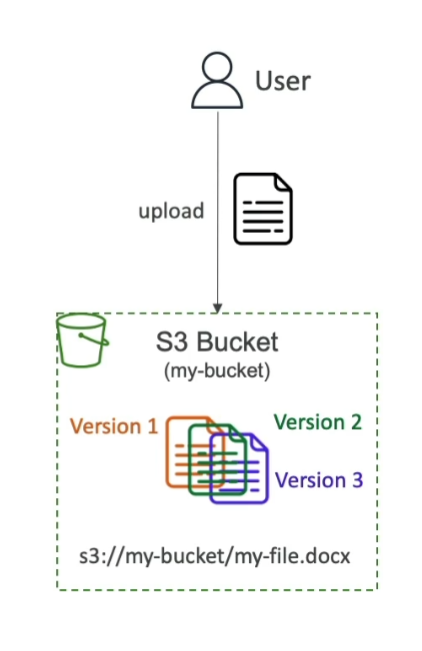
같은 키로 Overwrite하면 Versioning이 된다는 것도 알아야합니다!
Replicaiton
CRR (Cross-Region Replication)
- 용도: CRR은 한 지역의 S3 버킷에서 다른 지역의 S3 버킷으로 데이터를 비동기적으로 복제합니다.
- 장점: 이는 컴플라이언스 요구 사항을 충족하거나, 데이터에 대한 낮은 지연시간으로 접근할 수 있게 하거나, 계정 간에 데이터를 복제하는 데 도움이 됩니다.
SRR (Same-Region Replication)
- 용도: SRR은 같은 지역 내의 두 S3 버킷 간에 데이터를 비동기적으로 복제합니다.
- 장점: 로그를 여러 S3 버킷에 걸쳐 집계하거나, 생산 환경과 테스트 계정 간의 라이브 복제를 수행하는 데 유용합니다.
두 복제 방식 모두 소스 버킷과 대상 버킷에서 Versioning을 활성화해야 하며, 복제는 백그라운드에서 자동으로 발생합니다. 이 과정은 복제를 위한 적절한 IAM 권한이 있어야 작동하며, 이는 S3 서비스가 지정된 버킷에서 읽고 쓸 수 있게 허용합니다. 또한, 복제된 버킷은 같은 AWS 계정 내에 있거나 다른 계정 간에 설정할 수 있습니다.
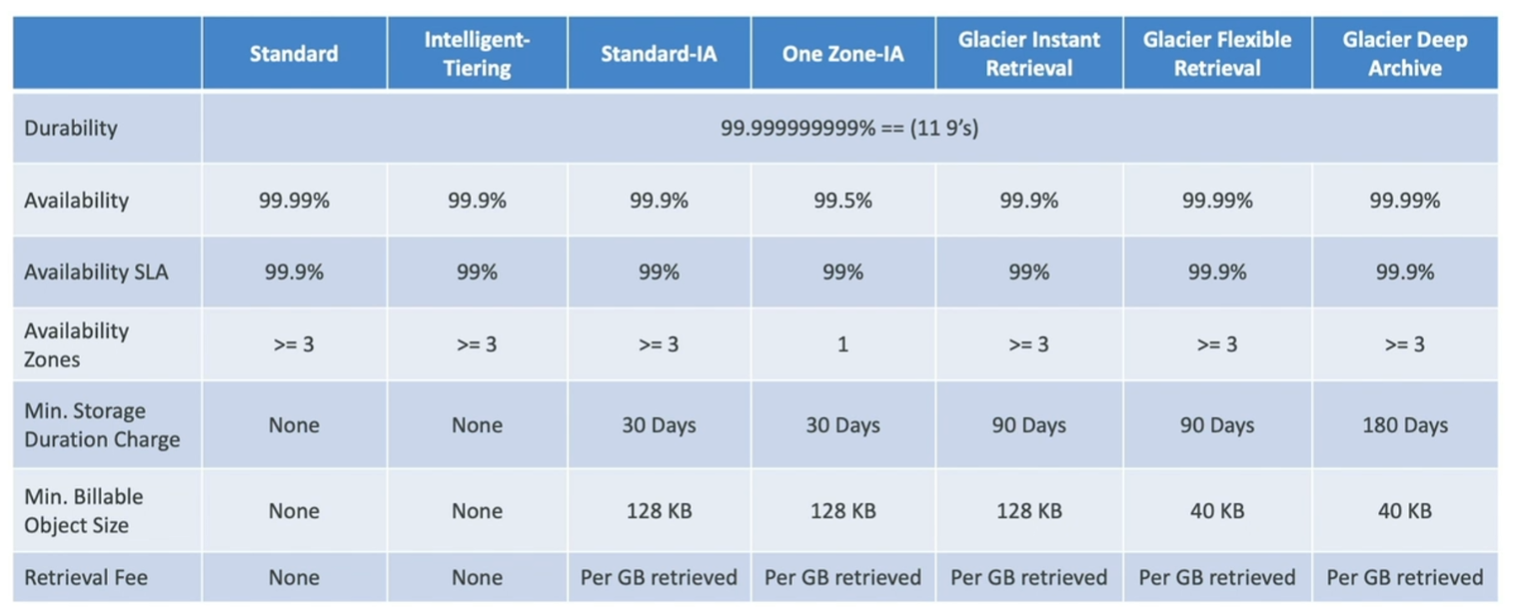
S3 Storage Classes
먼저 짚고 넘어가야할 개념이 두개가 있습니다.
