
요새 Claude Code 좀 이상하지 않나요
Claude Code 사용하다보면 이런 경험이 다들 있으실 겁니다. 분명 Opus 4.6, Sonnet 4.6을 쓰고 있는데, 코드 검증도 똑바로 안 하고 자신 있게 틀린 답을 내놓을 때. 존재하지 않는 API 버전을 지어내거나, 읽지도 않은 파일 구조를 단정하거나, 아무것도 확인 안 하고 "이 부분은 정상입니다"라고 선언하고는 실제로는 에러가 그대로 남아있는 식인 일들.
근데 이게 개인의 설정 문제가 아니었습니다. 2026년 2월부터 누적된 제품 회귀이고, Anthropic도 공식적으로 인정한 문제였습니다. 다행히 이 문제는 환경 변수 하나로 임시 우회할 수 있습니다.
해결책
export CLAUDE_CODE_EFFORT_LEVEL=high
export CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1Max 200 요금제를 사용하신다면 CLAUDE_CODE_EFFORT_LEVEL=max로 사용하셔도 좋습니다.
첫 번째 명령어는 effort를 high로 고정하는 겁니다. 기본값이 medium으로 낮춰졌기 때문에, 명시적으로 올려줘야 이전 수준의 추론 깊이를 되찾습니다.
두 번째는 adaptive thinking을 비활성화하고 고정 thinking budget으로 돌리는 겁니다. 모델이 턴마다 '이걸 생각할까 말까'를 판단하는게 아니라, 매번 일정한 추론 토큰을 사용하게 하는겁니다. Boris Cherny가 공식 워크어라운드로 제시한 설정입니다.
영구적인 적용은 ~/.zshrc or ~/.bashrc에 추가하고 쉘을 재시작하시면 됩니다.
echo 'export CLAUDE_CODE_EFFORT_LEVEL=high' >> ~/.zshrc
echo 'export CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1' >> ~/.zshrc
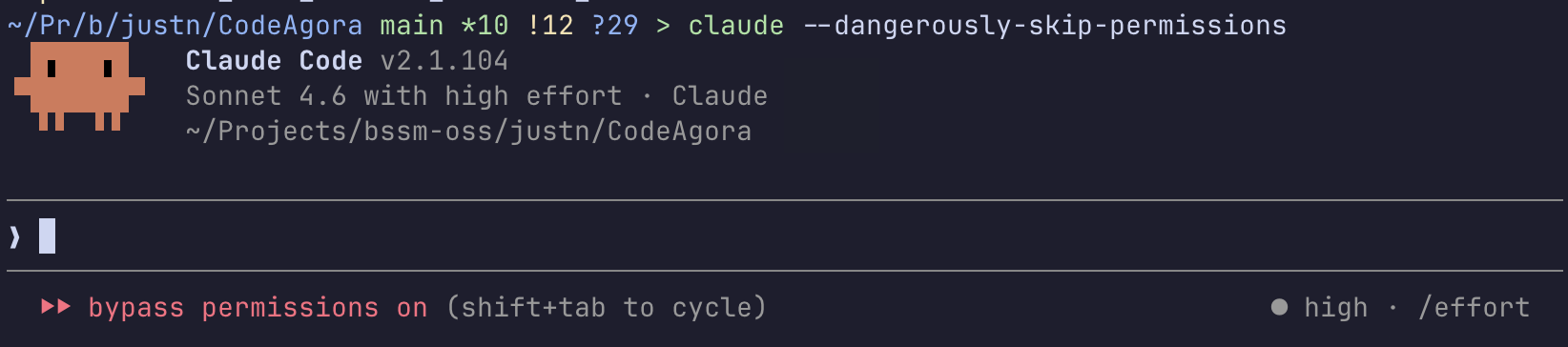
source ~/.zshrc설정이 적용됐는지는 Claude Code를 실행했을 때 로고 옆에 "with high effort"가 표시되는지로 확인할 수 있습니다.
배경
이게 이렇게 된 이유가 있습니다.
Anthropic은 2월에 Opus 4.6을 출시하면서 adaptive thinking을 기본 활성화했습니다. 이 기능은 모델이 매 턴마다 "이 요청이 얼마나 복잡한가"를 스스로 판단하고, 복잡하다고 느끼면 깊게, 간단해보이면 얕게 생각합니다. (아예 넘길수도 있구요.) 이론적으로는 토큰 효율과 품질을 동시에 잡는 전략이죠.
문제는 실제 동작입니다. Claude Code 팀 리드 Boris Cherny가 직접 밝혔는데, 특정 턴에서 모델이 thinking을 0 토큰으로 할당하는 경우가 생깁니다. 생각을 전혀 하지 않은 상태에서 답변을 생성하니 환각이 그대로 나오는데, 문제는 모델이 이 답변에 확신하는 겁니다. 그래서 생각 안 한 턴에서 자신만만한 거짓말이 섞여 나오는 패턴이 반복됩니다.
