웹 라이브러리 구성
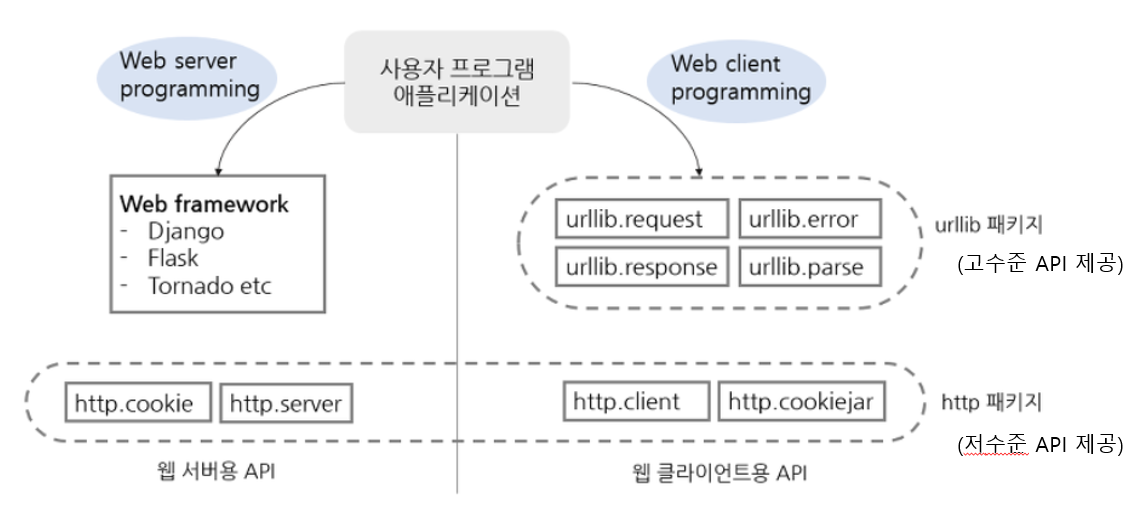
파이썬 3.x 버전에서는 다음과 같이 관련된 모듈들을 모아서 패키지를 만들었고, 모듈명을 통해 서버쪽 라이브러리와 클라이언트쪽 라이브러리를 좀 더 확실히 구분짓고 있다.
출처 : https://ssola22.tistory.com/13
urllib 패키지에는 웹 클라이언트를 작성하는 데 사용되는 가장 빈번하게 사용되는 모듈들이 있다.
http 패키지는 크게 서버용과 클라이언트용 라이브러리로 나누어 모듈을 담고 있고, 쿠키 관련 라이브러리도 http 패키지 내에서 서버용과 클라이언트용으로 모듈이 구분지어 있다.
웹 클라이언트를 개발하는 경우 주로 urlib 패키지를 사용한다. http.client 모듈이 HTTP 프로토콜 처리와 관련된 저수준의 클라이언트를 제공하는 반면 urllib 패키지의 모듈들은 HTTP 서버뿐만 아니라 FTP 서버 및 로컬 파일 등을 처리하는데, 클라이언트에서 공통적으로 필요한 함수와 클래스 등을 제공하기 때문이다.
웹 서버 프로그래밍 시 http.cookie 모듈이나 http.server 모듈을 사용하지 않고 장고와 같은 웹 프래임워크를 사용하여 개발한다.
웹 클라이언트 라이브러리
우리가 많이 사용하는 웹 브라우저는 다양한 웹 클라이언트 중 하나일 뿐이다. 웹 브라우저 이외에도 웹 서버에 요청을 보내는 애플리케이션은 모두 웹 클라이언트라고 할 수 있다.
파이썬은 이런 클라이언트를 프로그래밍할 수 있도록 여러 라이브러리를 제공하고 있다.
웹 클라이언트를 위한 파이썬 표준 라이브러리가 있지만 실제 프로젝트에서는 외부 라이브러리인 requests, beautifulsoup4 등을 더 많이 사용하는 편이다.
urllib.parse 모듈
URL의 분해, 조립, 변경 및 URL 문자 인코딩, 디코딩 등을 처리하는 함수를 제공한다.
from urllib.parse import urlparse
result = urlparse("http://www.python.org:80/guido/python.html;philosophy?overall=3#n10")
print(result)urlparse() 함수는 URL을 파싱한 결과로 ParseResult 인스턴스를 반환한다.

ParseResult 클래스 속성의 의미는 다음과 같다.
