이전 글에서 Java 병렬 처리와 비동기 작업을 효율적으로 관리하기 위한 ExecutorService에 대해 알아 보았는데요.
이번에는 이 ExecutorService의 Factory 역할을 하는 Executors에 대해 자세히 뜯어봅시다!
왜 Executors가 필요할까?
Java에서 직접 스레드를 생성하고 관리하는 것은 매우 복잡하고 잘못 사용하면 오히려 성능이 떨어질 수 있습니다. 따라서 스레드 풀을 적절하게 사용하는 것이 중요한데, 이때 Executors가 복잡한 스레드 풀 설정을 간단하게 할 수 있도록 도와줍니다.
즉, 필요한 ExecutorService 인스턴스를 생성해주는 Factory 역할을 수행하는 것이죠.
Factory 패턴이란 무엇일까?
Factory 패턴은 객체 생성 로직을 캡슐화해서 클라이언트가 직접 인스턴스를 생성하지 않고 Factory 메서드를 통해 생성할 수 있도록 합니다. 즉, 말 그래도 객체 생성을 공장(Factory)에 맡기고 대신 생성하도록 하는 것이죠.
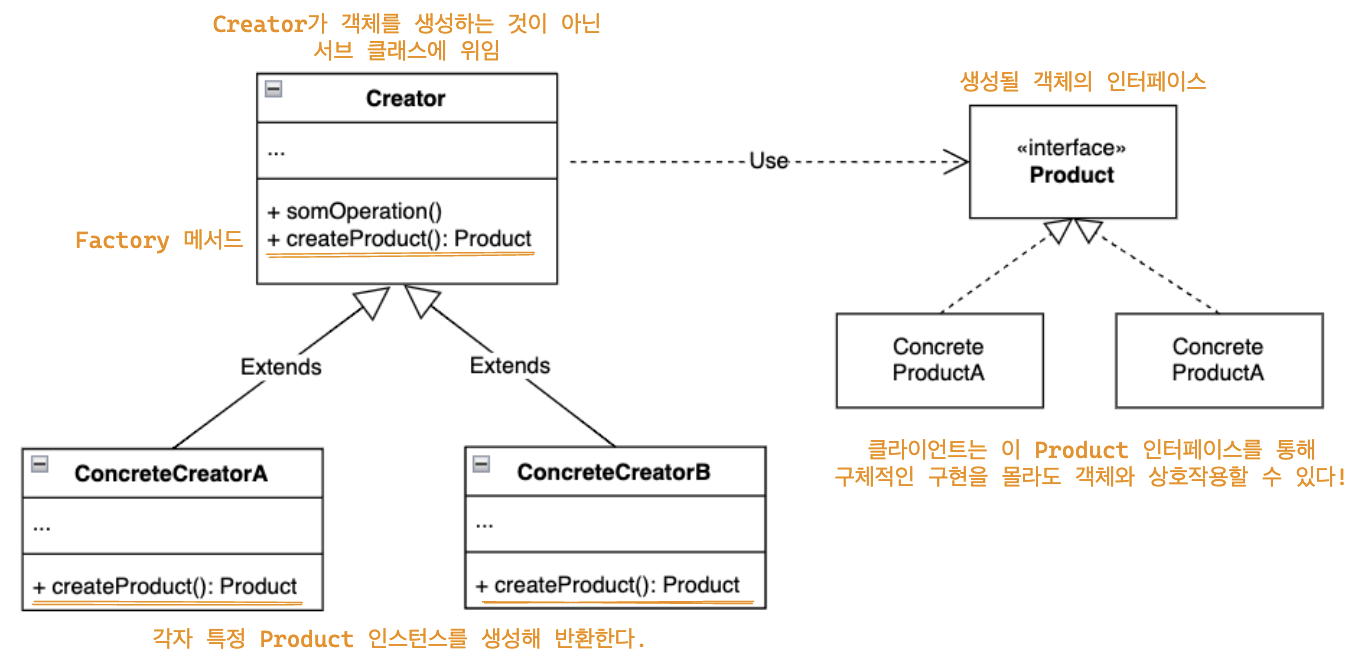
이렇게 하면 "new"를 통해 직접 객체를 생성하지 않으므로 코드가 간결해지고 유지 보수가 쉬워집니다. 또한, 서브 클래스에서 어떤 구체 클래스의 인스턴스를 생성할지 결정할 수 있기 때문에 코드의 유연성이 높아집니다. 객체 생성 자체를 캡슐화해서 은닉하기 때문에 객체 생성 과정의 복잡성을 숨길 수 있다는 장점도 있습니다.
