
SQL
Structured Query Language의 줄임말로써, 번역하면 구조적인 Query언어를 의미
쿼리(Query)
직역하면 "질의문" 이라는 뜻
조금더 풀어 쓰자면 저장되어져 있는 정보를 필터하기 위한 질문
SQL 쿼리문
CREATE DATABASE
- 데이터 베이스를 새로 생성할 때 사용.
기본문법
CREATE DATABASE [데이터베이스 명]
예시
CREATE DATABASE testDBDROP
- 데이터 베이스 자체를 삭제할때 사용
- 테이블을 삭제 할때도 사용가능
기본문법
DROP DATABASE [데이터베이스 명]
DROP TABLE [테이블명]
예시
DROP DATABASE testDB;
//데이터 베이스 자체를 삭제
DROP TABLE Persons;
//해당 테이블만 삭제.ALTER
- 테이블에 컬럼을 추가 및 삭제할때 사용
기본문법
ALTER TABLE [테이블명] ADD [추가할 컬럼이름] 데이터형(데이터크기) 컬럼속성
ALTER TABLE [테이블명] DROP COLUMN [삭제할 컬럼이름]
예시
ALTER TABLE Persons
ADD Birthday DATE;
//Persons라는 테이블에 Birthday라는 컬럼을 만듬 이때 속성은 DATE임.
ALTER TABLE Persons
DROP COLUMN Birthday;
//Persons라는 테이블의 Birthday라는 컬럼을 날려버림.
TRUNCATE
- DELETE와 다르게 테이블에 있는 데이터를 한번에 제거
- 테이블이 최초 생성되었을 당시의 Storage만 남김(CREATE TABLE 한 직후의 상태가 됨)
- DROP과의 차이점은 DROP은 테이블을 완전히 날려버리지만 TRUNCATE는 테이블이 남기 때문에 재사용 가능
기본문법
TRUNCATE TABLE [테이블명]
CRAEAT TABLE
- 데이터베이스에 테이블을 새롭게 추가할 때 사용
- CREATE DATABASE로 데이터베이스를 생성한 후, use [데이터베이스]로 해당 데이터 베이스를 사용한다고 선언한 후 CREAT TABLE [테이블명]을 이용하여 테이블을 만듬
- 테이블을 만들시에는 필드(컬럼)또한 같이 만들어 주어야함.
기본문법
CREATE TABLE 테이블명
예시
CREATE TABLE Persons(
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);
//PersonID라는 필드를 만듬. 해당 필드의 타입은 int(숫자임)
//LastName과 나머지 필드들은 문자열이며 최대 255자리수까지 입력가능.Select
- SELECT는 데이터셋에 포함될 특성을 특정함
예시
SELECT DISTINCT Country FROM Customers;
//Customers 테이블에서 Country라는 필드만 중복없이 출력해라
SELECT City FROM Customers;
//Customers 테이블에서 City라는 필드만 출력해라
SELECT* FROM Customers;
//Customers 테이블에서 모든 필드를 다 출력해라From
- 테이블과 관련한 작업을 할 경우 반드시 입력을 해야함.
FROM 뒤에는 결과를 도출해낼 데이터베이스 테이블을 명시
Distinct
- 데이터의 중복을 제거 할 때 사용
- select절에 distinct 키워드만 명시하면 되므로 쿼리문이 복잡하지 않고 간결
- 유니크한 값을 받고 싶을 때에는 SELECT DISTINCT 를 사용
예시
SELECT DISTINCT Country FROM Customers;
//Customers 테이블에서 Country라는 필드만 중복없이 출력해라Where
- 필터 역할을 하는 쿼리문 WHERE은 선택적으로 사용할 수 있으며 쉽게 이야기하면 조건문이다.
예시
SELECT * FROM Customers
WHERE City= 'Berlin';
//Customers라는 테이블에서 City라는 필드명에 'Berlin'이라는 값이 들어가 있는것의 row를 전부다 출력하라.
SELECT * FROM Customers
WHERE NOT City= 'Berlin';
//Customers라는 테이블에서 City라는 필드명에 'Berlin'이라는 값이 들어가 있는것만 빼고 모든 값을 전부다 출력하라.