- scheme : URL에 사용된 프로토콜
- netloc : 네트워크 위치, user:password@host:port 형식으로 표현되며, HTTP 프로토콜인 경우 host:port 형식이다.
- path : 파일이나 애플리케이션 경로를 의미
- params : 애플리케이션에 전달될 매개변수이다. 현재는 사용 x
- query : 질의 문자열 또는 매개변수로 &로 구분된 이름=값 쌍 형식 표시
- fragment : 문서 내의 앵커 등 조각을 지정
urllib.request 모듈
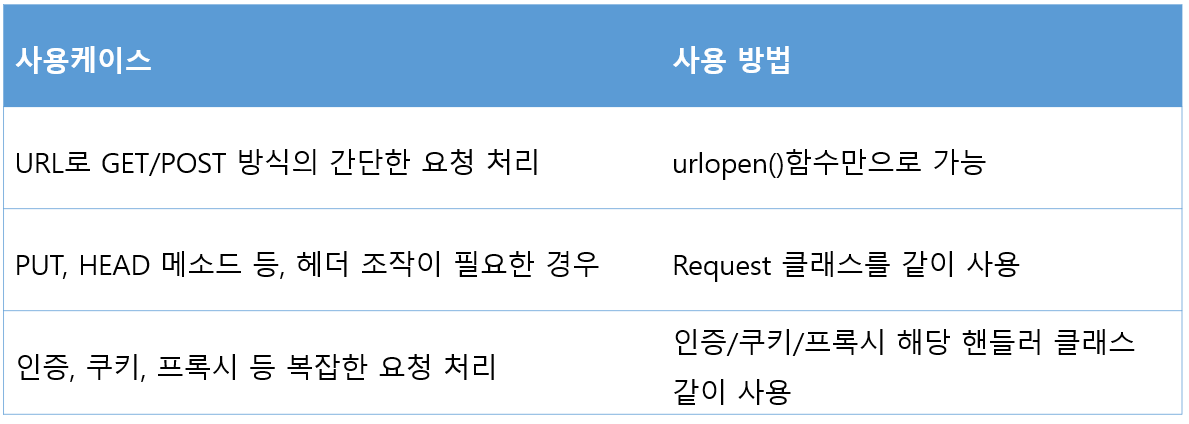
주어진 URL에서 데이터를 가져오는 기본 기능을 제공한다. 가장 기본이 되는 urlopen() 함수만 잘 다뤄도 웹 클라이언트 대부분 작성할 수 있다.
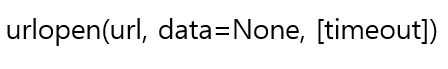
- url 인자로 지정한 URL로 연결하고 유사 파일 객체를 반환한다. url 인자는 문자열이거나, Request 클래스의 인스턴스가 올 수 있다.
- url에 file 스킴을 지정하면 로컬 파일을 열 수 있다.
- 디폴트 요청 방식은 GET이고 웹 서버에 전달할 파라미터가 있으면 질의 문자열을 url 인자에 포함해서 보낸다.
- 요청 방식을 POST로 보내고 싶으면 data 인자에 질의문자열을 지정해준다.
- 옵션인 timeout은 응답을 기다리는 타임아웃 시간을 초로 표시한다.
urlopen()함수 - GET 방식 요청
from urllib.request import urlopen
f = urlopen("http://www.example.com")
print(f.read(500).decode('utf-8'))HTTP GET 방식을 디폴트로 사용하여 웹 서버에 요청을 보낸다. 웹 브라우저의 주소창에 www.example.com이라고 입력하는 것과 동일하다.
urlopen()함수 - POST 방식 요청
urlopen() 함수 호출 시 data 인자를 지정해주면 함수는 자동으로 POST 방식으로 요청을 보낸다. data 인자는 URL에 허용된 문자열로 인코딩되어야 하고, 유니코드(str) 타입이 아니라 바이트 스트링(bytes) 타입이어야 한다.
from urllib.request import urlopen
data = "language=python&framework=django"
f = urlopen("http://127.0.0.1:8000", bytes(data, encoding='utf-8'))
print(f.read(500).decode('utf-8'))urlopen()함수 - Request 클래스로 요청 헤더 지정
요청 헤더를 지정해서 보내고 싶은 경우 URL을 지정하는 방식을 변경하면 된다. url 인자에 문자열 대신에 Request 객체를 지정한다. Request 객체를 생성하고 add_header()로 헤더를 추가해서 웹 서버로 요청을 보내면 된다.
