1. 아래 자바 코드에서 출력되는 값을 작성하시오.
class Static{ public int a = 20; static int b = 0; } public class Main{ public static void main(String[] args) { int a; a = 10; Static.b = a; Static st = new Static(); System.out.println(Static.b++); System.out.println(st.b); System.out.println(a); System.out.print(st.a); } }
- 변수 a 생성
- Static.b = a; 이부분이 헷갈림 아마 내부에서만 유지되는 static에 a의 값 10을 넣어서 적용이 되었을 것 같은데 모르겠음
- 객체 생성
- System.out.println(Static.b++); // b = 10이므로 10을 출력하고 11이됨
- System.out.println(st.b); // 객체 st출력 11 static이므로 객체 static은 값은 11 고정
- 10출력
- 20출력
static과 public은 전혀 다른 역할
🔹 static은 "공유 여부"
static 변수는 클래스에 1개만 존재
객체들 간에 공통적으로 사용됨
예: static int count → 모든 객체가 공유
🔹 public은 "접근 가능 여부"
public은 누가 접근 가능한지를 결정함
public이 붙은 변수나 메서드는 다른 클래스에서도 사용 가능
→ private, protected, default 와 비교됨
2. 다음 C언어의 출력값을 작성하시오.
#include <stdio.h> int main(){ char a[] = "Art"; char* p = NULL; p = a; printf("%s\n", a); printf("%c\n", *p); printf("%c\n", *a); printf("%s\n", p); for(int i = 0; a[i] != '\0'; i++) printf("%c", a[i]); }
- 배열a 생성
- 포인터변수생성
- 포인터가 배열a를 가르킴
- printf("%s\n", a); // 문자열 출력 Art
- printf("%c\n", *p); // 포인터의 시작지점 출력 A
- printf("%c\n", *a); // 배열의 시작지점 출력 A
- printf("%s\n", p); // 포인터가 가르키는 배열 출력 Art
- 문자열이 끝날때까지 출력 Art
3. 다음 C언어의 출력값을 작성하시오.
#include <stdio.h> int main(){ char* a = "qwer"; char* b = "qwtety"; for(int i = 0; a[i] != '\0' ; i++){ for(int j = 0; b[j] != '\0'; j++){ if(a[i] == b[j]) printf("%c", a[i]); } } }
- 포인터 변수 a, b 생성
- 2중 for문안에 조건문 if(a[i] == b[j]) printf("%c", a[i]);
정답 : qwe

✅ 간단한 예시: 사용자 정보 XML
xml
<?xml version="1.0" encoding="UTF-8"?> <user> <name>Juwon</name> <age>25</age> <email>juwon@example.com</email> </user>
정답 : AJAX (Asynchronous JavaScript and XML)
그냥외워

