- https://wikibook.co.kr/mymlrev/ 을 읽고 정리한 내용입니다.
4.3 서포트 벡터 머신(SVM)
사용하기 편하면서 높은 정확도를 보이는 지도학습 머신러닝 알고리즘
1. 정의
<kNN 알고리즘>
'여기가 강남일까요, 강북일까요?'를 해결하는 알고리즘
< SVM >
'지금 현재 이곳이 한강의 북쪽인가요, 남쪽인가요?'를 해결하는 알고리즘
- 서포트 벡터(support vector) : 한강의 위치를 찾는 데 사용되는 개념
- 결정 경계선(decision boundary) : 한강. 즉, 도시가 강북인지 강남인지 구분 해주는 선
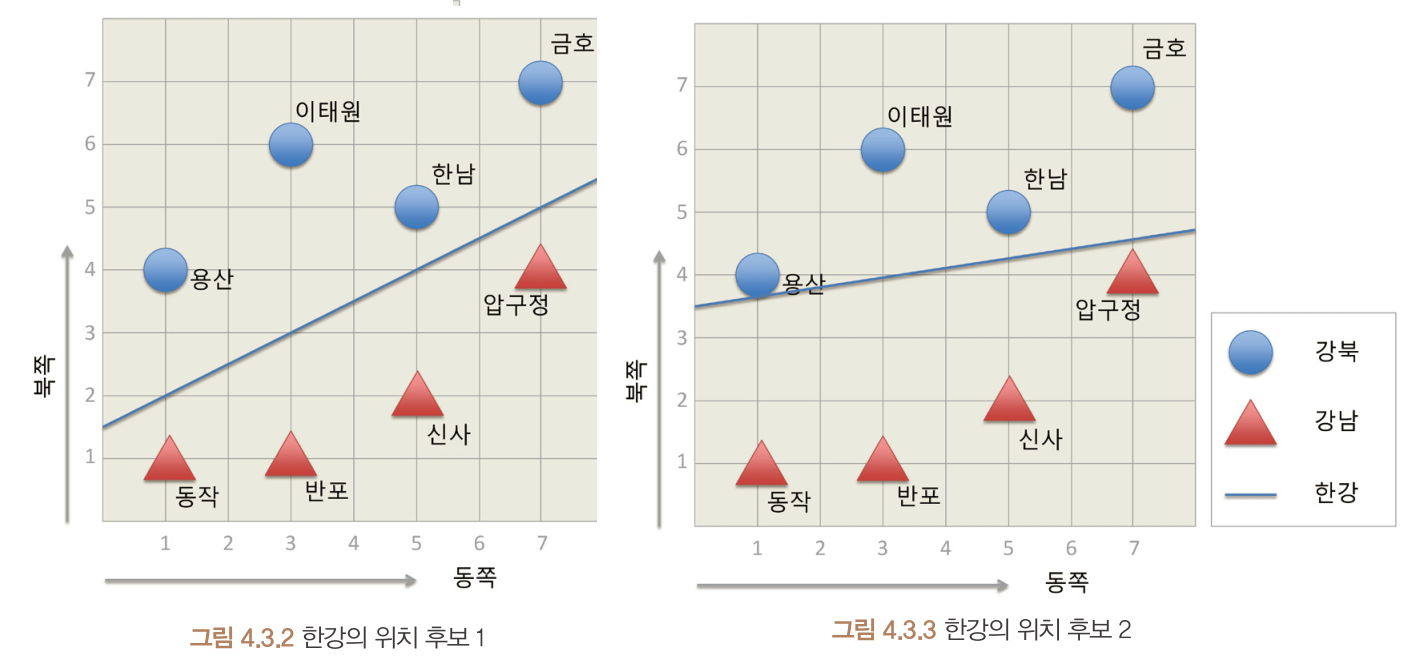
후보 1이 후보 2보다 더 좋은 결정 경계선으로 보임.
why?
- 후보 2는 결정 경계선과 데이터 포인트가 가까움
- 결정 경계선이 데이터 포인트(도시 지점)에 가까이 위치할수록 조금의 속성 차이에도 분류값이 달라질 수 있기 때문에 예측의 정확도가 불안정해짐
2. 서포트 벡터 (support vector)
결정 경계선을 찾는 데 사용되는 개념
-
vector
2차원 공간 상에 나타난 데이터 포인트
벡터 공간에서 점은 벡터로 표현될 수 있음.
