기본 연습 - 정규 표현식 연습 사이트
https://regexr.com/38bd56
정규 표현식(Regular Expression)
- 문자열을 검색하거나, 치환할 목적으로 고안된 특수한 문자열
[]
-
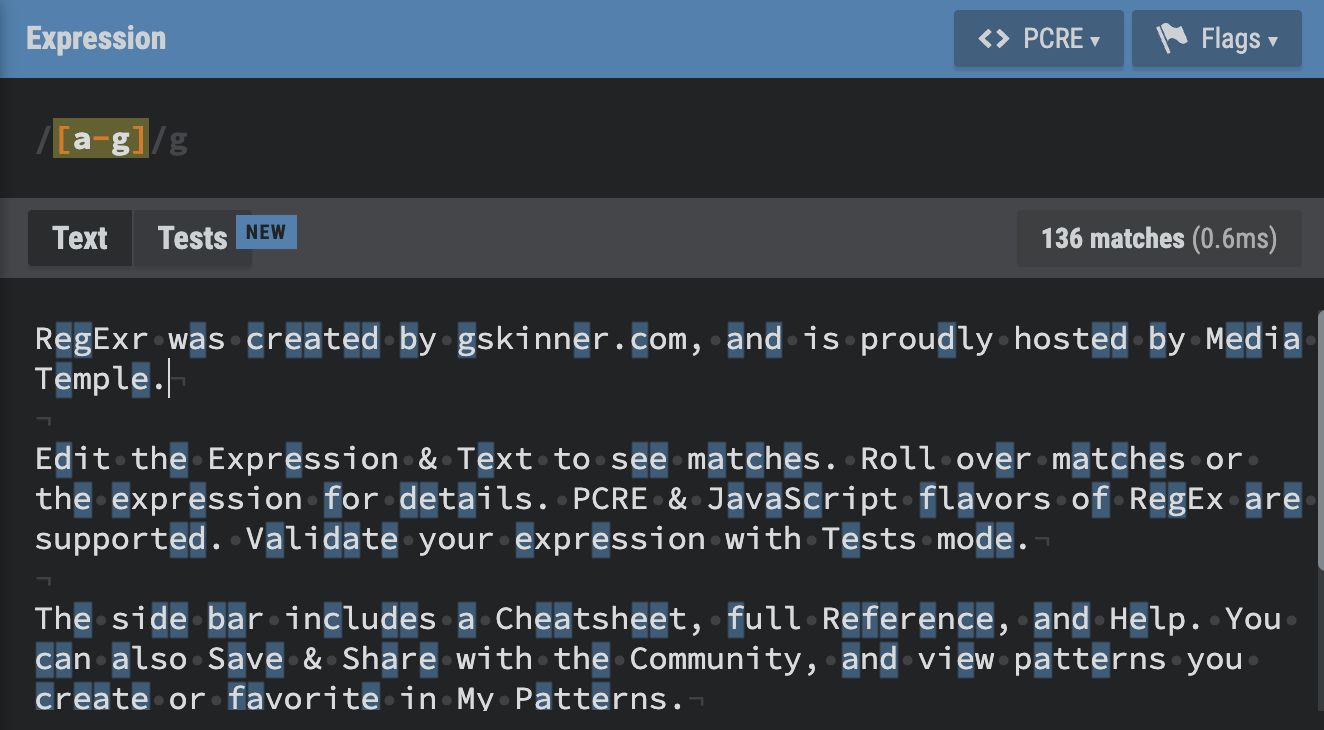