Executors에 Factory 패턴이 적용된 방식
Executors는 Factory 패턴을 적용해 스레드 풀을 만들고 관리하는 로직을 캡슐화하고, 간단한 인터페이스를 통해 다양한 종류의 스레드 풀을 생성할 수 있게 합니다.
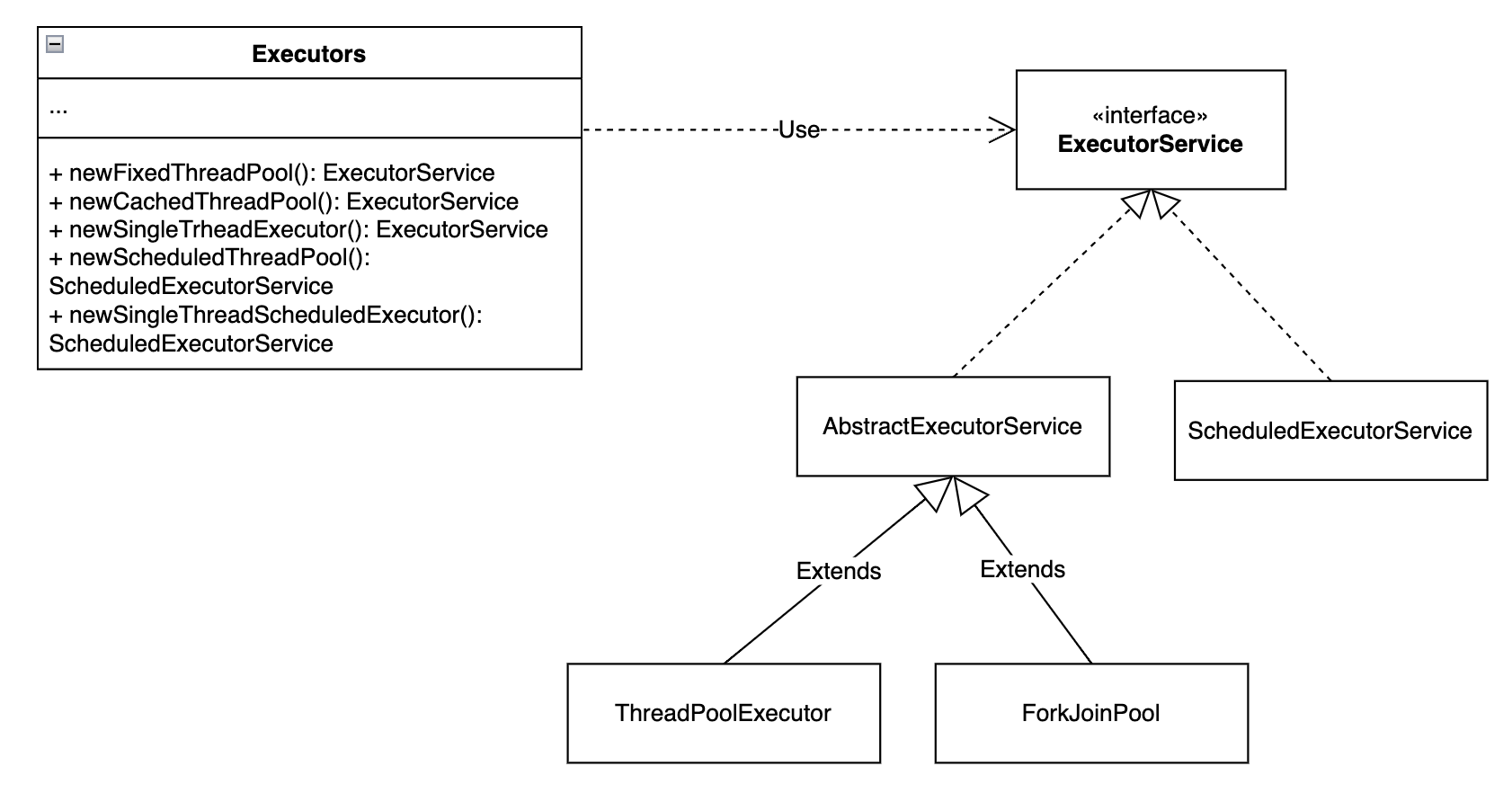
일반적인 Factory 패턴과 약간 다른 점은 Executors 클래스가 서브 클래스로 객체 생성을 위임하는 것이 아닌 Executors 자체에서 다양한 ExecutorService 인스턴스를 직접 생성하는 정적 Factory 메서드를 제공한다는 점입니다.
왜 이런 방식을 택했나 찾아보니 Executors 클래스 자체가 유틸리티 클래스로 설계되었기 때문에 정적 메서드를 통해 바로 스레드 풀을 생성하도록 한 것입니다. 정적 팩토리 메서드를 통해 복잡한 상속 구조도 피하면서 다양한 구현체를 간단하게 생성할 수 있도록 한 것이죠.
Executors 클래스 뜯어보기
본격적으로 Executor 클래스를 뜯어봅시다.
Executors는 위에서 설명했듯이 ExecutorService와 ScheduledExecutorService 뿐만 아니라, ThreadFactory 및 Callable 클래스를 위한 유틸리티 팩토리 클래스입니다. 스레드 풀 및 스케줄링에 대한 다양한 정적 팩토리 메서드를 제공해서 복잡한 멀티 스레드 환경의 작업을 간단하게 다룰 수 있도록 도와줍니다.
