
크롤러 테스트는 어떻게 해야하오...
암만 찾아도 크롤러를 어떻게 테스트 하는지 찾을수가 없다.
검색 결과에 두번째 글은 내가 원하는 TDD의 방법이 아니라 파이썬으로 크롤러 만드는 방법에 관한 글이다.
어떻게 해야하오
별로 어려운 방법이 아닌데 난 2달만에 어떻게 해야할지 생각해낼 수 있었다.
일단 자료 준비를 시작하자.
- http 요청으로 document만 받아올 경우
- selenium이나 puppeteer 등을 이용해 브라우저를 이용해 크롤링 해올 경우
1. http 요청으로 하는 경우
브라우저로 들어가면 자바스크립트가 실행되어 DOM이 바뀔 가능성이 농후하다.
그래서 순수하게 처음 전송해주는 document만을 받아야 한다.
그래서 나는 postman을 이용해서 해당 사이트에 GET 요청을 보낸 뒤 돌아온 document를 복사한다.
2. 자동화된 브라우저를 이용하는 경우
특정 셀렉터가 나올 때 까지 기다려야 하는 상황이 존재한다면...
만약 아래와 같은 이슈로 그걸 재현하기 쉽지 않다면 테스트가 어려워진다.
- cors 등의 이유로 제대로 스크립트가 로컬 환경에서 동작해주지 않을 때
- 암호화 복호화나 특정 쿠키값을 이용해 DOM을 랜더링 해주며, 서순이 맞지 않으면 동작하지 않는 사이트 (이 경우 로컬에서 동작하지 않음)
- 기타 다른 이유로 document를 복사해왔을 때 로컬에서 동작하지 않는 사이트
일단, 1의 방식처럼 가져오는게 기본이긴 한데 그렇게 했을 때 CORS 에러 등으로 인해 자동화된 브라우저가 동작하지 못한다면
브라우저를 통해 DOM 변경이 완료된 상태의 document를 가져올 수 밖에 없다.
개발자 도구에서 html태그를 클릭하고 복사하면 document 전체가 복사된다.
복사한 다음엔?
어디든 좋으니 fixture로 저장해둬야 한다.
나의 경우엔 이렇게 처리했다.
저장 하고나면?
그럼 이제 테스트를 작성 할 차례다.
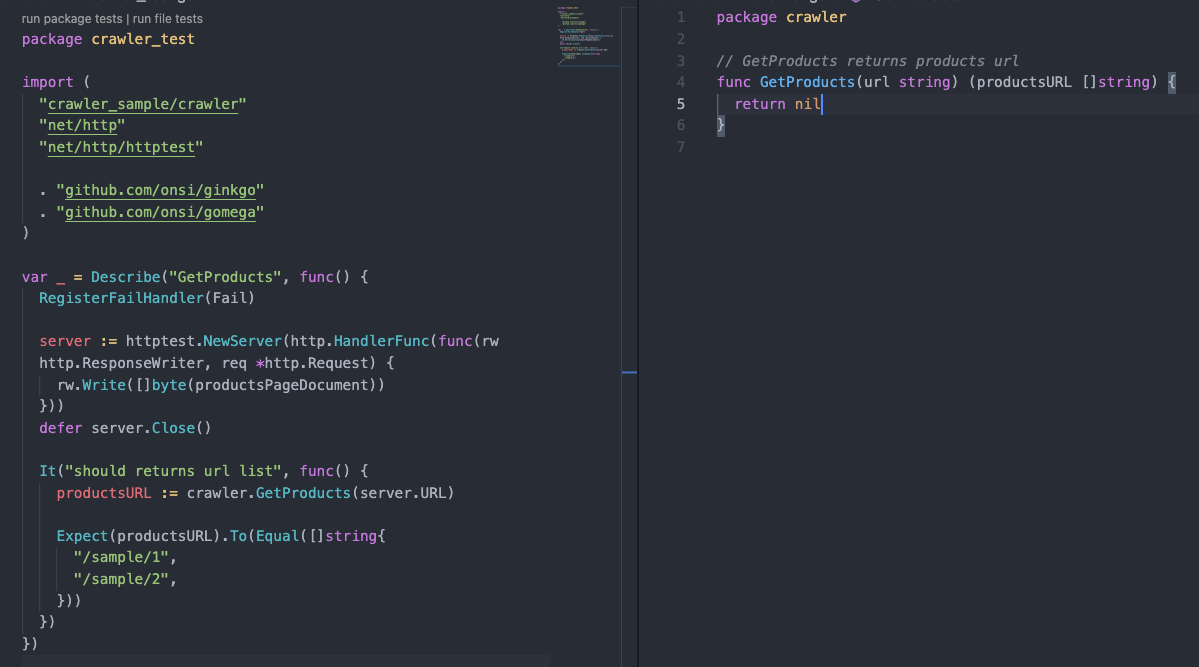
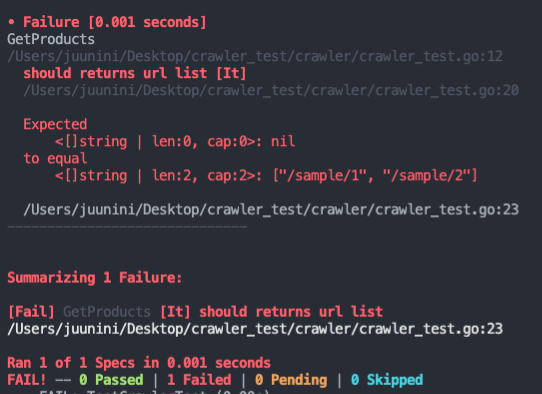
테스트 코드 작성 (Red)
실제 코드는 아무것도 작성이 안되어 있어서 돌리면 당연히 실패한다.
