1. Cumulative Gain (CG)
CG는 상위 p개의 추천 결과들의 관련성()을 합한 누적값을 의미한다.
은 관련이 있는지 없는지에 따라 0 또는 1의 Binary 값을 갖거나, 문제에 따라 세분화된 값을 가질 수 있다.
CG 는 상위 p 개의 추천 결과들을 모두 동일한 비중으로 계산하기 때문에 순서를 고려해 계산하는 DCG 보다는 사용 빈도가 적다.
2. Discounted Cumulative Gain (DCG)
(1)
(2)
DCG는 CG에서 랭킹 순서에 따라 점점 비중을 줄여가는(Discounted) 관련도를 계산하는 방법이다.
랭킹 순서에 대한 로그함수를 분모에 두면, 하위권으로 갈 수록 같은 대비 작은 DCG 값을 갖게 하여 하위권 결과에 패널티를 주는 방식이다.
기본적인 형태는 (1)이고, 랭킹의 순서보다 관련성에 더 비중을 주고싶은 경우 (2)를 사용하며
이 Binary 값이면 두 식이 같아진다.
특정 순위 까지는 discount를 하지 않는 방법 등의 다양한 변형식을 사용하기도 한다.
3. Normalized Discounted Cumulative Gain (nDCG)
nDCG는 랭킹 기반 추천 시스템에 주로 쓰이는 평가지표이다.
관련성이 높은 것을 순서대로 예측하는 모델인 검색 엔진, 영상 및 음악 추천에서 주로 사용한다.
검색 엔진은 특정 키워드를 검색하면 상위부터 순서대로 개의 검색 결과를 보여주며, 키워드와 관련성이 높은 검색 결과를 순서대로 노출시키는게 목표이다.