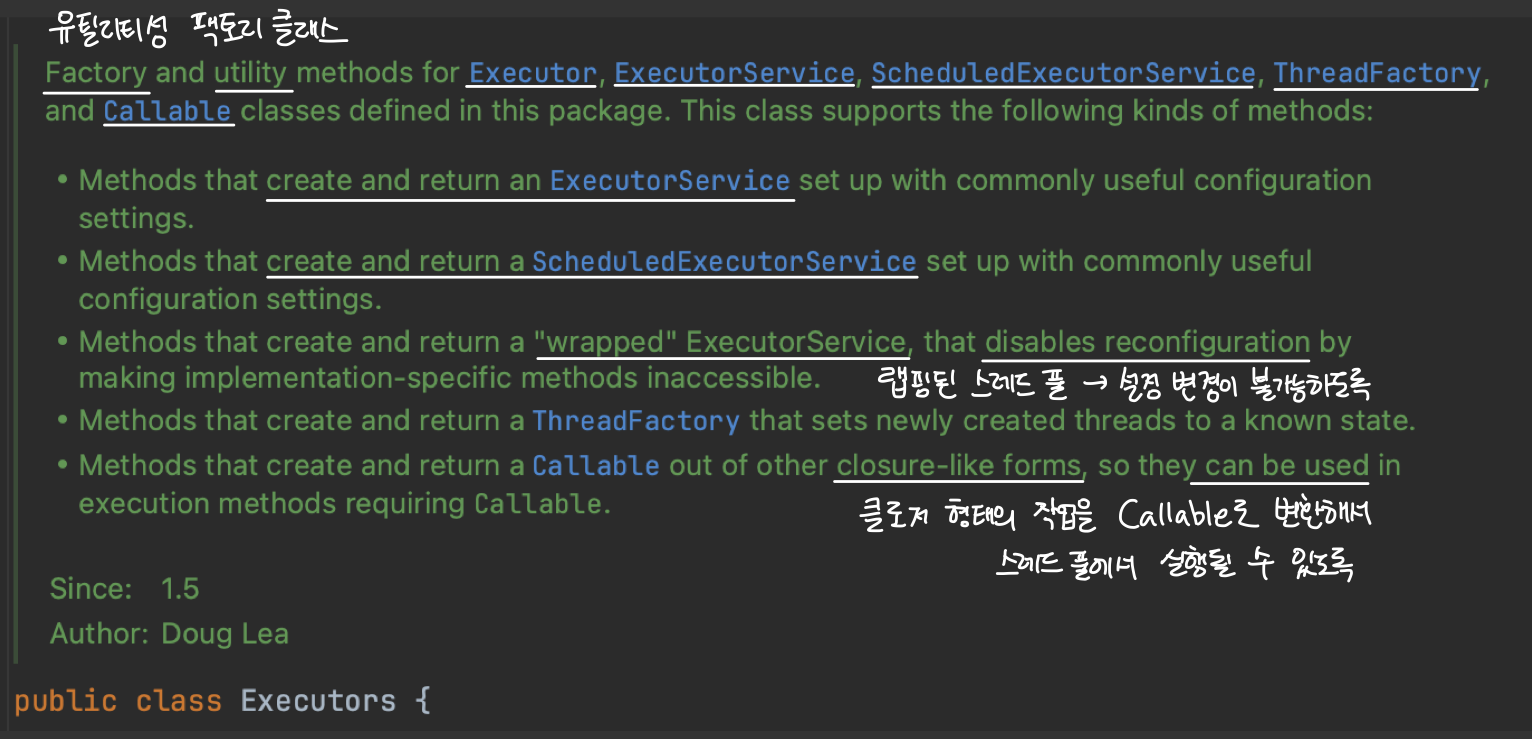
Executor 주요 API
고정 크기 스레드 풀
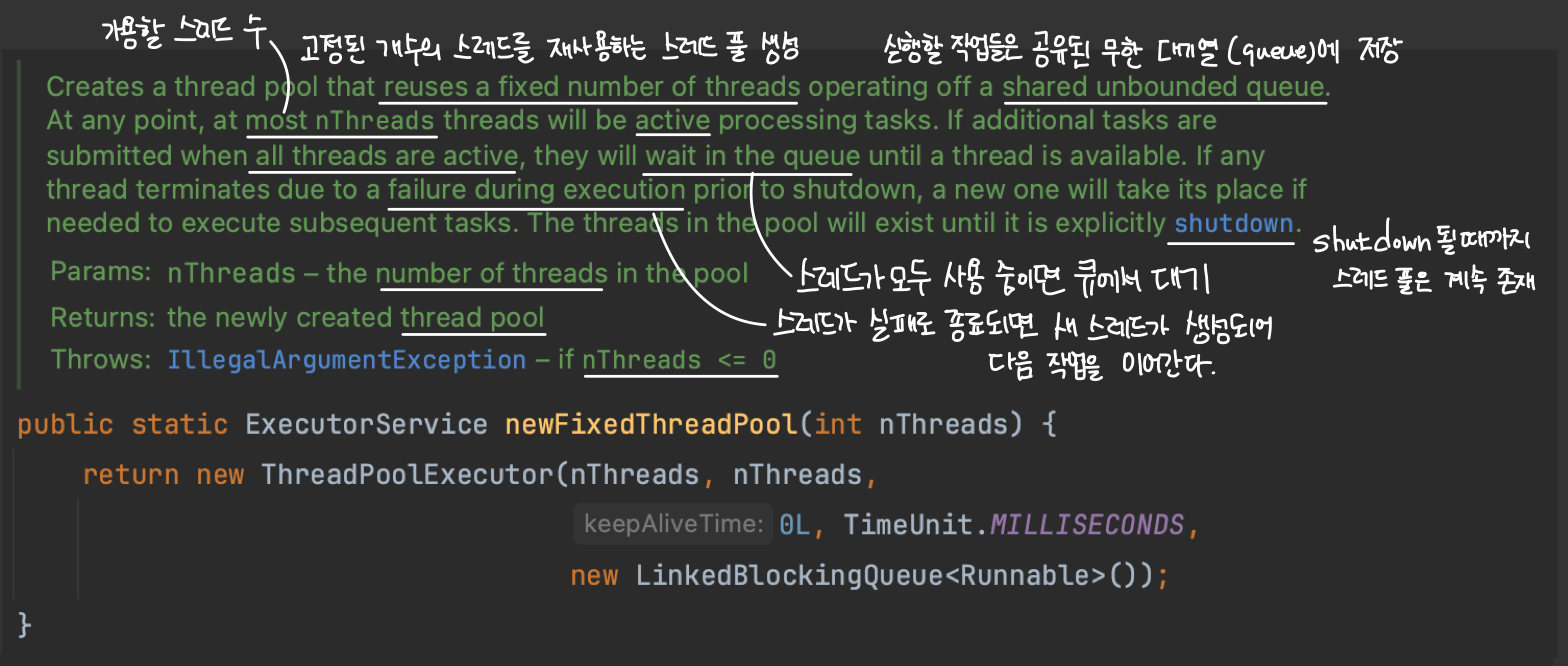
고정 크기의 스레드 풀을 생성할 수 있도록 newFixedThreadPool() 정적 팩토리 메서드를 제공합니다. 이 메서드를 사용하면 매개변수로 전달받은 nThread 만큼의 스레드 풀이 생성되고, 스레드가 모두 사용중일 경우 작업은 공유되는 무한한 크기의 대기 큐에 쌓아두고 처리합니다.
만약 스레드가 작업 중에 실패로 종료된다면 nThread 만큼의 고정 크기를 유지해야 하므로 새로운 스레드를 생성해 큐에 쌓인 대기 중인 작업을 처리합니다.
참고로 실패한 작업에 대한 재시도는 자동으로 해주지 않습니다. 필요하다면 별도의 관리가 필요하겠네욤
ThreadFactory를 사용해 스레드 생성 방식 커스텀하기
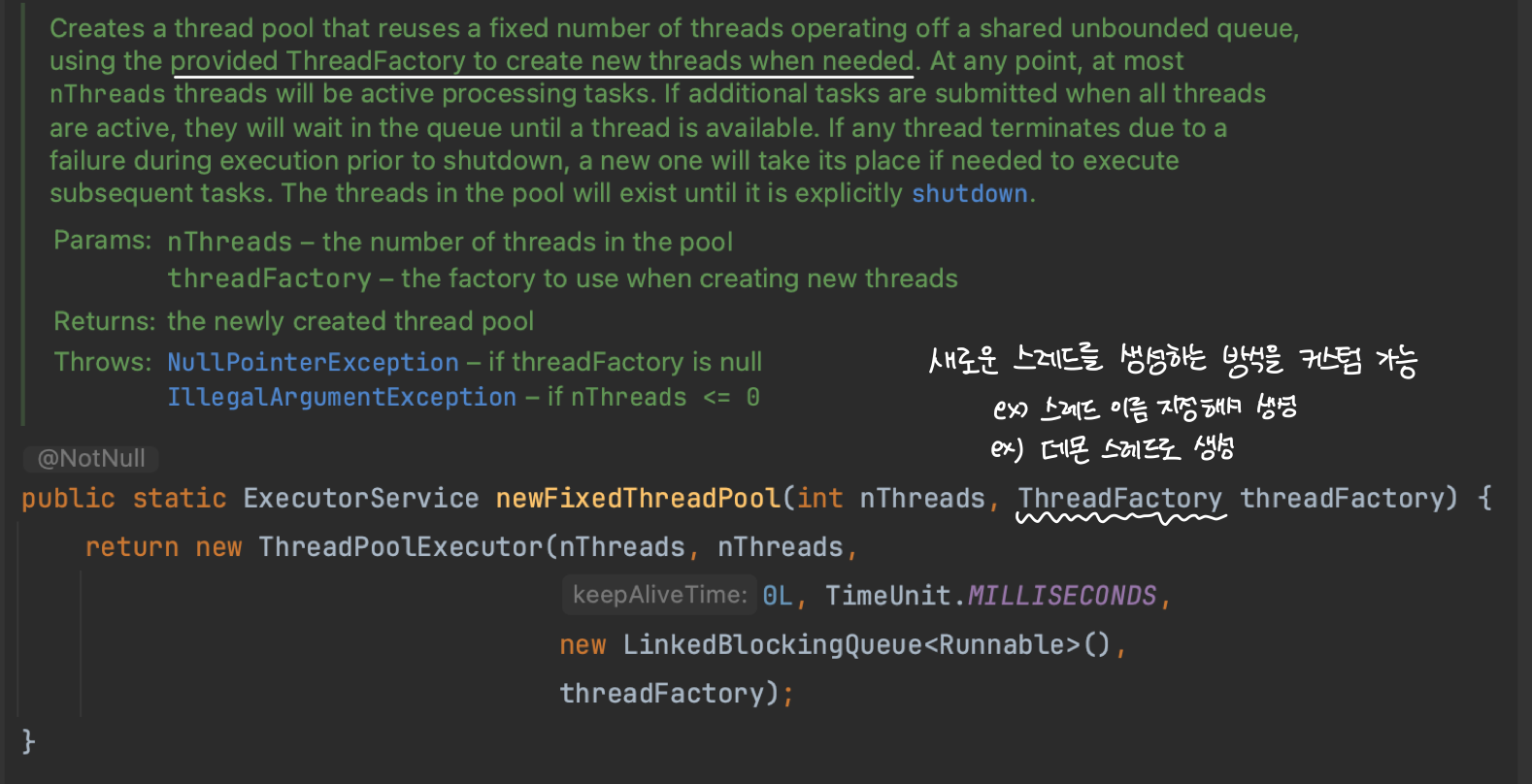
TreadFactory라는 팩토리 클래스를 사용하면 스레드 생성 방식을 커스텀할 수 있습니다. ThreadFactory는 스레드 생성과 관련된 세부 사항을 추상화해서 원하는 방식으로 스레드를 커스텀할 수 있도록 도와주는 팩토리 객체입니다.