- L2F : 시스코가 개발한 2계층 터널링 프로토콜 , 원격 사용자의 트래픽을 기업 내부 네트워크로 연결할 때 사용 , PPP 프레임을 캡슐화 , 암호화기능은 거의없음 , 패킷을 2계층 수준으로 감싸서 본사 라우터로 전달 , 지금은 거의 L2TP에 통합됨
- PPTP : VPN 터널링 프로토콜 PPP 프레임을 IP 패킷으로 캡슐화하여 인터넷 상에서 전송 , 2계층 + 3계층 혼합 동작 , 간단하고 빠름, 암호화 약함
- IPsec : 보안 프로토콜 모음집 , 3계층 보안 , 전송모드-IP 페이로드만 암호화 , 터널모드-전체 IP 패킷 암호화(VPN용) , 암호화 인증 키교환 등 통합 보안 기능
- ISP : 인터넷 서비스를 제공하는 회사
- 2계층 터널링 기술 : ppp,프레임 릴레이 등 데이터링크 단위의 프레임을 터널링하는 기술
✅ 1. PPP 프레임을 캡슐화
📌 뜻:
PPP(Point-to-Point Protocol)로 만든 데이터 프레임을
인터넷(IP 네트워크) 상에서 보내기 위해 다른 프로토콜로 감싸는 것
✅ 2. VPN 터널링 프로토콜
📌 뜻:
VPN을 만들기 위해 데이터를 감싸서 전송하는 터널 역할을 하는 기술
✅ 3. 2계층 + 3계층 혼합 동작
📌 뜻:
터널링 프로토콜이 데이터링크 계층(2계층)과 네트워크 계층(3계층) 모두를 이용함
📦 예:
PPTP가 대표적
PPP 프레임을 감싸서 IP 패킷으로 전송
→ 즉, 2계층 데이터를 3계층을 통해 운반함
✅ 4. 전송 모드 (IPsec 전용)
📌 뜻:
IPsec에서, IP 패킷의 내부 데이터(Payload)만 암호화하는 방식
📦 쉽게 말하면:
봉투(주소 부분)는 그대로 놔두고, 편지 내용만 비밀로 암호화하는 느낌
기존 통신 구조를 바꾸지 않고 보안만 추가할 수 있어!
✅ 5. 터널 모드 (IPsec 전용)
📌 뜻:
IP 패킷 전체(주소 포함)를 통째로 암호화하고,
그 위에 새로운 IP 헤더를 붙여서 전송하는 방식
📦 쉽게 말하면:
기존 IP 봉투를 다시 다른 봉투로 완전히 감싸는 것
VPN에서 가장 많이 사용되는 방식
✅ 6. 프레임 릴레이 (Frame Relay)
📌 뜻:
과거에 쓰던 저비용 고속 데이터 전송 기술,
패킷 기반으로 데이터를 빠르게 전달
📦 특징:
2계층 전송 기술
지금은 거의 MPLS, 광통신, 인터넷 기술에 밀려 거의 안 쓰임
데이터링크 계층 (Layer 2)
역할과 기능: 데이터 링크 계층은 인접한 두 노드(장치) 사이의 직접적인 데이터 전송을 담당합니다. 이 계층에서는 프레임(Frame) 단위로 데이터가 오가며, 물리 계층을 통해 송수신되는 데이터의 오류 검사와 흐름 제어를 수행하여 안정적인 전달을 보장합니다
startingpitcher.tistory.com
. 예를 들어 프레임 끝에 FCS(Frame Check Sequence) 같은 검증 값을 붙여 오류를 검출하고, 전송 속도를 조절하는 흐름 제어 기능으로 과도한 데이터 전송을 방지합니다.
이더넷(Ethernet, IEEE 802.3)과 와이파이(Wi-Fi, IEEE 802.11) 등이 가장 널리 쓰입니다
velog.io
. 이더넷은 유선 LAN에서 표준으로 사용되는 2계층 프로토콜이고, Wi-Fi는 무선 LAN의 2계층 프로토콜입니다. 그 밖에도 PPP(Point-to-Point Protocol)와 HDLC처럼 두 지점 간의 직렬 연결에 쓰이는 프로토콜도 2계층
네트워크 계층 (Layer 3)
역할과 기능: 네트워크 계층은 다른 네트워크들 간의 데이터 전달, 즉 종단 간(end-to-end) 통신 경로를 책임지는 계층입니다. 이 계층의 가장 중요한 기능은 라우팅(routing)으로, 데이터를 목적지까지 가장 안전하고 효율적으로 전달할 수 있는 경로를 선택하고 그 경로를 따라 패킷을 전달하는 것입니다
---

정답 : ssh
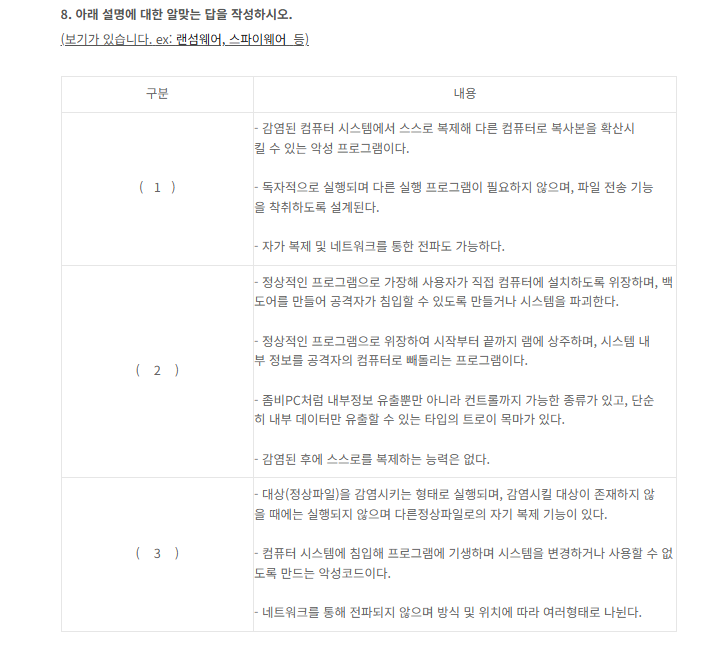
- 스스로 복제함 , 독자적으로 실행됨 , 네트워크를통해 전파
- 사용자가 직접 컴퓨터에 설치하도록 위장 , 백도어 , 정상적인 프로그램으로 위장 , 단순히 내부 데이터만 유출 : 트로이목마 , 복제능력은 없음
- 정상파일을 감염 시키는 형태 , 자기복제기능 있음 , 시스템을 변경하거나 사용할 수 없도록 만드는 악성코드 , 네트워크를 통해전파되지는 않음
나의생각
1 - 웜 , 2 - ip 스푸핑??( 뭘하려는 건지는 알겠는데 이름을.. ) 3 - 바이러스