여기에 3월 3일에 기본 effort 수준이 high에서 medium으로 낮춰졌고, 3월 8일부터 thinking redaction이 단계적으로 롤아웃됐습니다. 이런 변경이 누적되면서 복잡한 코딩 작업에서 품질이 엄청 떨어진거죠...
한 커뮤니티 분석에 따르면 코드 수정 전 리서치 행위가 70% 감소했고, 사용자가 모델을 중단시키는 빈도가 12배 증가했고, 벤치마크상 점수는 유지되지만, 실사용에서는 망가진 상태라고 합니다.
해결책은 위에 적힌대로 하시면 됩니다.
주의 사항
토큰 소진이 엄청 빨라집니다. Medium effort + adaptive 조합은 원래 토큰을 아끼는 방향으로 최적화돼 있어요. 이걸 끄면 당연히 같은 작업에 더 많은 토큰이 소비됩니다.
Pro ($20) 플랜 사용자분들은 특히 주의하셔야 해요. 5시간당 약 44,000 토큰 제한에 걸려있는데, 여기에 max effort + adaptive 끄기 조합을 돌리면 한두 시간 안에 제한에 도달할 수 있습니다. Pro 쓰시는 분들은 위에서 알려드린대로 high까지만 올리는 게 현실적입니다. Max 플랜이라고 해도 effort를 max로 박아두는 건 복잡한 리팩토링이나 디버깅 세션에만 쓰고, 간단한 작업(git status, 파일 읽기, 짧은 질문 같은 것들)은 기본값으로 두는 게 좋아요.
CLAUDE_CODE_EFFORT_LEVEL 환경변수는 모든 다른 설정을 덮어씁니다. 평소에 슬래시 커맨드 /effort로 세션별 조정하던 습관이 있으시다면, 환경변수 설정한 순간부터 그 커맨드들이 무시됩니다. 세션별로 유동적으로 제어하고 싶으시면 환경변수 대신 --effort 플래그나 /effort 커맨드 쓰시는 게 낫습니다.
그리고 이게 근본 해결은 아닙니다. 이 설정은 Anthropic이 공식 문서에 "interim workaround(임시 우회)"라고 대놓고 써놓은 임시방편이에요. Adaptive thinking의 under-allocation 문제는 아직 조사 중이고, 향후 모델 업데이트에서 수정될 가능성이 있습니다. 그러니까 이 설정을 평생 유지해야 한다는 뜻이 아니라, 지금 시점의 임시 방어선 정도로 생각하시면 됩니다.
작업 종류별 설정 전략
단일 설정으로 모든 작업을 커버하려고 하지 마시고, 작업 성격에 맞춰서 조정하시는 게 훨씬 효율적입니다.
복잡한 리팩토링, 멀티 파일 디버깅, 아키텍처 설계 같은 고부하 작업에는 max effort + adaptive 끄기 조합이 맞습니다. 토큰을 더 쓰더라도 환각 없는 일관된 품질이 중요한 영역이죠.
커밋 메시지 작성, 코드 리뷰, 간단한 Q&A 같은 일상 작업은 high effort 정도면 충분해요. Adaptive는 켜둬도 됩니다. 이런 작업에서는 under-allocation 문제가 덜 치명적이거든요.
Subagent나 자동화 파이프라인 내부에서 단순 작업을 반복하는 경우에는 오히려 low effort가 적절합니다. Subagent의 frontmatter에 effort: low를 명시하면 해당 agent가 실행될 때만 낮은 수준으로 동작합니다.
마치며
AI 도구 품질이 공지 없이 조용히 바뀌는 상황은 사용자 입장에서 진짜 답답한 일입니다. 벤치마크 수치와 실사용 체감 사이의 간극, 소리 소문 없이 진행되는 기본값 변경, 숨겨진 환경변수로만 우회 가능한 설정들... 이런 게 쌓이면 내가 뭘 잘못하고 있나 를 계속 디버깅하게 되죠.
요즘 Anthropic 참 이상하네요. Claude Code 유출이나 Mythos 배포 안 하는 거도 이상하고, 전체적으로 토큰 용량도 체감상 상당히 많이 줄었기도 하구요. Threads 같은 플랫폼에선 OpenAI의 Codex가 많이 바이럴되기도 하던데, 요즘 행보의 연쇄 작용이겠죠.
그래도 이번 adaptive thinking 이슈는 최소한 Anthropic이 공식 문서에 해결책을 등재했고, 팀 리드가 공개적으로 인정했다는 점에서 드러난 케이스입니다. 이 글이 같은 문제 겪으시는 분들한테 도움이 되면 좋겠어요.
참고 링크


덕분에 제 고능한 클로드를 다시 되찾을 수 있었어요ㅎㅎ