new로 스레드 생성하는 하드 코딩을 피하고, 자유롭게 스레드 속성을 커스텀할 수 있어서 매우 편리합니다.
Executors는 이 TreadFactory를 간단하게 구현할 수 있는 DefaultThreadFactory 팩토리를 제공합니다. 이 팩토리는 새로운 스레드를 생성할 때 스레드 그룹, 이름, 우선순위 등을 자동으로 설정해주는 역할을 합니다.

고정된 스레드 풀을 생성하고 데몬 스레드로 로그 처리 예제
ThreadFactory를 통해 고정 크기의 스레드 풀을 생성하고 이 스레드 풀을 통해 데몬 스레드를 사용한 비동기 로그 처리를 구현하는 예제를 살펴봅시다.
package org.example.ch10.ex10;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
public class LogProcessing {
public static void main(String[] args) throws InterruptedException {
// 1. 커스텀 ThreadFactory 구현
ThreadFactory daemonThreadFactory = new ThreadFactory() {
private final AtomicInteger threadCount = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setDaemon(true); // 데몬 스레드로 설정
thread.setName("LogThread-" + threadCount.getAndIncrement());
return thread;
}
};
// 2. 고정된 크기의 스레드 풀 생성
ExecutorService logExecutor = Executors.newFixedThreadPool(5, daemonThreadFactory);
// 3. 로그 처리
for (int i = 0; i < 10; i++) {
final int taskId = i;
logExecutor.submit(() -> {
log("Processing log for task: " + taskId);
});
}
logExecutor.shutdown();
logExecutor.awaitTermination(1, TimeUnit.MINUTES); // 로그 처리 완료하도록 대기 걸어주기
System.out.println("Main application tasks complete.");
}
// 로그 처리 메서드
private static void log(String message) {
try {
Thread.sleep(500);
System.out.println(Thread.currentThread().getName() + ": " + message);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}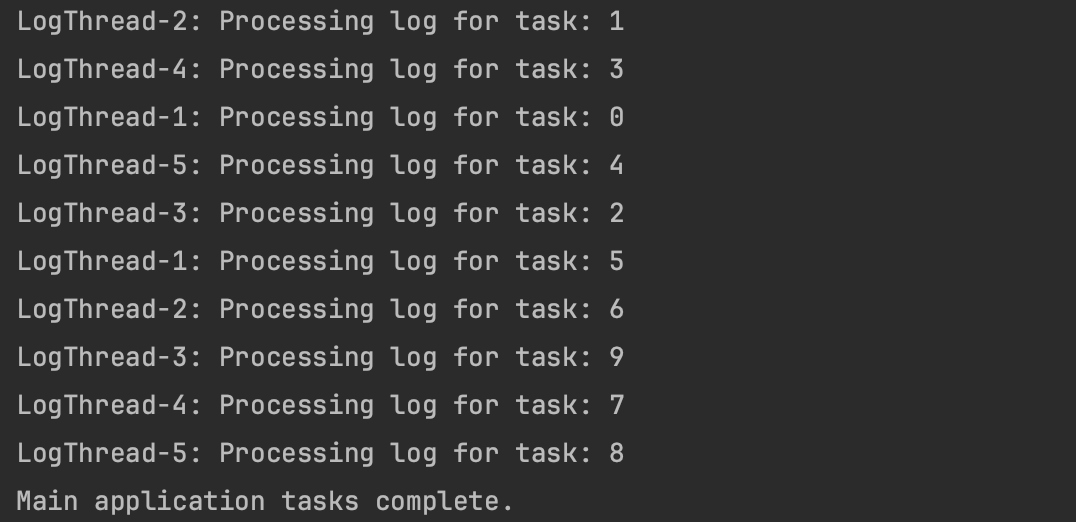
데몬 스레드는 백그라운드에서 실행되며, 메인 스레드가 종료되면 함께 종료되는 특징이 있습니다. 이를 통해 로그 처리 작업이 비동기로 진행되며, 메인 작업이 완료되면 백그라운드 작업이 종료되도록 설정했습니다.
이 방식은 로그 처리, 파일 모니터링, 비동기 알림 전송 등과 같은 백그라운드 작업에 매우 유용합니다. 데몬 스레드를 사용하면 메인 애플리케이션이 종료될 때 백그라운드 작업이 자동으로 종료되므로, 리소스 관리 측면에서 효율적입니다.
하지만 작업 대기 큐는 무한한 크기이므로 실제로 newFixedThreadPool()는 작업량이 일정하고 예측 가능한 경우에만 사용하는 것이 좋습니다. 혹은 스레드 수를 고정하기 때문에 리소스 사용을 제한해야 하는 경우에도 쓸 수 있습니다.
만약 트래픽이나 작업량이 예측 불가능하게 변동하는 경우엔 어떨까요?
지정한 스레드 수에 비해 너무 많은 작업이 큐에 쌓여 속도가 느려질 수도 있고, 그렇다고 또 스레드 수를 너무 많이 지정하면 그만큼 리소스를 너무 많이 써 성능 저하가 발생할 수 있습니다. 따라서 이런 경우에는 이후에 설명할 newCachedThreadPool()을 사용해 동적 크기 스레드 풀을 생성하는 것이 좋습니다.
동적 크기 스레드 풀
newCachedThreadPool() 정적 팩토리 메서드를 통해 동적 크기의 스레드 풀을 생성할 수 있습니다. 이 스레드 풀은 사용 가능한 스레드가 없을 때마다 새로운 스레드를 생성하여 작업을 처리합니다. 동기 큐(SynchronousQueue)를 사용하기 때문에, 작업이 대기하지 않고 스레드가 없으면 즉시 새로운 스레드를 생성해 작업을 실행합니다.