점이 단순히 (0,0) 위치에서 특정 지점까지 벡터를 점으로 형상화 한 것으로 생각할 수 있기 때문 -
support vector
결정 경계선과 가장 가까이 맞닿은, 최전방 데이터 포인트를 의미
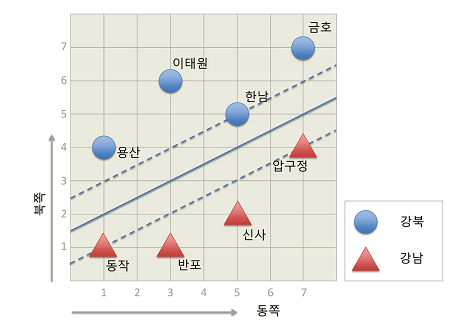
위 사진에서 한남, 동작, 압구정이 서포트 벡터임
3. 마진(margin)
서포트 벡터와 결정 경계 사이의 거리
SVM의 목표는 이 마진을 최대로 하는 결정 경계를 찾는 것 (학습 단계)
마진이 클수록 우리가 알지 못하는 새로운 데이터에 대해 안정적으로 분류할 수 있기 때문
4. 비용(cost)
성능이 좋은 모델 학습 시 에러가 적은 모델
성능이 좋은 모델 = 테스트 및 운용 시 에러가 적은 모델
약간의 오류를 허용하기 위해 비용(C)이라는 변수를 사용
cost margin , 학습 에러율 + (과대적합의 위험)
cost margin , 학습 에러율 + (과소적합의 위험)
5. 결정 경계 (decision boundary)
서로 다른 분류값을 결정하는 경게 (ex. 경계 위는 강북, 경계 아래는 강남)
결정경계 = N - 1 차원
ex1 데이터가 2차원 공간에 존재하는 경우 결정 경계선(1차원)
ex2 데이터가 3차원 공간에 분포하는 경우 결정 경계 초평면(2차원, hyperplane)
6. 커널 트릭(kernel trick)
문제 상황
1차원의 결정 경계는 0차원. 점으로 집단을 구분하기 어려움
해결
1차원 데이터를 2차원으로 옮겨서 y축을 만듦
=> 매핑 함수(mapping function) : 저차원의 데이터를 고차원의 데이터로 옮겨주는 함수
but, 매핑 함수는 계산량이 많아 현실적으로 사용하기 어려움
so, 커널 트릭이 고안됨
- 선형 SVM : 커널을 사용하지 않고 데이터를 분류. 비용(C)를 조절해서 마진의 크기를 조절.
- 커널 트릭 : 선형 분리가 주어진 차원에서 불가능할 경우, 고차원으로 데이터를 옮기는 효과를 통해 결정 경계를 찾음.(실제로 데이터를 고차원으로 보내는 것은 아님) 비용(C)와 gamma를 조절해서 마진의 크기를 조절.
즉, SVM이 2차원 벡터 공간 상에서 직선이 아닌 결정 경계선으로 데이터를 분류한 경우는 모두 커널 트릭의 결과임.
- 가우시안 RBF 커널
- 데이터 포인트에 사용되는 가우시안 함수의 표준편차를 조정함으로써 결정 경계의 곡률을 조정- 이 표준편차 조정 변수를 감마(gamma)라고 함
- 감마가 커지면 데이터포인트별로 허용하는 표준편차가 작아지면서 결정 경계가 작아지면서 구부러짐
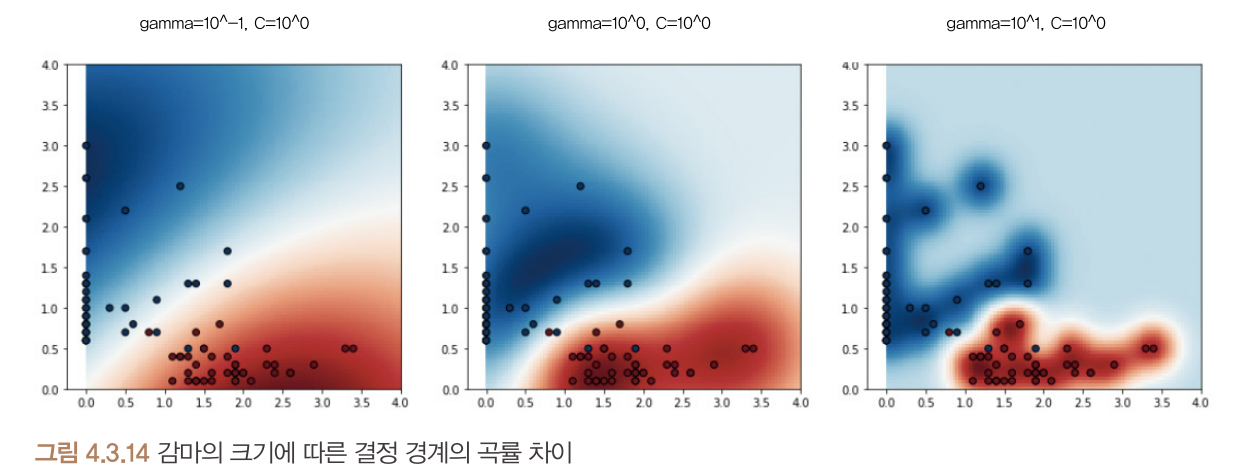
7. 파라미터 튜닝(parameter tuning)
비용과 감마 수치를 조정함으로써 정확도를 높일 수 있음
- 비용 : 마진 너비 조절 변수.
- 클수록 마진 너비가 좁아지고, 작을수록 마진 너비가 넓어짐 - 감마 : 커널의 표준 편차 조절 변수.
- 작을수록 데이터포인트의 영향이 커져서 경계가 완만해지고, 클수록 데이터 포인트가 결졍 경계에 영향을 적게 미쳐 경계가 구부러짐
8. SVM 알고리즘의 장점과 단점
1. 장점
- 커널 트릭을 사용함으로써 특성이 다양한 데이터를 분류할 수 있음
n개의 특성을 가진 데이터는 n차원 공간의 데이터 포인트로 표현됨
- 파라미터(C, gamma)를 조정해서 과대적합 및 과소적합에 대처 가능
- 적은 학습 데이터로도 딥러닝만큼 정확도가 높은 분류를 기대할 수 있음
2. 단점
- 데이터 전처리 과정(data preprocessing)이 중요함
특성이 다양하거나 확연히 다른 경우에는 데이터 전처리 과정을 통해 데이터 특성 그대로 벡터 공간에 표현해야함
- 특성이 많을 경우 결정 경계 및 데이터의 시각화가 어려움
9. 실습