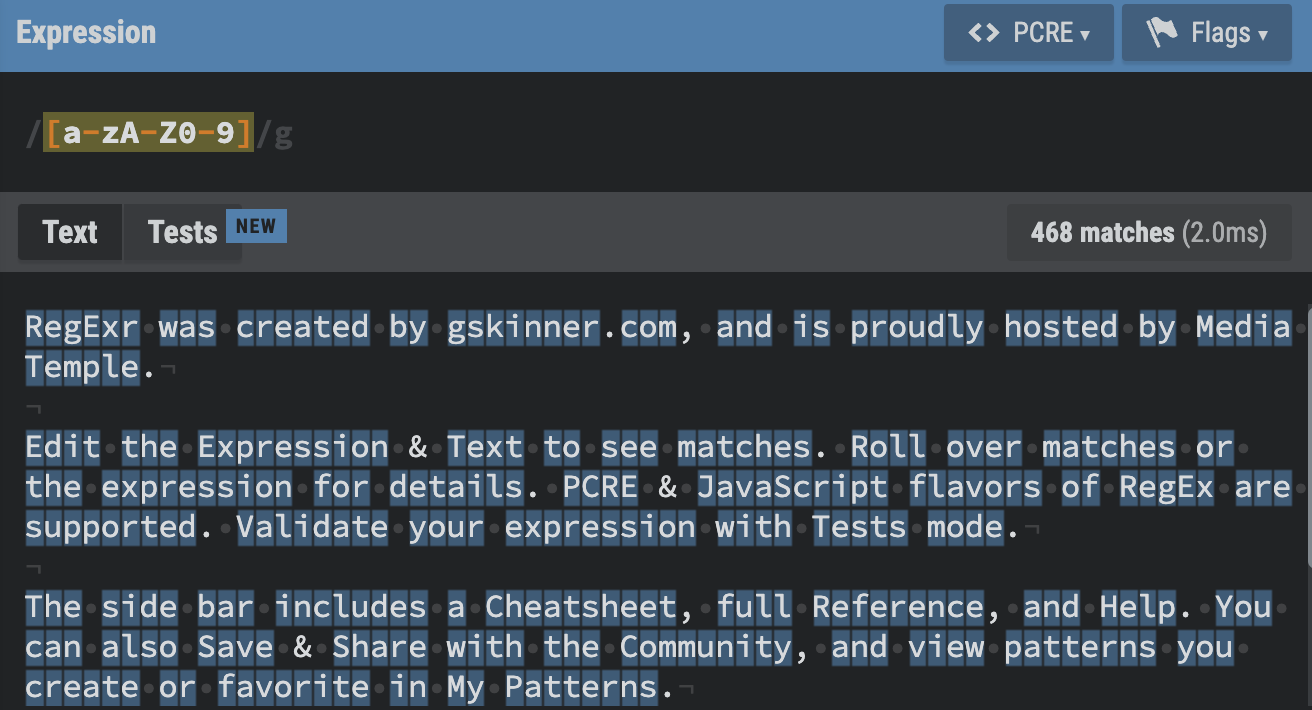
[] : Character set. Match any character in the set.

-
다음과 같이 범위로 지정할 수도 있다.
^
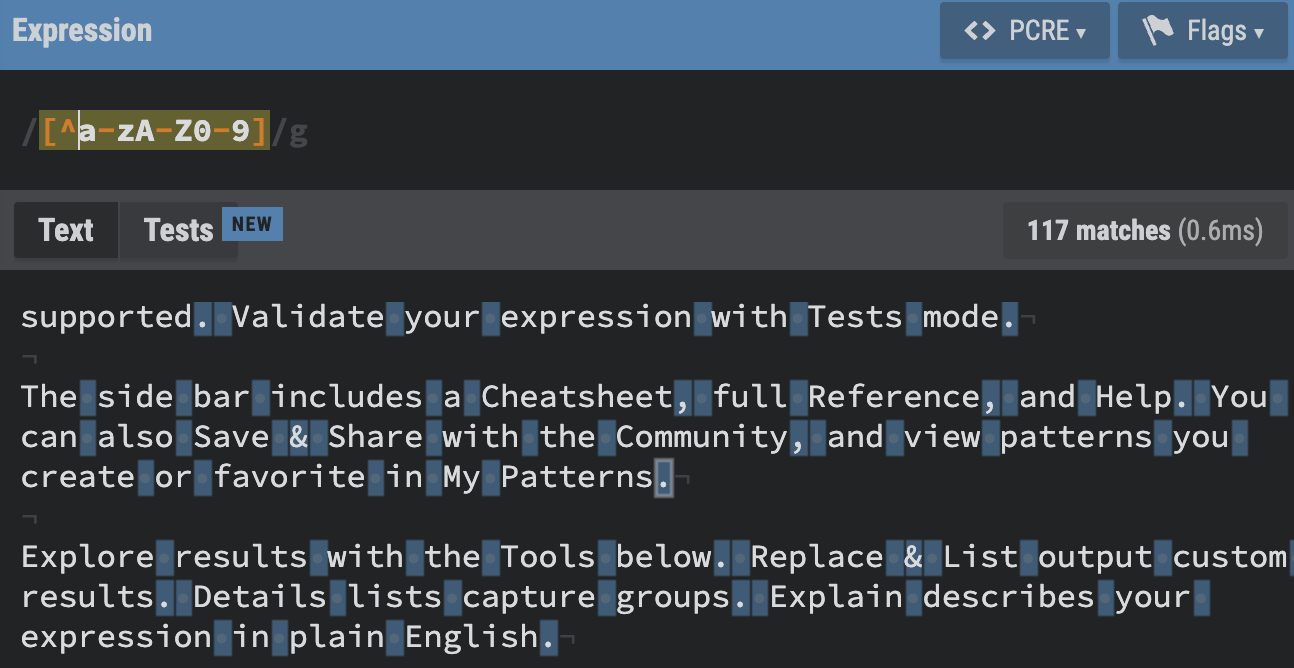
- set안에 쓰이면, not의 의미를 갖는다.