리소스 효율성을 극대화하기 위해, 60초 동안 사용되지 않은 스레드는 자동으로 종료되어 리소스에서 제거됩니다. 이로 인해 트래픽이 많을 때는 스레드가 동적으로 증가하여 작업 처리 속도를 높이고, 트래픽이 줄어들면 사용하지 않는 스레드들이 자동으로 종료되어 리소스를 최소화합니다.
따라서 짧고 빈번한 비동기 작업을 처리할 때 매우 적합합니다.

마찬가지로 ThreadFactory로 스레드 생성 방법을 커스텀할 수 있습니다.
동적 스레드 풀을 통해 트래픽 변화 대처하기
트래픽 변화에 따라 동적 스레드 풀을 통해 스레드 개수를 조절해 대처하는 예제를 살펴봅시다.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class TrafficSimulation {
public static void main(String[] args) throws InterruptedException {
// 1. 동적 스레드 풀 생성
ExecutorService executor = Executors.newCachedThreadPool();
ThreadPoolExecutor poolExecutor = (ThreadPoolExecutor) executor;
// 2. 트래픽이 몰리는 상황 시뮬레이션 (5개의 요청)
System.out.println("=== High Traffic: 5 requests ===");
for (int i = 0; i < 5; i++) {
final int taskId = i;
executor.submit(() -> {
processRequest(taskId);
});
}
// 3. 풀의 상태를 확인 (트래픽이 많은 상황)
monitorPoolState(poolExecutor);
// 4. 유휴 상태로 70초 대기 (유휴 스레드가 종료될 시간을 줌)
System.out.println("=== No Traffic: Waiting 70 seconds for idle threads to terminate ===");
TimeUnit.SECONDS.sleep(70);
// 5. 풀의 상태를 다시 확인 (유휴 스레드가 종료된 후)
monitorPoolState(poolExecutor);
// 6. 트래픽이 다시 몰리는 상황 시뮬레이션 (5개의 요청)
System.out.println("=== High Traffic: 5 more requests ===");
for (int i = 0; i < 5; i++) {
final int taskId = i;
executor.submit(() -> {
processRequest(taskId);
});
}
// 7. 풀의 상태를 확인 (트래픽이 많은 상황)
monitorPoolState(poolExecutor);
// 8. 스레드 풀 종료
executor.shutdown();
executor.awaitTermination(1, TimeUnit.MINUTES);
System.out.println("All tasks completed.");
}
// 스레드 풀 상태 확인
private static void monitorPoolState(ThreadPoolExecutor poolExecutor) {
System.out.println("=== ThreadPool Status ===");
System.out.println("Active threads: " + poolExecutor.getActiveCount());
System.out.println("Pool size: " + poolExecutor.getPoolSize());
System.out.println("Core pool size: " + poolExecutor.getCorePoolSize());
System.out.println("Maximum pool size: " + poolExecutor.getMaximumPoolSize());
System.out.println("=========================");
}
// HTTP 요청 시뮬레이션
private static void processRequest(int taskId) {
try {
Thread.sleep(2000); // 작업 처리 시간
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}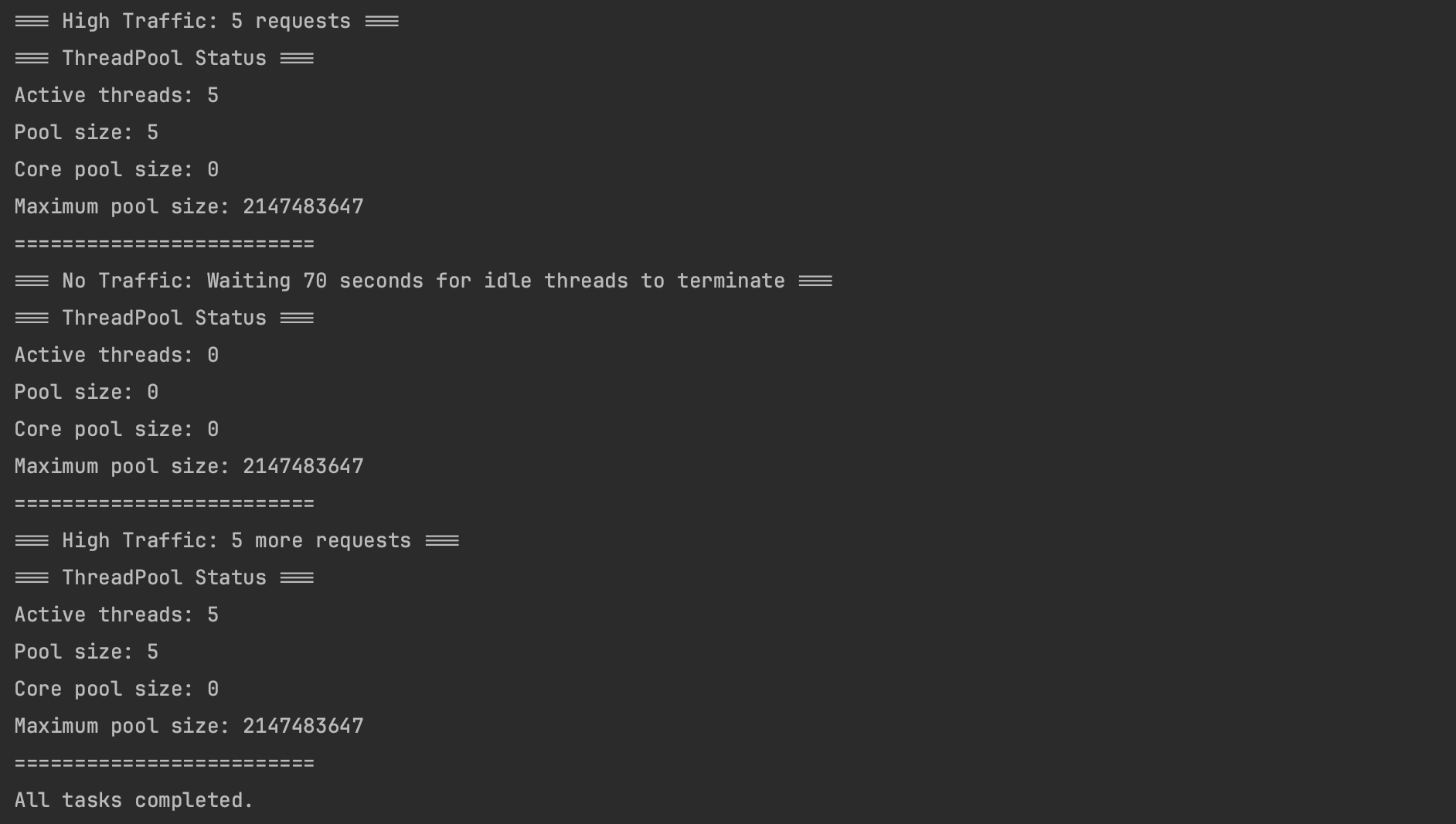
트래픽이 사라진 상태로 60초가 지나니까 스레드 풀의 가용 스레드 수가 5에서 0으로 줄어든 것을 확인할 수 있었고, 다시 트래픽이 발생하니까 새로운 스레드가 생성된 것까지 확인했습니다.