from urllib.parse import urlencode
from urllib.request import Request, urlopen
url = "http://127.0.0.1:8000"
data = {
'name' : '이주성',
'email' : 'anaooauc1236@naver.com',
'url' : 'http://naver.com',
}
encData = urlencode(data)
postData = bytes(encData, encoding='utf-8')
req = Request(url, data=postData)
req.add_header('Context-Type', 'application/x-www-form-urlencoded')
f = urlopen(req)
print(f.info())
print(f.read(500).decode('utf-8'))urlopen()함수 - HTTPBasicAuthHandler 클래스로 인증 요청
HTTP의 고급 기능을 포함하여 요청을 보낼 수도 있다. 각 기느에 맞는 핸들러 객체를 정의하고, 그 핸들러를 bulid_opener() 함수를 사용해 오프너에 등록 후 오프너의 open() 함수를 호출하면 서버로 요청이 전송된다.
아래는 HTTPBasicAuthHandler 클래스를 이용해 인증 데이터를 같이 보내는 프로그램이다. 인증 데이터인 realm, user, passwd는 모두 서버에서 지정한 것으로 채워서 보낸다. 특히 realm은 서버로부터 받는 401응답에서 알 수 있다.
realm은 인증되는 영역을 설명하거나 인증의 범위(요청 URI의 보호공간을 식별하기 위한 문자열)를 알리는데 사용된다. 이는 어떤 공간에 사용자가 접근하려고 시도하는지를 알리기 위하여, "중간 단계의 사이트에 대한 접근"과 같거나 또는 비슷한 메시지가 될 수 있다.
from urllib.request import HTTPBasicAuthHandler, build_opener
auth_handler = HTTPBasicAuthHandler()
auth_handler.add_password(realm='ksh', user='shkim', passwd='shkimadmin',\
uri="http://127.0.0.1:8000/auth/")
opener = build_opener(auth_handler)
resp = opener.open("http://127.0.0.1:8000/auth/")
print(resp.read().decode('utf-8'))urlopen()함수 - HTTPCookieProcessor 클래스로 쿠기 데이터를 포함하여 요청
아래는 HTTPCookieProcessor 클래스를 사용하여 쿠키 데이터를 처리하는 프로그램이다.
첫 번째 요청에서 쿠키를 담기 위한 준비를 하고 서버로 요청을 보낸다.
두 번째 요청에서 첫 번째 응답에서 받은 쿠키를 헤더에 담아서 요청을 보낸다. 만약 두 번째 요청에 쿠키 데이터가 없다면 서버에서 에러로 응답한다.
from urllib.request import HTTPCookieProcessor, build_opener, Request
url = "http://127.0.0.1:8000/cookie/"
# first request (GET) with cookie handler
# 쿠키 핸들러 생성, 쿠키 데이터 저장은 디폴트로 CookieJar 객체를 사용함
cookie_handler = HTTPCookieProcessor()
opener = build_opener(cookie_handler)
req = Request(url)
res = opener.open(req)
print(res.info())
print(res.read().decode('utf-8'))
# second request (POST)
print("========================================================")
data = "language=python&framework=django"
encData = bytes(data, encoding='utf-8')
req = Request(url, encData)
res = opener.open((req))
print(res.info())
print(res.read().decode('utf-8'))urlopen() 함수 - ProxyHandler 및 ProxyBasicAuthHandler 클래스로 프록시 처리
ProxyHandler 및 ProxyBasicAuthHandler 클래스를 사용해 프록시 서버를 통과해서 웹 서버로 요청을 보내는 프로그램이다. install_opener() 함수를 사용해 디폴트 오프너를 지정할 수도 있다.
from urllib.request import ProxyHandler, ProxyBasicAuthHandler, build_opener, install_opener, urlopen
url = "http://www.example.com"
proxyServer = "http://www.proxy.com:3128/"
# 프록시 서버를 통해 웹 서버로 요청을 보낸다.
proxy_handler = ProxyHandler({"http": proxyServer})
# 프록시 서버 설정을 무시하고 웹 서버로 요청을 보낸다.
# proxy_handler = ProxyHandler({})
# 프록시 서버에 대한 인증 처리
proxy_auth_handler = ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', 'host', 'username', 'password')
# 2개의 핸들러를 오프너에 등록
opener = build_opener(proxy_handler, proxy_auth_handler)
# 디폴트 오프너를 지정하면, urlopen() 함수로 요청 가능
install_opener(opener)
# opener.open() 대신에 urlopen()을 사용
f = urlopen(url)
print("geturl():", f.geturl())
print(f.read(300).decode('utf-8'))urllib.request 모듈 예제
특정 웹 사이트에서 이미지만을 검색하여 그 리스트를 보여주는 코드 작성
urlopen() 기능 + HTMLParser 클래스 사용
HTMLParser 클래스는 HTML 문서를 파싱하는 데 사용되는 클래스이다.