- ^ : Negated set. Match any character that is not in the set.
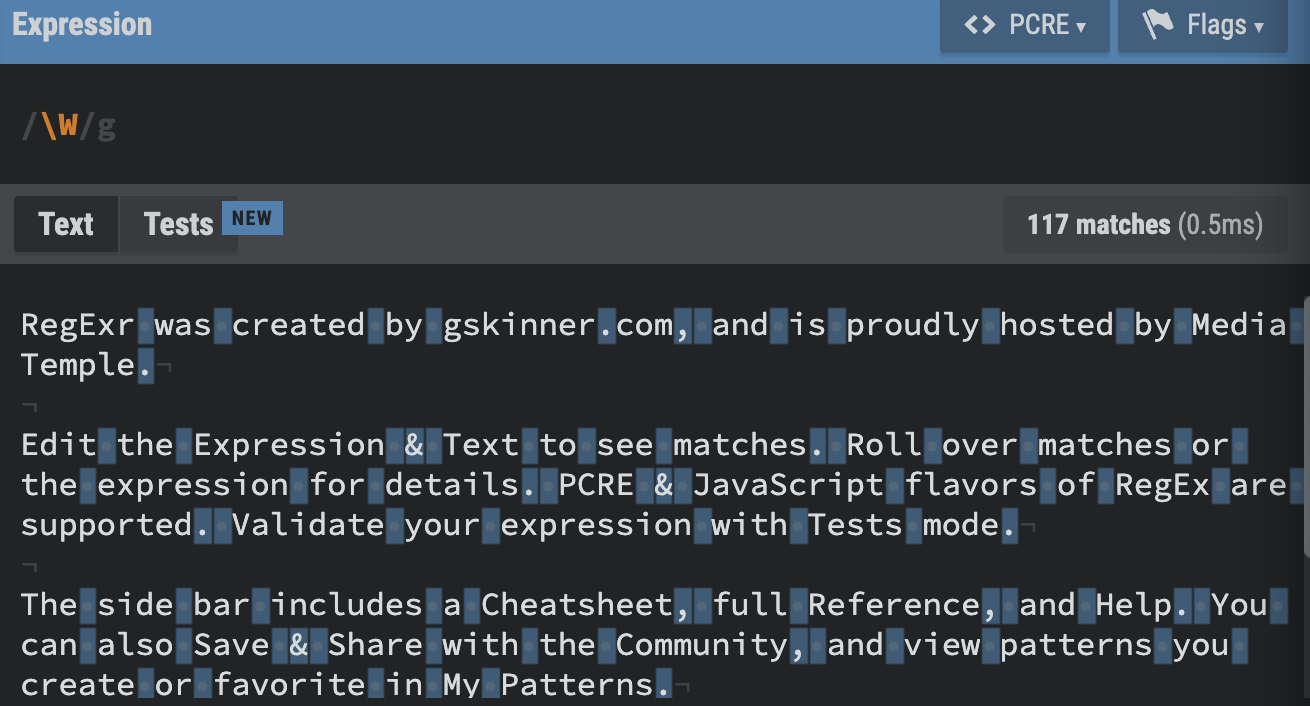
\w, \W
-
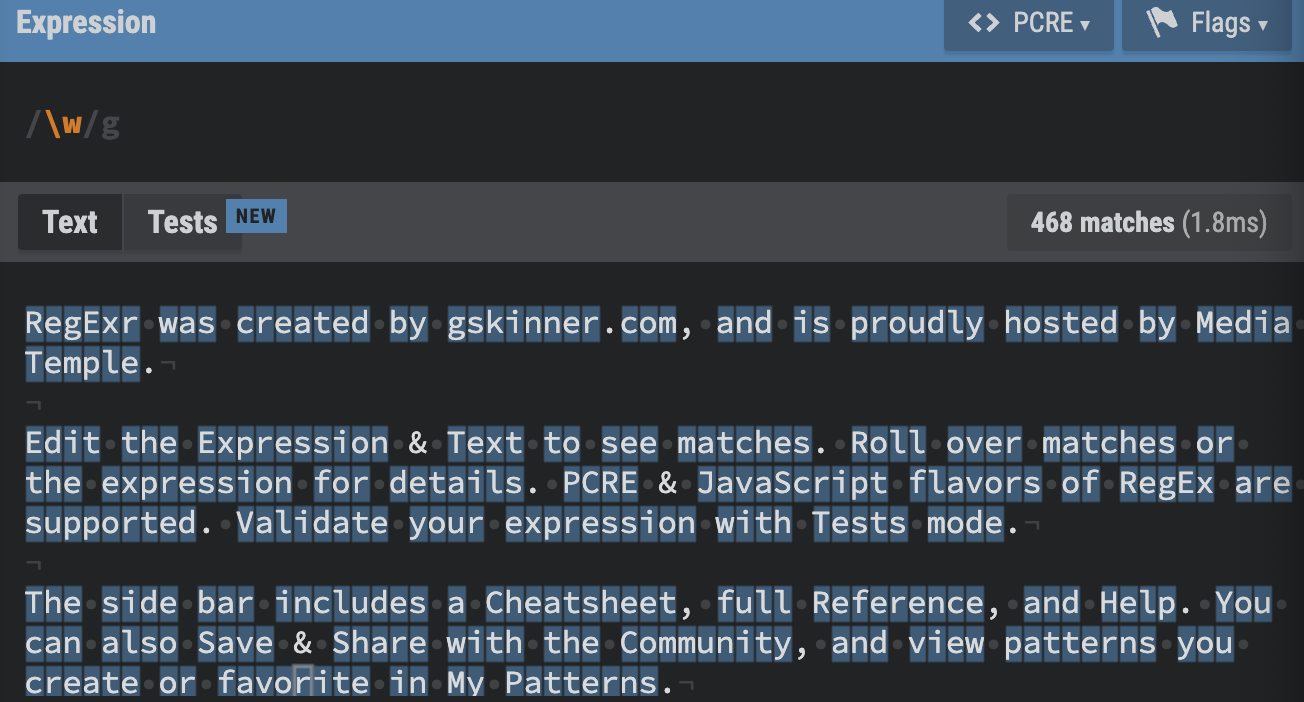
\w : Word. Matches any word character (alphanumeric & underscore).
-
\W : Not word. Matches any character that is not a word character (alphanumeric & underscore).
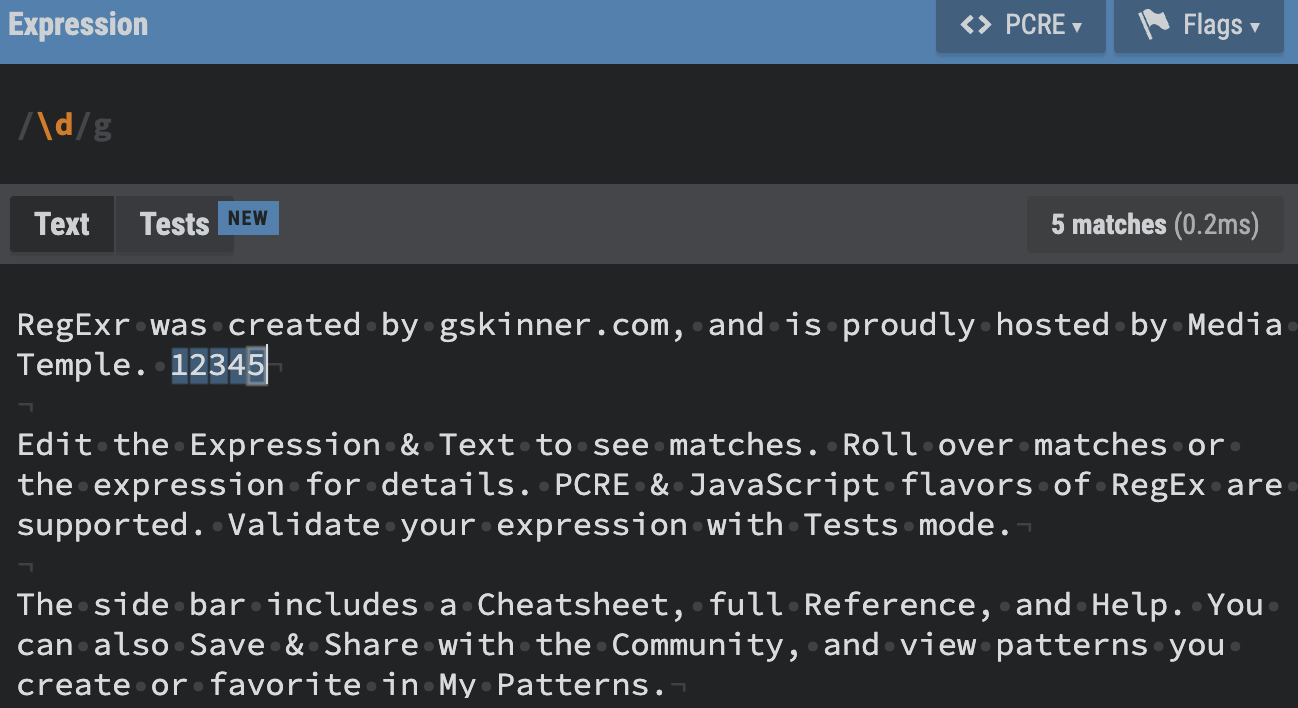
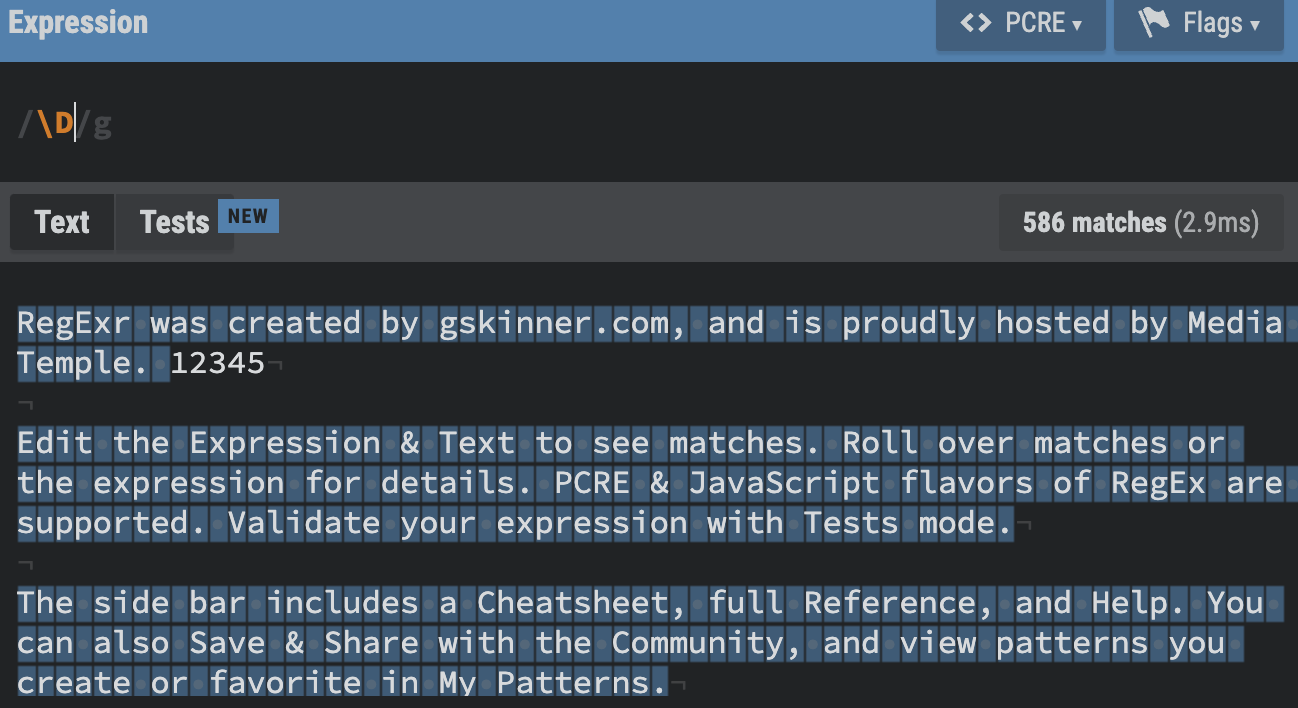