따라서 검색 엔진의 평가는 해당 관련성이 높은 결과를 상위권에 노출시켰는지를 기반으로 만들어져야 하기 때문에 nDCG를 주로 사용한다.
(3)
(4)
크기 가 길어질수록 누적 합인 DCG는 커지게된다. 따라서 p 길이에 상관없이 일정 스케일의 값을 가지도록 normalize가 필요하다.
(3)은 DCG를 IDCG (Ideal DCG) 를 이용해 정규화한 nDCG이다.
(4)의 IDCG는 이 큰 순서대로 재배열한 후 개를 선택한 에 대해서 DCG를 계산한 결과이다. 이는 선택된 개 결과로 가질 수 있는 가장 큰 DCG 값을 의미한다.
DCG 가 IDCG 와 같으면 nDCG 는 1을 가지고, 이 모두 0이라면 nDCG 는 0을 가지게되어
nDCG는 0~1로 normalize 된다.
4. DCG와 nDCG 비교
- DCG 는 값이 다르면 DCG 값 자체로 성능의 비교를 할 수 없다.
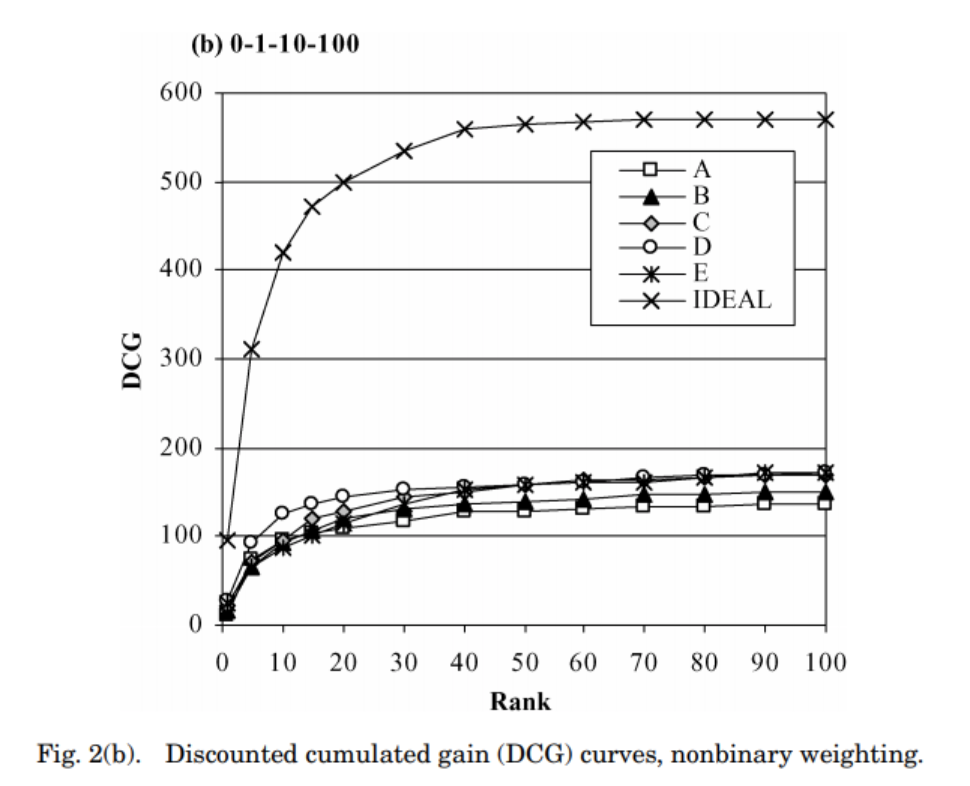
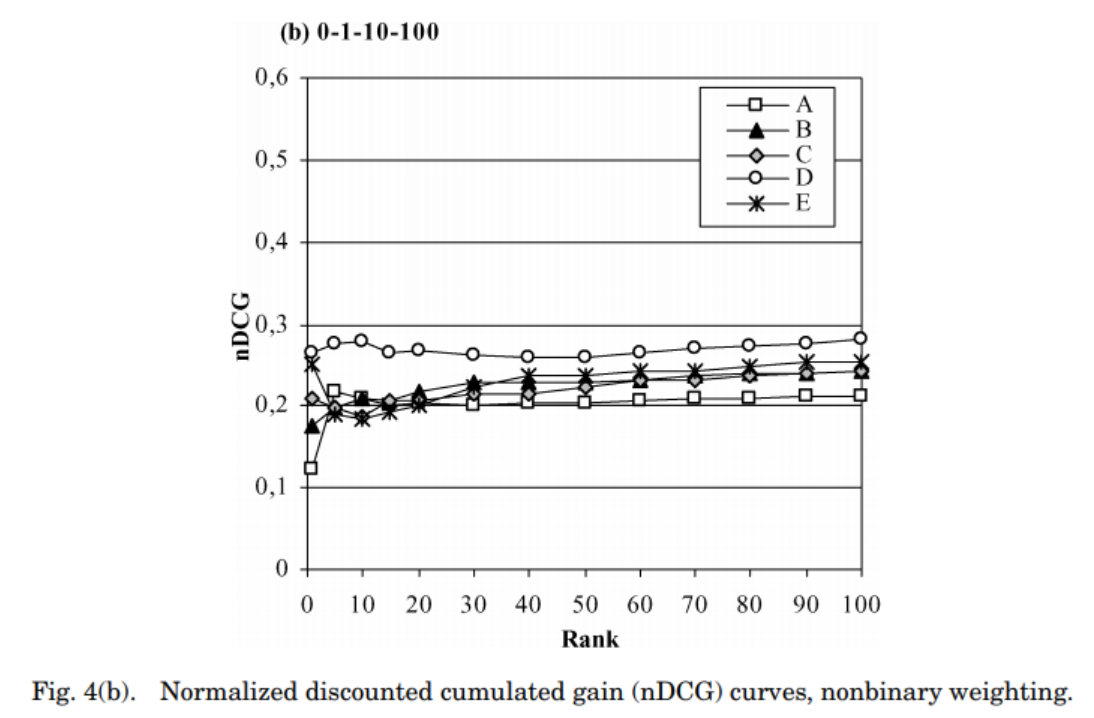
- nDCG 는 값에 어느정도 독립적이며, 비교적 작은 스케일을 가지게 된다.
참고 :
Cumulated Gain-Based Evaluation of IR Techniques, KALERVO JARVELIN
https://52.79.68.122/normalized-discounted-cumulative-gain