Durability
Durability는 스토리지가 얼만큼 데이터 loss없이 정보를 안전하게 저장을 하고 유지하느냐를 나타내는 수치인데요.
Amazon S3는 일반적으로 99.999999999% (11개의 9)의 내구성을 제공한다고 알려져 있으며, 이는 어떠한 데이터도 거의 손실되지 않을 것임을 의미합니다.
Availability
가용성(Availability)은 서비스가 얼마나 신뢰할 수 있고 지속적으로 접근 가능한지를 나타내는 수치입니다.
즉, 시스템이 예상되는 운영 시간 동안 사용할 수 있는 상태인 정도를 말하죠. 이는 서버 장애, 네트워크 문제, 유지보수 이벤트 등으로 인한 다운타임 없이 사용자가 서비스를 지속적으로 이용할 수 있음을 의미합니다.
예를 들어, Amazon S3는 일반적으로 연간 가용성이 99.99% 이상임을 목표로 하고 있으며, 이는 1년에 몇 분에서 몇 시간 정도의 다운타임만을 허용함을 의미합니다.
🍀 스토리지 종류


❄️ AWS Snow Family
AWS Snow Family는 대규모 데이터 이전과 엣지 컴퓨팅을 위한 고도로 보안된 휴대용 장치들을 제공합니다. 데이터 마이그레이션과 엣지 컴퓨팅의 두 가지 주요 용도로 사용되며, 인터넷을 통한 대량 데이터 전송의 시간, 비용, 연결성 문제를 해결합니다.
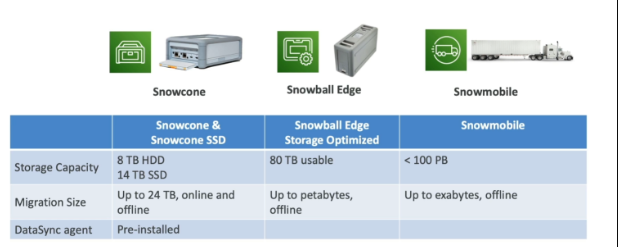
What is Datasync?
DataSync is a tool or service provided by cloud providers like Amazon Web Services (AWS) to help you easily move your data between your on-premises storage (like your computer or local server) and the cloud (which is like a big, secure storage space on the internet), or between different cloud storage services. It automates the process of transferring data, making it faster and more reliable, without requiring you to write complex code or manage the transfer process manually.
Snow Family -Usage Process
-
AWS 콘솔에서 장치를 요청하여 배달받습니다.
-
서버에 Snowball 클라이언트를 설치하거나 AWS Ops Hub를 사용합니다.
-
Snowball 장치를 서버에 연결하고 클라이언트에서 파일 복사를 시작합니다.
-
준비가 되면 장치를 다시 발송합니다. E-Ink 마커 덕분에 장치는 바로 올바른 AWS 시설로 갑니다.
-
데이터는 S3 버킷에 로드되고, Snowball 장치는 최고의 보안 조치에 따라 완전히 지워집니다.
edge computing
Imagine you're on a camping trip in a beautiful but remote forest where there's no cell service or internet. You've brought a digital camera to take photos of the wildlife and scenery. Now, let's say you want to sort these photos, delete the blurry ones, and even identify the types of birds you've captured in your shots. However, since you're out in the wilderness, far from any city or Wi-Fi connection, you can't just upload your photos to a cloud service or use online tools to analyze them.
This is where edge computing comes in, similar to using a device from AWS's Snow Family like the Snowball Edge or Snowcone. Imagine these devices as a powerful, portable computer that you can bring along on your trip. Before you leave, you program it to recognize different types of birds and to sort photos based on quality.
Once you're in the forest, you connect your digital camera to this portable device. It processes all your photos right there on the spot—sorting them, deleting the ones that didn't turn out well, and identifying the bird species in each photo. This is all done without needing to connect to the internet.
Then, when you're back home and want to upload your neatly organized and analyzed photos to the cloud (AWS), you just send the device back to AWS, and they transfer all your data for you.
In this example, the forest is your "edge" location—far from the core of computing power and internet connectivity. The portable device (similar to Snowball Edge or Snowcone) allows you to process data and run computations on-site, exactly like edge computing in remote or connectivity-challenged areas.
Storage Gateway
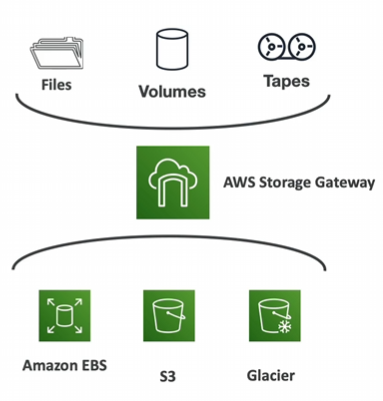
bridge between on-premise data and cloud data in S3
➕추가
-
Lifecycle Rules can be used to define when S3 objects should be transitioned to another storage class or when objects should be deleted after some time.
-
Snowball Edge Storage Optimized devices are well suited for large-scale data migrations and recurring transfer workflows, as well as local computing with higher capacity needs.