\d, \D
-
\d : Digit. Matches any digit character (0-9)
-
\D : Not digit. Matches any character that is not a digit chracter (0-9)
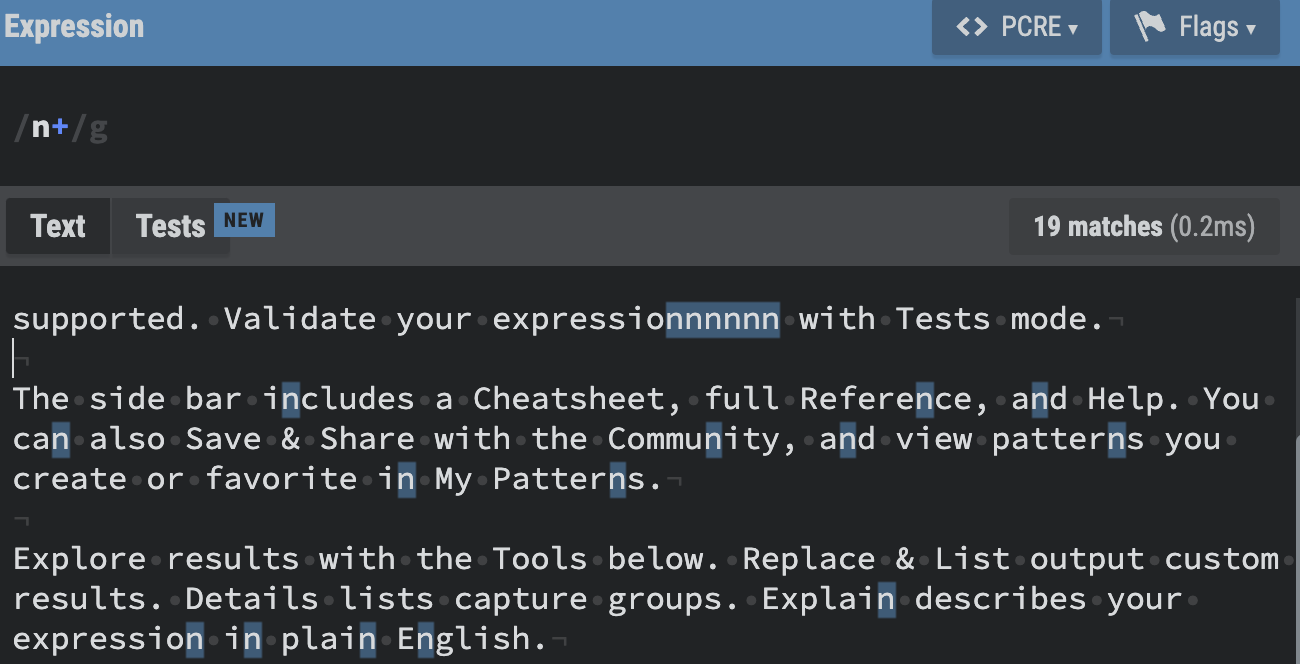