SELECT* FROM Customers
WHERE City = 'Berlin'
AND PostalCode = 12209;
//Customers라는 테이블에서 City라는 필드명에 'Berlin'이라는 값과 PostalCode라는 필드명에 12209라는 값이 있는 것만 출력하라.
SELECT* FROM Customers
WHERE City = 'Berlin'
OR PostalCode = 12209;
//Customers라는 테이블에서 City라는 필드명에 'Berlin'이라는 값과 PostalCode라는 필드명에 12209라는 값이 하라나도 있다면 해당되는 것은 다 출력하라.Order By
- 데이터 결과를 어떤 기준으로 정렬하여 출력할지 결정 ORDER BY는 선택적으로 사용할 수 있다.
- Defalt값은 ACS(오름차순) 이며 DESC(내림차순)으로 설정도 가능하다.
- Order By의 경우 다중으로 사용이 가능하며 이럴 경우 , 로 구분을 해주어야 함.
예시
SELECT * FROM Customers
ORDER BY City ;
//Customer라는 테이블에서 City라는 필드명의 값이 있는것들을 오름차순으로 출력
SELECT * FROM Customers
ORDER BY City DESC;
//Customer라는 테이블에서 City라는 필드명의 값이 있는것들을 내림차순으로 출력
SELECT * FROM Customers
ORDER BY Country, City;
//우선 Country를 기준으로 오름차순으로 정렬을 한번 한 후, 그 값을 바탕으로 City를 기준으로 오름차순으로 정렬함. 두번째 정렬 에서 Country값의 순서는 변하지 않음. 오직 City의 순서만 변경
Insert
- 테이블에 데이터를 추가할 수 있다.
- insert다음에는 into가 따라옴.
기본구조
INSERT INTO 테이블 이름 (column,column, ...)
VALUE (값1, 값2, ...)
예시
INSERT INTO Customers
(
CustomerName,
Address,
City,
PostalCode,
Country
)
VALUES(
'Hekkan Burger',
'Gateveien 15',
'Sandnes',
'4306',
'Norway'
)
;
//CustomerName이라는 column에 'Hekkan Buger'를 추가
//나머지도 동일, Null
- 내가 보려고하는 필드의 값이 Null인지 아닌지 확일할 때 사용.
- null인지 아닌지 확인하기 위해서는 IS Null을 사용해야함.
- 만약 null이 아닌것만 확인해보려면 IS NOT Null을 입력하면됨
예시
SELECT * FROM Customers
WHERE PostalCode IS NULL;
//PostalCode라는 필드에 NUll이 있다면 해당 row를 모두 출력
SELECT * FROM Customers
WHERE PostalCode IS NOT NULL;
//PostalCode라는 필드의 값이 NULL이 아니라면 해당 row를 모두 출력Update
- 테이블에 데이터를 수정할때 사용
- 보통 UPDATE와 SET는 하나의 세트임
기본형태
UPDATE [테이블] SET [column] = '변경할값' WHERE [조건]
조건이 없는 경우에는 테이블에 있는 열 전체가 변경할 값으로 UPDATE됨.
예시
UPDATE Customers
SET City = 'Oslo';
//Customers라는 테이블의 City라는 column의 모든값을 Oslo로 바꾼다.
UPDATE Customers
SET City = 'Oslo'
WHERE Country = 'Norway';
//Country가 'Norway'일 경우 City를 'oslo'로 변경한다.
UPDATE Customers
SET City = 'Oslo',
Country = 'Norway'
WHERE CustomerID = 32;
//CustomerID가 32이면 County는 Norway로 City는 Oslo로 변경한다.
Delete
- 테이블에서 행을 제거하기위해 delete를 사용
- delete의 경우 WHERE(조건문)으로 지정해준 것의 모든 행을 제거하며 만약 조건을 지정해주지 않는다면 모든 행을 다 삭제 해버림
- DELETE의 경우에는 FROM으로 어느 테이블을 지울것인지 기재를 해야함.
기본형태
DELETE FROM [테이블] WHERE [조건]
예시
DELETE FROM Customers
WHERE Country = 'Norway';
//Country가 Norway인 행을 삭제.