이처럼 동적 크기 스레드 풀을 활용하면, 요청량에 따라 유연하게 스레드를 생성하고 종료할 수 있습니다.
단일 크기 스레드 풀
단일 스레드 풀을 생성하는 newSingleThreadExecutor()는 newFixedThreadPool(1)과 유사하지만 스레드의 개수를 조정할 수 없고, 반드시 하나의 스레드로 하나의 작업씩 순차적으로 처리합니다.
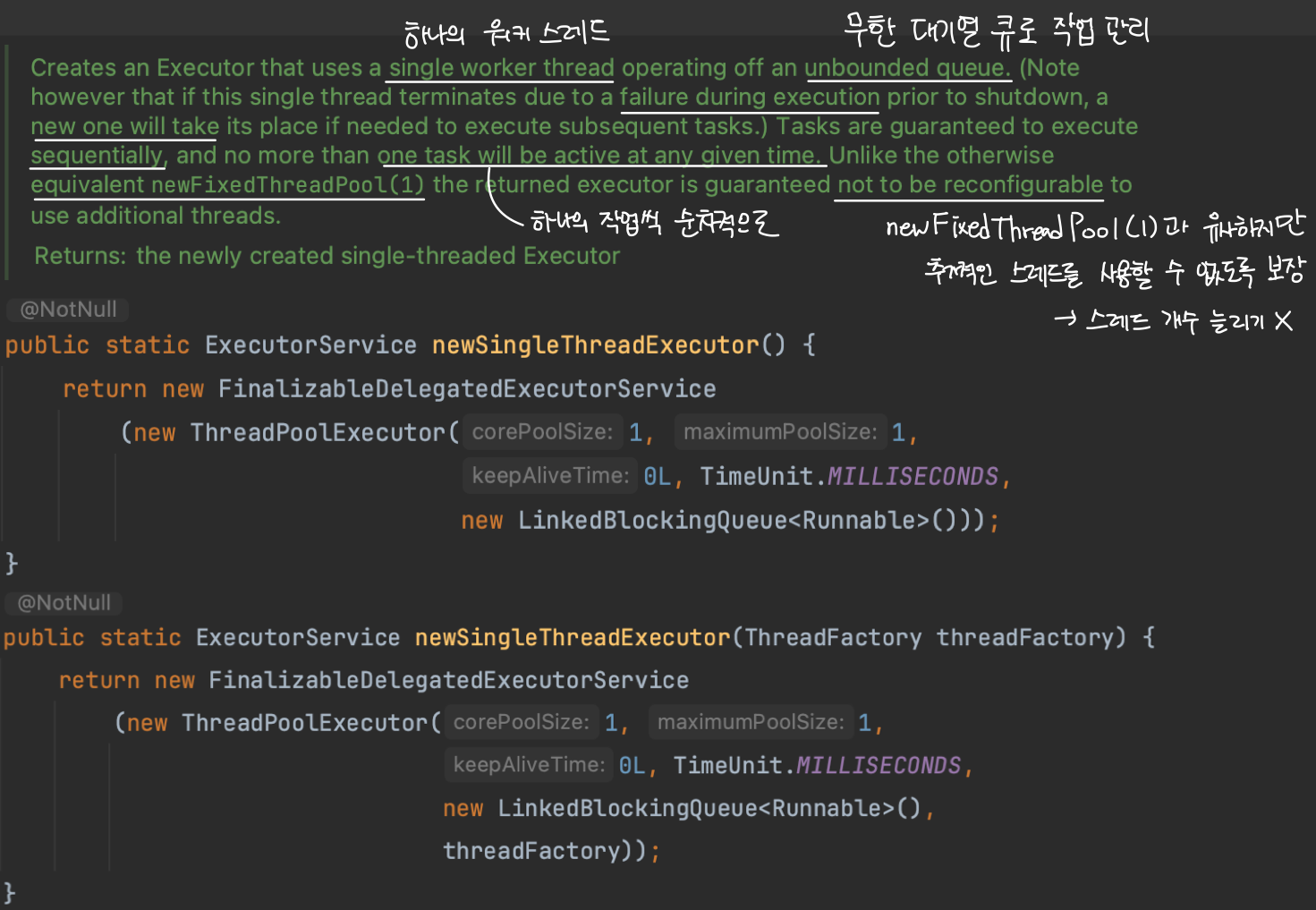
단일 스레드 풀을 사용하는 경우?
단일 스레드 풀은 동시에 하나의 작업만 처리하고, 순차적으로 실행하기 때문에 일관된 순서로 작업을 처리해야 할 때 유용합니다.
예를 들어 데이터베이스의 특정 레코드에 대한 순차적인 업데이트가 필요할 때 사용하거나, 공유 리소스에 접근해야 해서 경쟁 상태가 우려되는 경우 동기화 문제를 없애기 위해 사용할 수 있습니다.
순차적으로 기록되어야 하는 로그 시스템을 단일 스레드 풀로 구현해보자
로그는 보통 순차적으로 기록되어야 하고, 동시에 여러 스레드가 로그를 기록하면 race condition이 발생할 수 있습니다. 따라서 단일 스레드 풀을 사용해 순차적으로 로그를 기록하도록 구현해봅시다!
