🔍 음성 데이터
인간의 언어 : 자연어
기계의 언어 : 기계어 - 0,1로만 이루어짐
기계어 -> 어셈블리어 -> 고급어(고급 프로그래밍 언어)
자연어에 가까울 수록 인간이 이해하기 쉬워진다.
음성인식 : 우리의 말들을 인지, 파악하고 분석해 그 결과에 맞는 표현이나 결과 전달
문자언어는 시각적으로 이미지를 사용하지만, 음성언어는 청각적으로 소리를 사용하여 전달해야 한다.
📢 소리와 주파수
소리 : 주기적인 움직임을 갖는 waveform의 형태로 표현
주기적인 움직임은 어떠한 단위시간 동안 진동한 횟수의 개념으로 x축은 시간, y축은 진폭을 의미한다. 진폭은 주기적으로 진동하는 파형, 진동의 폭이다. 주기는 특정 지점에서 다시 같은 부분이 등장하는 부분까지의 시간, 한번 진동하는데 걸리는 시간을 의미한다.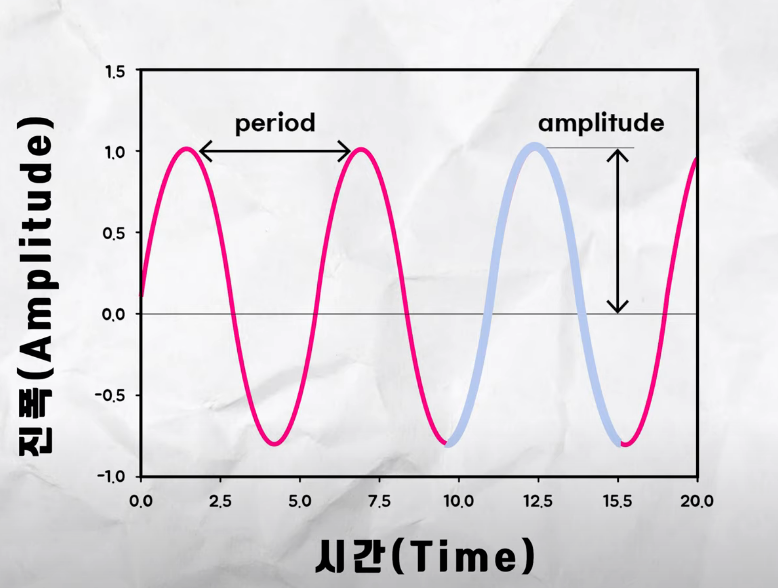
주파수 : Hz라는 단위를 사용하며, 단위시간 1초에 진동하는 횟수
주파수는 1/주기이고, 주기는 1/주파수이다. 고주파는 초당 진동 수 많으며, 높은 음의 소리를 낸다. 저주파는 초당 진동 수 적으며, 낮은 음의 소리를 낸다. 진폭의 크기가 크면 대체적으로 소리의 크기가 크다.
소리 샘플링 : 소리 파동의 높이를 일정한 간격에 의한 좌표값으로 저장 & 소리를 숫자화, 디지털화
저장하는 주기 = 샘플링 레이트
샘플링 레이트가 짧으면 실제와 가깝고, 멀면 손실이 많은 신호로 실제와 멀다. 표준 샘플링 레이트는 44.1KHz로 0.0000267초 간격이다.
📉 소리의 파동
시간 영역
waveform, 파형에 익숙함
주파수 영역
파형은 무한개의 코사인 또는 사인과 같은 주기함수의 합으로 나타낼 수 있으며, 여러 주기 함수는 주파수 별로 분리 가능
-> 소리의 파동 신호는 다른 주기의 주파수 성분의 합으로 표현
📝 주파수 정보 특징 추출
스펙트럼 방식 : 소리를 주파수 영역으로 봄
특정 주파수의 진폭값을 알 수 있게 되고, x축은 주파수, y축은 진폭 구성된 값으로 표현이 가능하다.
멜 스펙트로그램 방식 : 시간에 대한 정보까지 고려해서 주파수 특성이 시간에 따라 달라지는 특징을 추출해 줄 수 있는 기법
실제 주파수 정보를 인간이 청각구조를 반영하여 수학적으로 변환하기 위한 대표적인 방법이다.
📡 음성인식
음성인식 : 기계가 사람의 말소리를 인식하고 그 결과를 문자로 출력해주는 시스템
ex) LG ThinQ, Apple Siri
음향모델 (Acoustic Model) : 음성을 자주 듣고 학습해 음성에 대해 익숙해지는 과정
음향모델을 훈련하는 것은 특정 언어에 존재하는 모든 음소를 배우는 과정을 담고 있다.
언어모델 (Language Model) : 단어의 자연스러운 결합을 듣고 배우는 과정
언어모델을 훈련하며 특정 언어에 존재하는 단어 결합 규칙을 습득할 수 있다.
음성인식을 위해서는 음향모델로 음소와 단어를 학습하고, 언어모델로 어휘, 문법, 주제를 학습해야 한다.
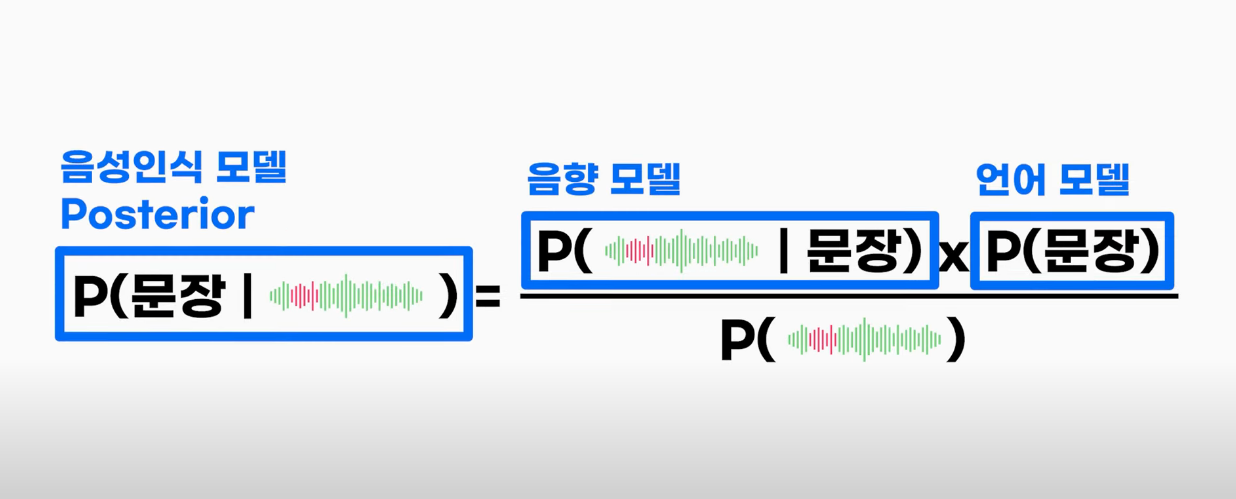
🥽 베이즈 정리
어떤 사건이 서로 배반하는 원인 둘에 의해 일어난다고 할 때 실제 사건이 일어났을 때, 이것이 두 원인 중 하나일 확률을 구하는 정리
베이즈 정리를 음성인식 과정에 대입