DELETE FROM Customers;
//Customers의 테이블에서 모든 행을 삭제.집계함수 MIN()
- 매개변수로 주어진 column내에서 가장 작은 값을 반환
- 주로 SELECT구문과 함께 사용
기본형태
SELECT MIN(column) FROM [테이블명]
예시
SELECT MIN(Price)
FROM Products;
//Price column중 가장 낮은 값을 반환
집계함수 MAX()
- 매개변수로 주어진 column내에서 가장 큰 값을 반환
- 주로 SELECT구문과 함께 사용
기본형태
SELECT MAX(column) FROM [테이블명]
예시
SELECT MAX(Price)
FROM Products;
//Price column중 가장 큰 값을 반환집계함수 COUNT()
- 테이블 전체의 행 숫자를 알고 싶다면 COUNT(*)
- 특정 column의 숫자를 확인하려면 COOUNT(column명)
- 만약 특정 컬럼의 값이 null이 있다면 count세지 않음.
기본형태
SELECT COUNT() FROM [테이블명] WHERE 조건식
예시
SELECT * FROM Products
WHERE Price = 18.00;
//Products 테이블에서 Price가 18.00인것을 반환
SELECT COUNT(*) FROM Products
WHERE Price = 18.00;
//Products 테이블에서 Price가 18.00인 행의 숫자를 알려줌 이때 column명은 COUNT(*)집계함수 AVG()
- 평균을 계산해주는 함수
기본형태
SELECT AVG(column) FROM [테이블명]
예시
SELECT AVG(Price)
FROM Products;
//Products테이블의 Price 컬럼의 모든 값의 평균을 냄 이때 컬럼명은 AVG(price)집계함수 SUM()
- 특정 컬럼의 합을 계산해주는 함수
기본형태
SELECT SUM() FROM [테이블명]
예시
SELECT SUM(Price)
FROM Products;
//products테이블의 price컬럼의 모든 값을 더한 결과를 알려줌 이때 컬럼명은 SUM(Price)Like
- WHERE절에 주로 사용하며 부분적으로 일치하는 컬럼을 찾을 때 사용
- A%(A로 시작하는 문자 찾기) , %A%(A를 포함하는 문자 찾기) , %A(A로 끝나는 문자 찾기) , A_(A로 시작하는 두글자 문자 찾기)
기본형태
SELECT * FROM [테이블명] WHERE LIKE [조건]
예시
SELECT * FROM Customers
WHERE City LIKE 'a%';
//City라는 컬럼에서 a로 시작하는 열을 반환
SELECT * FROM Customers
WHERE City LIKE '%a';
//City라는 컬럼에서 a로 끝나는 열을 반환
SELECT * FROM Customers
WHERE City LIKE '%a%';
//City라는 컬럼에서 a를 포함하는 열을 반환
SELECT * FROM Customers
WHERE City LIKE 'a%b';
//City라는 컬럼에서 a로 시작하로 b로 끝나는 열을 반환
SELECT * FROM Customers
WHERE City NOT LIKE 'a%';
//City라는 컬럼에서 a이외의 알파뱃으로 시작하는 열을 반환
SELECT * FROM Customers
WHERE City LIKE '_a%';
//City의 두번째 글자가 a인 열을 반환
SELECT * FROM Customers
WHERE City LIKE '[acs]%';
//City의 첫번째 글자가 a or c or s 인 열을 반환
SELECT * FROM Customers
WHERE City LIKE '[a-f]%';
//City의 첫번째 글자가 a~f인 경우 해당 열을 반환
SELECT * FROM Customers
WHERE City LIKE '[!acf]%';
//City의 첫번째 글자가 a,c,f가 아닌경우 해당 열을 반환
IN
- WHERE절 내에서 특정값 여러개를 선택하는 SQL 연산자
- 괄호안의 값중 일치하는 것이 있으면 true
기본문법
SELECT * FROM [테이블명] WHERE [컬럼명] IN(값,값)
예시
SELECT * FROM Customers
WHERE Country IN ('Norway','France');
//Country의 값이 Norway이거나, France인 값이 있는 열을 반환 둘중에 하나라도 있으면 반환
SELECT * FROM Customers
WHERE Country NOT IN('Norway', 'France');
//Country의 값이 Norway, France가 아닌 열을 반환 Between
- 번역하면 무엇무엇 사이에 라는 뜻이므로 특정한 범위나 값 사이에 있는 값을 가져오라는 것
- BETWEEN A AND B : A와 B사이의 내용을 검색해서 가져오라는 것
기본문법
SELECT * FROM [테이블] WHERE [컬럼] BETWEEND A AND B
예시
SELECT * FROM Products
WHERE Price BETWEEN 10 AND 20;
//Price라는 컬럼중 10~20사이에 있는 값을 반환해라 이때 1과 20도 포함
SELECT * FROM Products
WHERE Price NOT BETWEEN 10 AND 20;
//Price라는 컬럼에서 10~20사이에 있지 않은 열을 반환
SELECT * FROM Products
WHERE ProductName BETWEEN 'Geitost' AND 'Pavlova';
//productName에서 이름이 Geitost와 Pavlova사이에 있는 열을 반환 (오름차순)
Alias (as)
- 별칭이라고도하며 값에 별칭을 주어 접근을 별칭 형태로 할 수 있도록 하는것.