package org.example.ch10.ex10;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class LogProcessor {
// 단일 스레드 풀 생성
private final ExecutorService executor = Executors.newSingleThreadExecutor();
// 로그 기록 메서드
private void log(String message) {
executor.submit(() -> {
// 로그 파일에 쓰기 (시뮬레이션이므로 출력만 하자)
System.out.println(Thread.currentThread().getName() + " - 로그 기록: " + message);
});
}
// 로그 시스템 종료
private void shutdown() {
executor.shutdown();
}
public static void main(String[] args) throws InterruptedException {
LogProcessor logProcessor = new LogProcessor();
for (int i = 0; i < 10; i++) {
final int taskId = i;
String logMessage = "작업 " + taskId + " 처리";
logProcessor.log(logMessage);
}
// 로그 시스템 종료
logProcessor.shutdown();
logProcessor.executor.awaitTermination(1, TimeUnit.MINUTES);
System.out.println("모든 작업이 완료되었습니다.");
}
}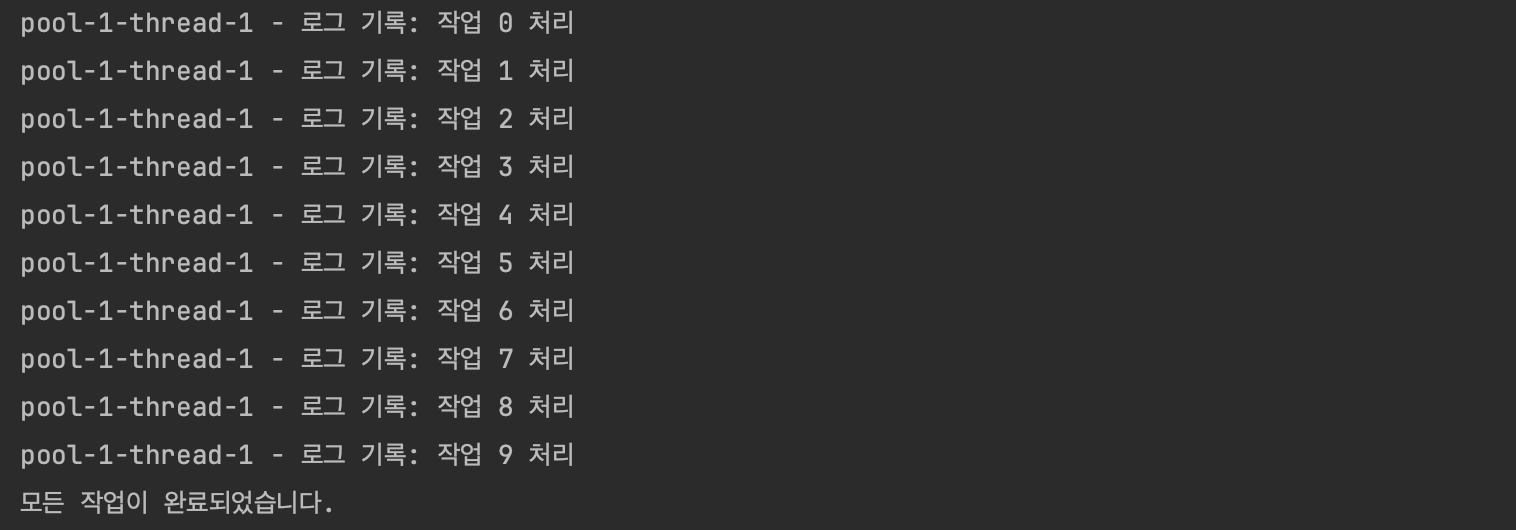
제출되는 순서대로 단일 스레드에서 순차적으로 작업을 처리하고, 로그를 기록하는 것을 확인할 수 있었습니다. 이처럼 단일 스레드 풀을 사용하면, 동시성 문제를 회피하면서 정확한 순서로 작업을 처리하고 로그를 남길 수 있습니다.
스케줄링 스레드 풀
주어진 지연 시간 후에 명령을 실행하거나 특정 주기를 가지고 반복적으로 실행할 수 있도록 newScheduledThreadPool() 정적 팩토리 메서드를 제공합니다. 이 때 corePoolSize를 지정해야 하는데 최소한으로 반드시 유지할 스레드의 수를 지정합니다.

또한, 이전에 살펴본 newSingleThreadExecutor()와 유사하게, newSingleThreadScheduledExecutor()를 사용하여 단일 스레드에서 스케줄링 작업을 처리할 수 있습니다. 이 메서드는 하나의 스레드만 사용해 스케줄된 작업을 처리하므로, 순차적으로 작업을 실행하며 경쟁 상태나 동시성 문제를 방지할 수 있습니다.
스케줄링 스레드 풀을 사용한 예약 이메일 발송 예제
스케줄링 스레드 풀을 사용해 예약한 시간에 메일을 발송하는 예제를 구현해봅시다.
우선 크기가 2인 스케줄링 스레드 풀을 생성합니다. 스레드 풀의 크기는 동시에 처리할 수 있는 작업의 수를 나타내는데, 여기서는 두 개의 이메일 발송 작업을 동시에 처리할 수 있도록 설정했습니다.
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(2);이메일 발송 작업들을 관리하기 위해 Map을 선언합니다. 이 맵은 ConcurrentHashMap으로 선언해서 여러 스레드에서 동시에 접근하더라도 안전하게 작업을 관리할 수 있게 합니다. 각 이메일 발송 작업을 이메일 ID로 식별하고, 이를 통해 예약된 작업을 쉽게 관리할 수 있습니다.
Map<String, ScheduledFuture<?>> scheduledEmails = new ConcurrentHashMap<>();이제 이메일 발송을 예약하는 메서드를 구현합니다. 메일의 예약 시점과 발송 시점 사이의 지연 시간을 계산해 그 시간이 지나면 자동으로 이메일이 발송되도록 합니다. 예약된 발송 시간을 입력받고, 현재 시간과의 차이를 계산해 schedule()로 작업을 예약합니다.
이 때 ScheduledFuture가 즉시 반환되면 그 값을 emailId와 함께 Map에 저장해주고, 스케줄링에 의해 메일 발송이 완료되면 Map에서 제거해줍시다.
public void scheduleEmail(String emailId, String email, String subject, String content, LocalDateTime sendTime) {
long delay = ChronoUnit.SECONDS.between(LocalDateTime.now(), sendTime);
if (delay > 0) {
System.out.println("이메일 발송 요청됨. " + delay + "초 후 발송 예정: " + email + " (ID: " + emailId + ")");
// 예약된 이메일 발송 작업 생성
ScheduledFuture<?> future = scheduler.schedule(() -> {
LocalDateTime actualSendTime = LocalDateTime.now(); // 실제 발송 시간
sendEmail(email, subject, content, sendTime, actualSendTime);
// 이메일 발송 후 맵에서 제거
scheduledEmails.remove(emailId);
}, delay, TimeUnit.SECONDS);
// 예약 작업을 추적하기 위해 맵에 저장
scheduledEmails.put(emailId, future);
} else {
System.out.println("발송 시간이 과거라서 발송할 수 없습니다.");
}
}실제로 이메일이 발송되는 로직은 출력으로 대체하겠습니다~
예약한 시간과 실제 발송한 시간, 그리고 두 시간의 차이를 출력해서 어느 정도의 오차로 예약된 메일이 발송되었는지 확인합시다.
private void sendEmail(String email, String subject, String content, LocalDateTime scheduledTime, LocalDateTime actualSendTime) {
System.out.println("이메일 발송 중: " + email);
System.out.println("제목: " + subject);
System.out.println("내용: " + content);
System.out.println("예약된 발송 시각: " + scheduledTime);
System.out.println("실제 발송 시각: " + actualSendTime);
System.out.println("예약된 시각과의 차이: " + ChronoUnit.SECONDS.between(scheduledTime, actualSendTime) + "초");
}예약된 이메일 발송 작업을 취소할 수 있는 기능도 추가할 수 있습니다.