from html.parser import HTMLParser
from urllib.request import urlopen
class ImageParser(HTMLParser):
# img 태크를 찾기 위해 handle_starttag 함수 오버라이드
def handle_starttag(self, tag, attrs):
if tag != 'img':
return
if not hasattr(self, 'result'):
self.result = []
# img src 속성을 찾으면 속성 값을 self.result 리스트에 추가
for name, value in attrs:
if name == 'src':
self.result.append(value)
# HTML이 주어지면 HTMLParse를 이용해 이미지를 찾고, 그 리스트를 출력
def parse_image(data):
parser = ImageParser()
# HTML 문장을 feed() 함수에 주면 파싱하고 그 결과를 parser.result 리스트에 추가
parser.feed(data)
# 파싱 결과를 set 타입의 dataSet으로 모아준다. -> set이므로 중복 제거
dataSet = set(x for x in parser.result)
return dataSet
def main():
url = "http://www.google.co.kr"
# urlopen을 사용하여 구글 사이트에 접속한 후 첫 페이지 내용을 가져온다.
with urlopen(url) as f:
# 사이트의 데이터는 인코딩된 데이터이므로, 인코딩 방식(charset)을 알아내 그 방식으로 디코딩 해준다.
charset = f.info().get_param('charset')
data = f.read().decode(charset)
dataSet = parse_image(data)
print("\n>>>>>>>> Fetch Images from", url)
# 찾은 이미지들을 정렬하여 라인별로 출력
print("\n".join(sorted(dataSet)))
if __name__ == '__main__':
main()[실행 결과]

http.client 모듈
urllib.request 모듈로는 처리할 수 없는 경우나 HTTP 프로토콜 요청에 대한 저수준의 세밀한 기능이 필요할 때 http.client 모듈을 사용한다.
[코딩 순서]

http.client 모듈 예제
from html.parser import HTMLParser
from http.client import HTTPConnection
from os import makedirs
from os.path import exists, join, basename
from urllib.parse import urljoin, urlunparse
from urllib.request import urlretrieve
class ImageParser(HTMLParser):
def handle_starttag(self, tag, attrs):
if tag != 'img':
return
if not hasattr(self, 'result'):
self.result = []
for name, value in attrs:
if name == 'src':
self.result.append(value)
# HTML 문장이 주어지면 ImageParser를 이용해 이미지를 찾고,
# 그 이미지들을 DOWNLOAD 디렉토리에 다운로드하는 함수
def download_image(url, data):
if not exists('DOWNLOAD'):
makedirs('DOWNLOAD')
parser = ImageParser()
parser.feed(data)
dataSet = set(x for x in parser.result)
# dataSet으로 모은 파싱 결과를 정렬한 후 하나씩 처리한다.
for x in sorted(dataSet):
# 다운로드하기 위해 소스 URL과 타깃 파일명을 지정한다.
# urljoin() 함수로 소스 URL을 지정한다.
# urljoin()은 baseURL과 파일명을 합쳐서 완전한 URL을 리턴하는 함수이다.
imageUrl = urljoin(url, x)
basename_ = basename(imageUrl)
targetFile = join('DOWNLOAD', basename_)
print("Downloading...", imageUrl)
# urlretrieve() 함수는 src로부터 파일을 가져와서 targetFile로 생성해준다.
urlretrieve(imageUrl, targetFile)
def main():
host = "www.google.co.kr"
conn = HTTPConnection(host)
conn.request("GET", '')
resp = conn.getresponse()
charset = resp.msg.get_param('charset')
data = resp.read().decode(charset)
conn.close()
print("\n>>>>>>>>>> Download Images from", host)
url = urlunparse(('http', host, '', '', '', ''))
download_image(url, data)
if __name__ == '__main__':
main()
출처: Django로 배우는 파이썬 웹 프로그래밍(기초) - 김석훈님