- 대표적으로 알아보기 힘든 칼럼에 AS를 많이 사용함
예시
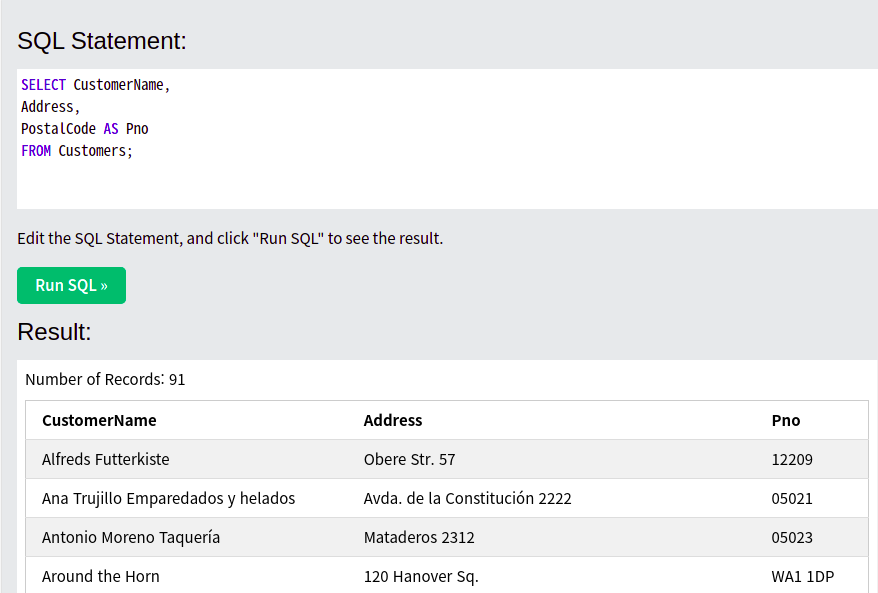
SELECT CustomerName,
Address,
PostalCode AS Pno
FROM Customers;
//기존 컬럼이 PostalCode이지만 간결하고 알기쉽게 하기위해 Alias를 사용하여 Pno로 변경 아래 사진 참조하면 이해가 더 간결
SELECT * FROM Customers AS Consumers;
//FROM도 Customers라고 쓰기 싫으니 Consumers로 변경해서 사용이 가능.
Join
- 둘 이상의 테이블을 연결해서 데이터를 검색하는 방법
- 연결하려면 테이블들이 적어도 하나의 공통된 컬럼이 있어야함.
Join의 종류
1. INNER JOIN : 내부 조인(교집합)
2. LEFT/ RIGHT JOIN -> 부분 집합
아래 블로그 글을 참조하면 더 이해가 잘됨.
https://pearlluck.tistory.com/46
아래유튜브 35강,36강을 봐도 이해하는데 도움이 많이 됨.
https://www.youtube.com/watch?v=NAuHvZDU15M&t=31s
예시
SELECT *
FROM Orders LEFT JOIN Customers
ON Orders.CustomerID = Customers.CustomerID;
//Orders를 기준으로 Customers와 Left조인을 하였으며 이때 기준은 각각의 CustomerID라는 컬럼임. 최종적으로는 Orders와 JOIN이 공통적으로 가지고 있는것과 Orders가 독자적으로 가지고 있는것만 합친 후 반환 합쳐질때 customers에만 독자적으로 있는 부분은 null처리됨.