작업이 ScheduledFuture이기 때문에 cancel()을 사용해 작업을 취소한 뒤 Map에서 제거해줍니다.
public void cancelScheduledEmail(String emailId) {
ScheduledFuture<?> future = scheduledEmails.get(emailId);
if (future != null) {
boolean cancelled = future.cancel(false);
if (cancelled) {
System.out.println("이메일 발송 취소됨: " + emailId);
scheduledEmails.remove(emailId);
} else {
System.out.println("이메일 발송 취소 실패: " + emailId);
}
} else {
System.out.println("이메일 ID를 찾을 수 없습니다.: " + emailId);
}
}이제 메인에서 이메일 3개를 10초 뒤, 20초 뒤, 30초 뒤로 예약하고 두번째 메일만 취소해보도록 하겠습니다!
public static void main(String[] args) throws InterruptedException {
EmailScheduler emailScheduler = new EmailScheduler();
// 현재 시각에서 10초, 20초, 30초 후에 이메일 발송 예약
LocalDateTime now = LocalDateTime.now();
emailScheduler.scheduleEmail("email1", "user1@example.com", "안녕하세요", "첫 번째 예약 메일입니다.", now.plusSeconds(10));
emailScheduler.scheduleEmail("email2", "user2@example.com", "안녕하세요", "두 번째 예약 메일입니다.", now.plusSeconds(20));
emailScheduler.scheduleEmail("email3", "user3@example.com", "안녕하세요", "세 번째 예약 메일입니다.", now.plusSeconds(30));
// 15초 후 두 번째 이메일 발송 취소
Thread.sleep(15000);
emailScheduler.cancelScheduledEmail("email2");
// 40초 후 시스템 종료
Thread.sleep(40000);
emailScheduler.shutdown();
System.out.println("이메일 발송 시스템 종료.");
}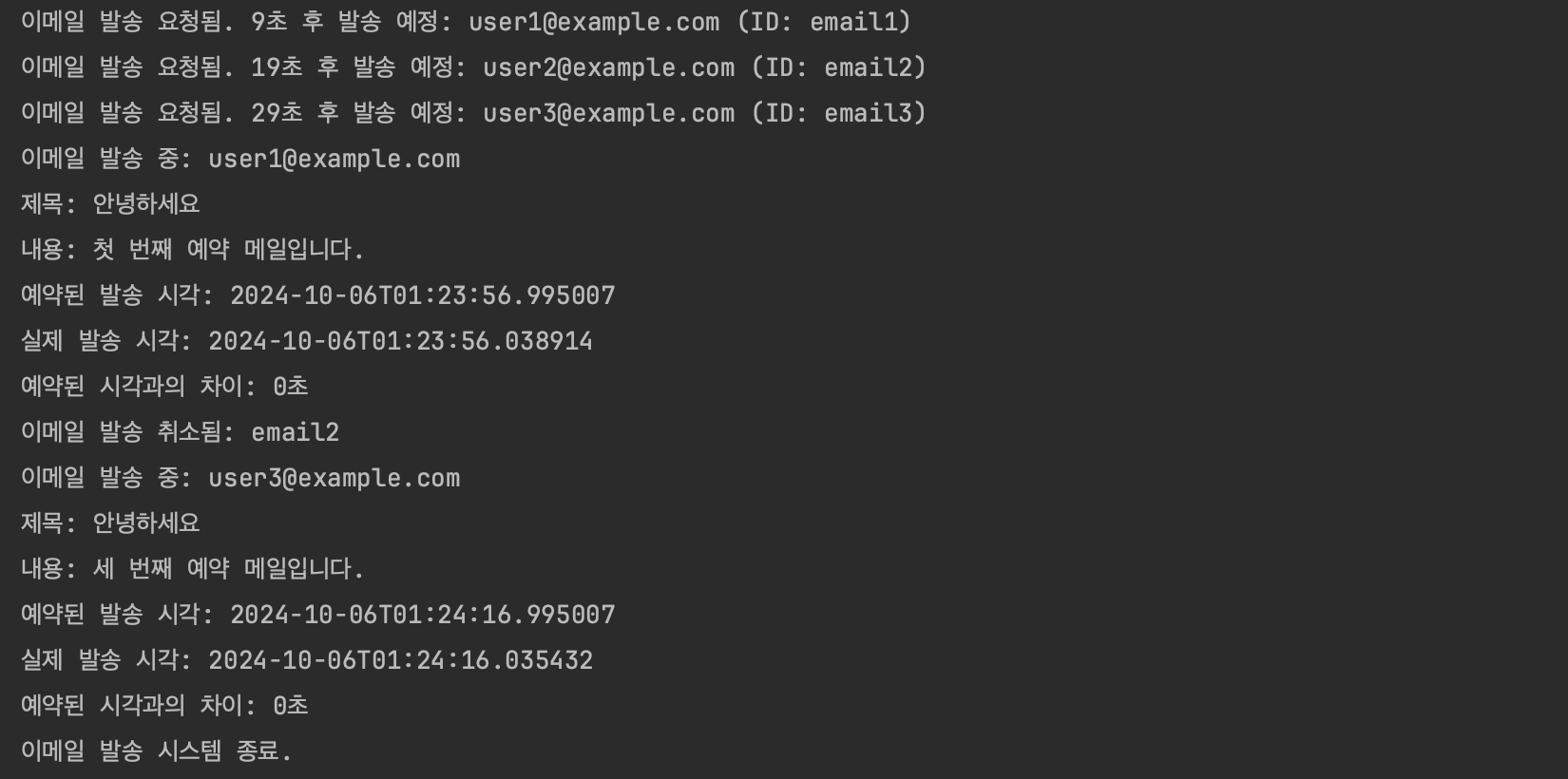
예약된 시간에 가깝게 잘 발송되고 있네요 ㅎㅎ
이처럼 스케줄링 스레드 풀을 사용하면 예약된 시간에 정확하게 작업을 실행할 수 있고, 비동기 작업 처리를 간편하게 관리할 수 있습니다. 이메일 발송처럼 지연된 작업을 처리하거나 주기적인 작업이 필요한 경우, 스케줄링 스레드 풀을 활용하면 효율적이고 안정적인 시스템을 구축할 수 있습니다.
다음 시간에는 스레드 풀 내부에서 실제로 ThreadPoolExecutor가 어떻게 생성되고 관리되는지, 그리고 스레드 풀이 어떻게 동작하는지 내부 구현을 뜯어보고 분석해보겠습니다.
감사합니다 😋
참고
- https://inpa.tistory.com/entry/GOF-%F0%9F%92%A0-%ED%8C%A9%ED%86%A0%EB%A6%AC-%EB%A9%94%EC%84%9C%EB%93%9CFactory-Method-%ED%8C%A8%ED%84%B4-%EC%A0%9C%EB%8C%80%EB%A1%9C-%EB%B0%B0%EC%9B%8C%EB%B3%B4%EC%9E%90
- 정수원님의 자바 동시성 프로그래밍 [리액티브 프로그래밍 Part.1] 강의
- https://refactoring.guru/ko/design-patterns/factory-method