+
- '+' : Quantifier. Match 1 or more of the preceding token.
^, +
- ^ : Beginning. Matches the beginning of the string, or the beginning of a line, if the multiline flag is enabled.
- '+' : Quantifier. Match 1 or more of the preceding token.
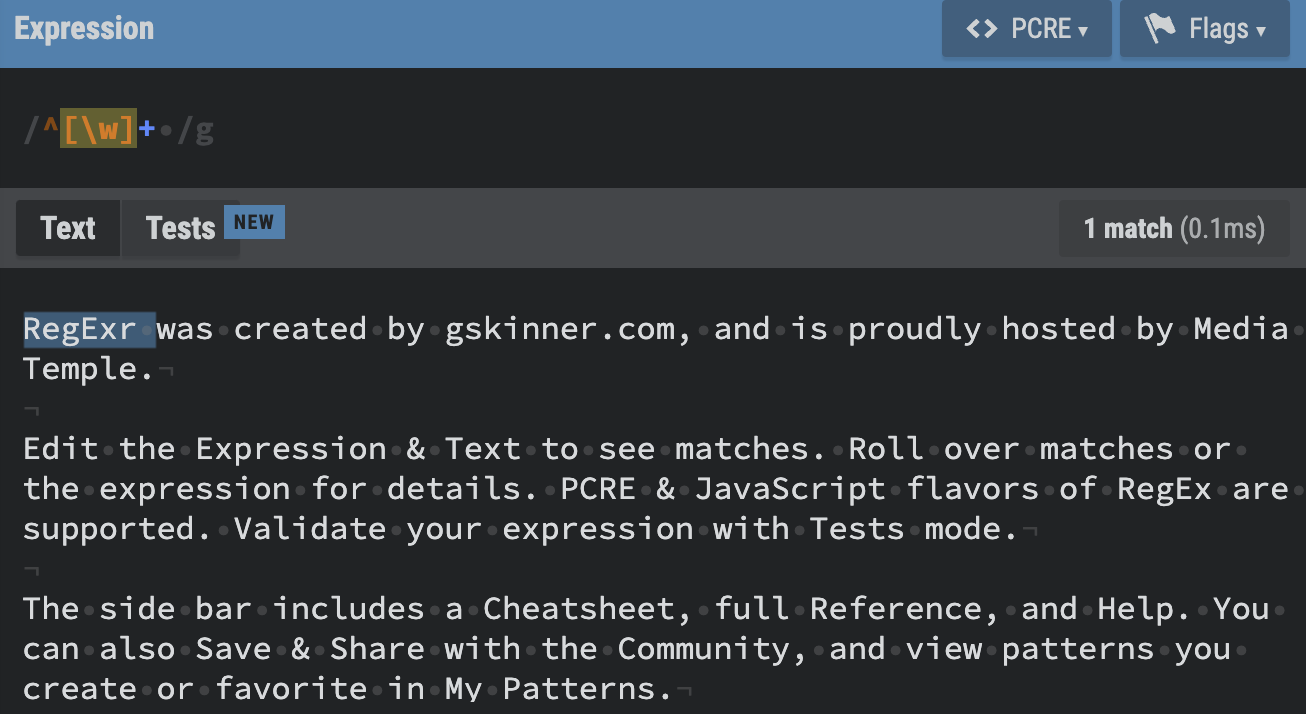
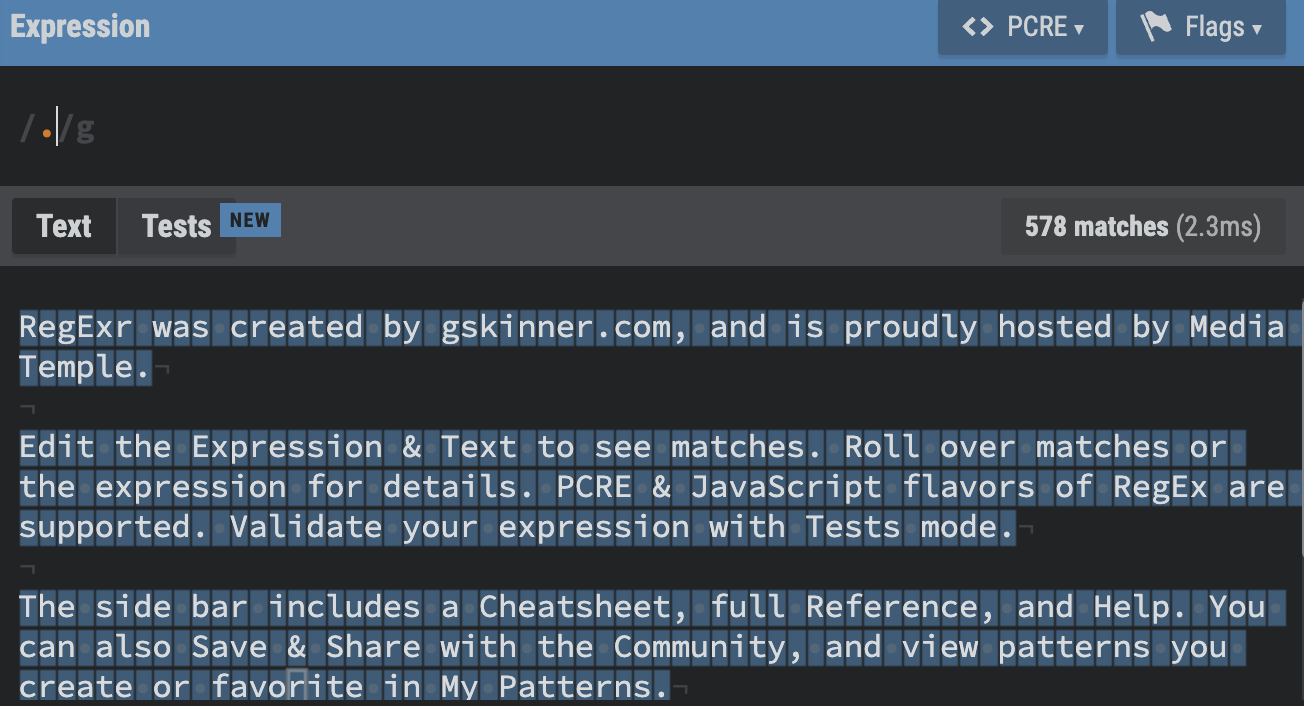
.
- . : Dot. Mtaches any character except line breaks.