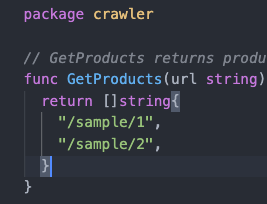
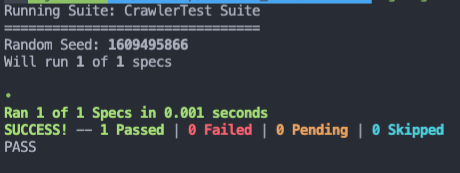
테스트 코드 작성 (Green)
일단 테스트가 성공하도록 내용을 채워넣는다.
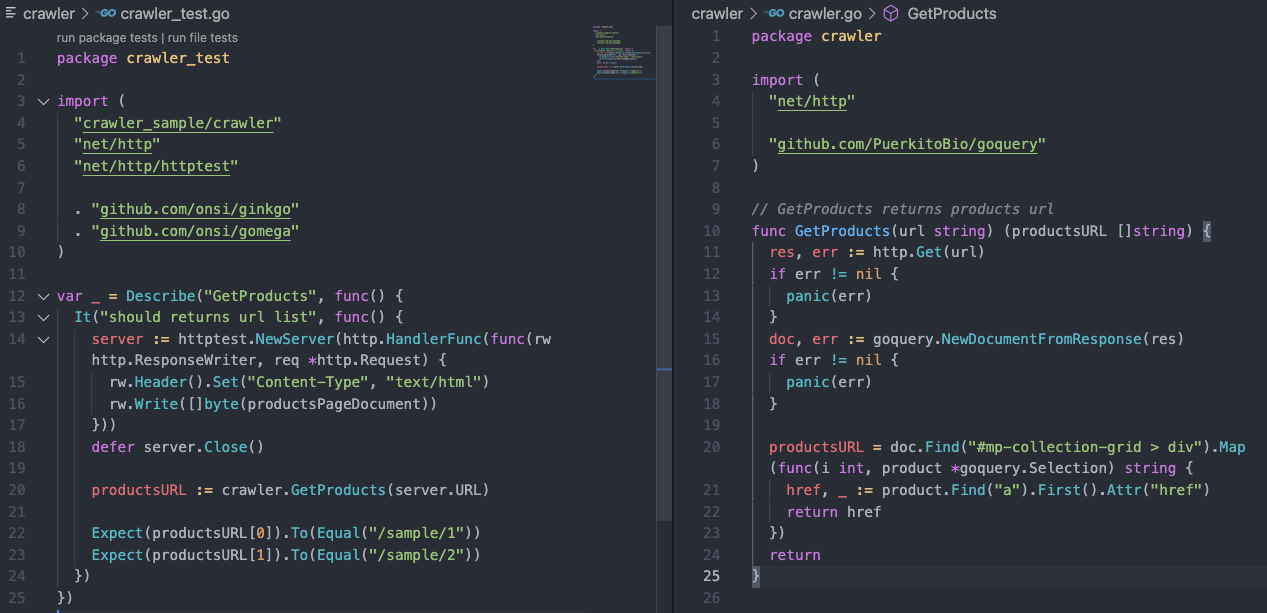
테스트 코드 작성 (Refactoring)
테스트가 잘 되는걸 확인했으니 이제 리펙토링을 한다.
자동화된 브라우저의 경우에도 비슷하게 진행하면 된다.
추가사항
예제에는 더 길어질까봐 쓰지 않았지만,
- 똑같은 형식의 페이지인데도 예외적인 뭔가가 있는 페이지가 있는 경우
- 400대 에러 케이스
- 500대 에러 케이스
- 내가 의도한 페이지가 아니라 이상한 페이지를 받은 경우
이런 케이스에 대해서도 준비를 해둬야 한다.
크롤링은 아무리 자동화라도 무슨 일이 일어날지 모르기 때문에
자동화를 시키기 전에 해당 사이트에 대해 어느정도 파악해 둘 필요가 있다.
예제 코드 Repository
https://github.com/juunini/crawler-test
에이 뭐야 별거 없네?
그렇다. 사실 별거 없다.
그런데 나는 이 간단한걸 생각 못해서 두달 동안이나 크롤러 코드를 그냥 갖다 박으면서 짰다.
테스트를 꼭 해야돼?
혹자는
- 테스트 코드가 없어도 애초에 코드만 잘 작성하면 그만 아니냐
- 그냥 하는게 더 빨리 작성할 수 있지 않냐
- 잘 돌아가는지 확인만 되면 되는거 아니냐
라고 할 수 있는데 나는 그렇게 생각하지 않는다.
회사에서 크롤러를 추가하고나서 시동을 걸어놓으면 하루 이틀은 에러에 미친듯이 시달려야 했다.
하지만 테스트 코드를 작성하고 나서는 한 두번의 예외적인 케이스만 겪거나 깔끔하게 끝나거나 했다.
테스트를 작성하고 얻었던 이점
- 3일동안 애매하고 지저분하게 끌고 가야 할 일을 반나절만에 깔끔하게 끝낸 경험을 했다.
- 예외적인 케이스들에 대한 테스트도 잘 준비해두었기에 코드가 오작동할 걱정이 없었다.
- 이상하게 들릴 수도 있지만, 테스트를 작성하기 때문에 코드를 더 빨리 완성할 수 있었다.
- fixture를 저장해두기 때문에 빠르게 테스트도 가능하고, 나중에 문제가 생기더라도 내가 실수한건지 사이트 구조가 바뀐건지 바로 파악이 가능하다.