SELECT *
FROM Orders INNER JOIN Customers
ON Orders.CustomerID=Customers.CustomerID;
//INNER조인으므로 Orders와 Customers의 CustomerID가 공통으로 들어가 있는것만 합친 후 반환
SELECT *FROM Orders
RIGHT JOIN Customers
ON Orders.CustomerID=Customers.CustomerID;
//LEFT 조인과 반대
Group By
- 그룹화하여 데이터 조회
- Count함수로 데이터를 조회할 경우 전체 갯수만 가져오게 되는데 유형별로 갯수를 알고 싶을때 해당 컬럼에 GROUP BY를 사용하면 유형별로 갯수를 알 수 있음.
기본 문법
SELECT 컬럼 FROM 테이블 GROUP BY 그룹화할 컬럼
예시
SELECT Count(CustomerID),Country
FROM Customers GROUP BY Country;
//customers라는 테이블의 customerID라는 컬럼의 수를 Count로 나타내고 GROUP BY를 사용하여 동일한 Country가 몇개씩 있는지를 나타냄. 여기서 추가로 SELECT Country를 하는 이유는 사용하지 않으면 어느나라가 몇번씩 Count가 되었는지 눈으로 확인하기 어렵기 때문.
SELECT COUNT(CustomerID),Country
FROM Customers
GROUP BY Country
ORDER BY
COUNT(CustomerID) DESC;
//위와 동일하지만 Order BY를 사용해서 Count가 가장 많은 것부터 내림차순으로 정렬하게끔 수행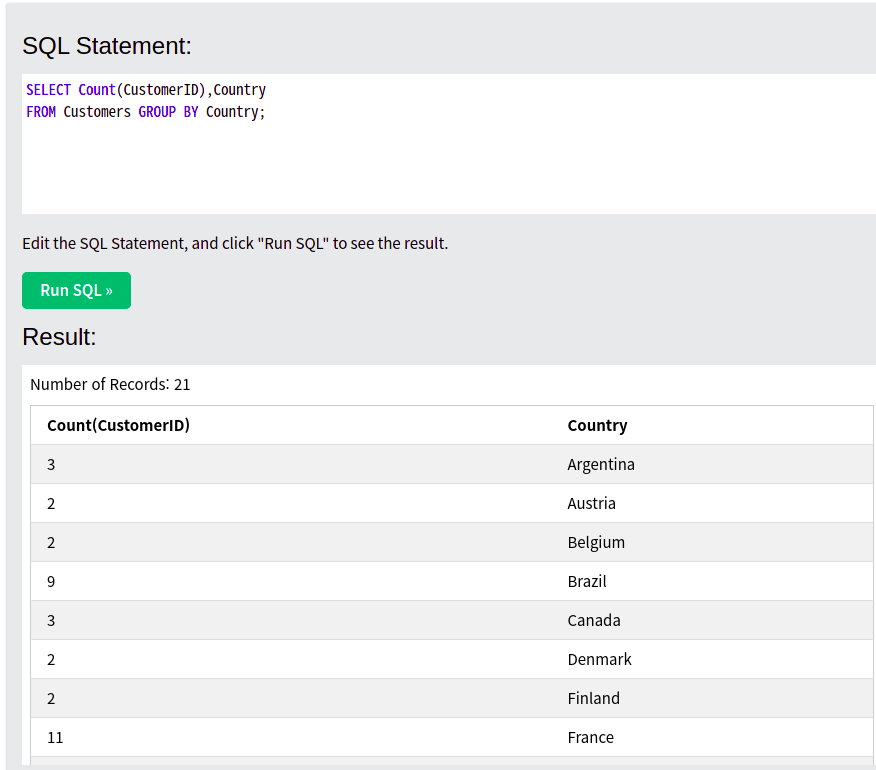
아래 유튜브 30강을 보면 더 이해가 잘됨
https://www.youtube.com/watch?v=zf4XyeifrqI
참조:https://www.w3schools.com/sql/exercise.asp?filename=exercise_database7
https://www.youtube.com/watch?v=zf4XyeifrqI
https://pearlluck.tistory.com/46