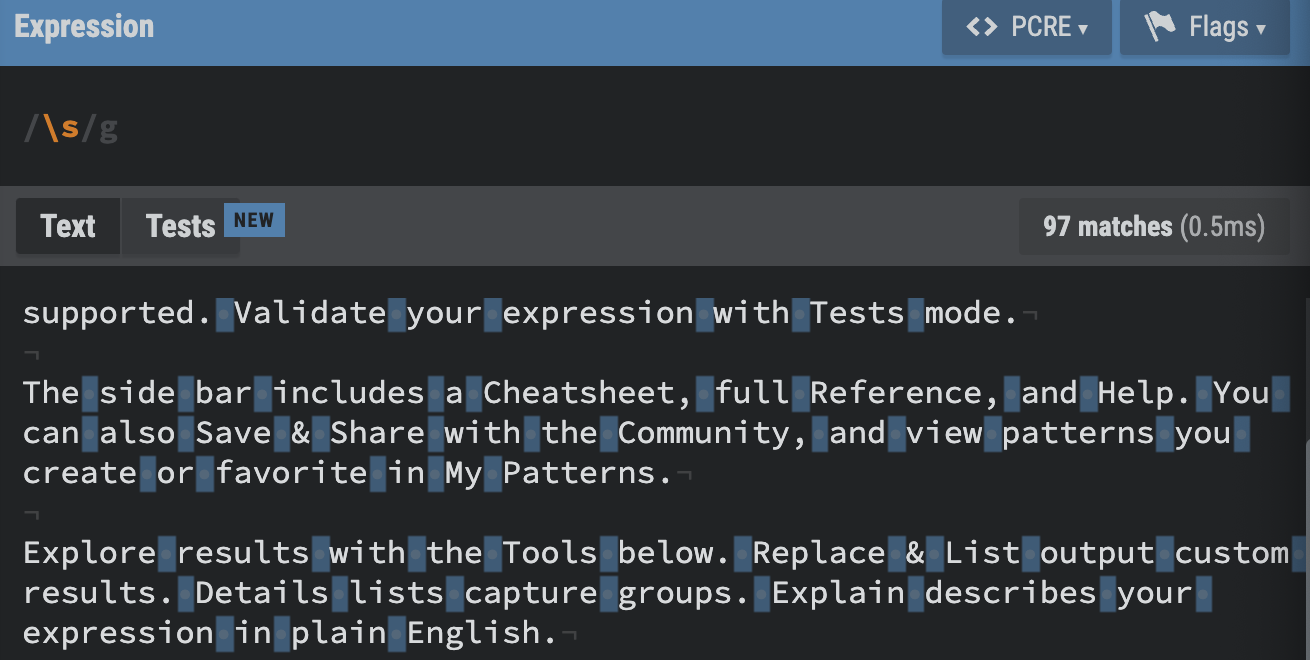
\s, \S
-
\s : whitespace. Matches any whitespace character (spaces, tabs, line breaks)
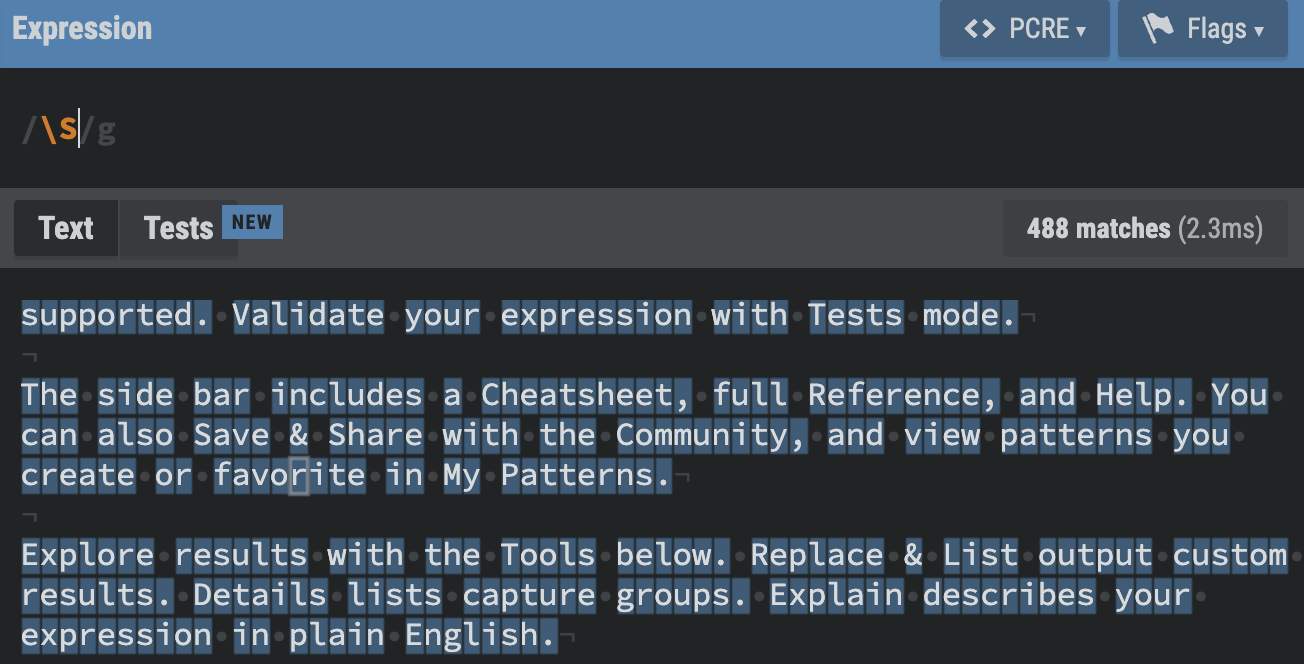
-
\S : Not whitespace. Matches any character that is not a whitespace chracter (spaces, tabs, line breaks).
\b
- \b : Word boundary. Matches a word boundary position between a word character and non-word character or postion (start /end of string)
- ? : Lazy. Makes the preceding quantifier lazy, causing it to match as few characters as possible

안녕하세요.