- 다음 아래 코드에서 이진수를 십진수로 변환하는 코드에 대해 괄호 (a) (b)의 적합한 답을 작성하시오.
#include <stdio.h> int main() { int input = 101110; int di = 1; int sum = 0; while (1) { if (input == 0) break else { sum = sum + (input (a)(b)) * di; di = di * 2; input = input / 10; } } printf("%d", sum); return 0; }
- 보기에 목적이 확실함 십진수 -> 이진수
- 변수 input , di , sum 생성
- while문 조건 0이되면 탈출
- 반복문안에 조건문 input이 0이되면 탈출
- sum 에다가 뭘더한다음에 di를 곱함.
- di에 2를 곱함 2진수에서 다음자리수를 의미
- input에서 10을 나누는것은 끝의 자릿수 제거를 의미
- 그럼 input (a)(b)는 0출력 혹은 1출력이 되어야함. -> 나머지를 사용하면되지않을까?? %10 이라고한다면
ex_ 101110%10 하면 나머지 0 , 10111%10하면 나머지 1 ok!
정답 (a) : % (b) : 10
다양한 정답이있음


- TCP/IP에서 패킷을 처리할때 발생되는 문제를 알려주는 프로토콜
- 게이트웨이 - 네트워크 문제가 있는지확인하기위한 목적
- ()Flooding
- ping명령을 통한 공격
풀이 : ping명령을 통한 공격이면 알것같은데 ... TCP가뭐였더라...
ICMP??

✅ 1. TCP (Transmission Control Protocol)
🔍 TCP란?
신뢰성 있는 데이터 전송을 위한 연결 지향형(연결 기반) 전송 프로토콜
즉, 데이터를 순서대로, 빠짐없이, 정확하게 전달하기 위한 약속된 규칙(Protocol)이야!
📦 TCP의 주요 특징
특징 설명
✅ 연결 지향(Connection-oriented) 데이터를 보내기 전에 상대방과 연결(3-way handshaking)
✅ 신뢰성 보장 순서 보장, 재전송, 오류 검출 등
✅ 흐름 제어 수신자의 처리 속도에 맞춰 전송
✅ 혼잡 제어 네트워크 혼잡 상태에 따라 전송량 조절
💬 실생활 비유
TCP는 카톡 메신저처럼,
"상대가 받았는지 확인하고, 안 받으면 다시 보내주는 통신"
✅ 2. TCP/IP가 사용되는 계층
💡 먼저, 용어 구분부터!
TCP/IP는 프로토콜 이름이기도 하고,
동시에 계층 구조 모델의 이름이기도 해!
(OSI 7계층보다 실제로 더 많이 사용돼)
📦 TCP는 TCP/IP 4계층 모델의 "전송 계층"에 해당!

- 인터페이스 역할을하는 클래스
- 중간에 가로채서 다른 동작을 수행하는 객체로 변경
- 객체를 정교하게 제어 , 객체를 참조
- 분리된 객체
- 분리된객체를 동적으로 연결 객체의 실행 시점을 관리
풀이 : 객체가 분리된 것으로보아 행위 패턴이아닐까?? 무슨 패턴인지 이름은 모르겠으나 제어를한다니 제어패턴아닐까

gpt
Proxy(대리인) 패턴은
어떤 객체에 접근하기 전 중간에 대리 객체를 두어,
제어, 접근 제한, 추가 기능, 실행 시점 관리 등을 수행하는 구조 패턴
패턴 유형 : 구조 패턴
목적 : 객체 접근을 간접적으로 제어하거나 지연 실행, 보안/캐싱 등 추가 기능 삽입
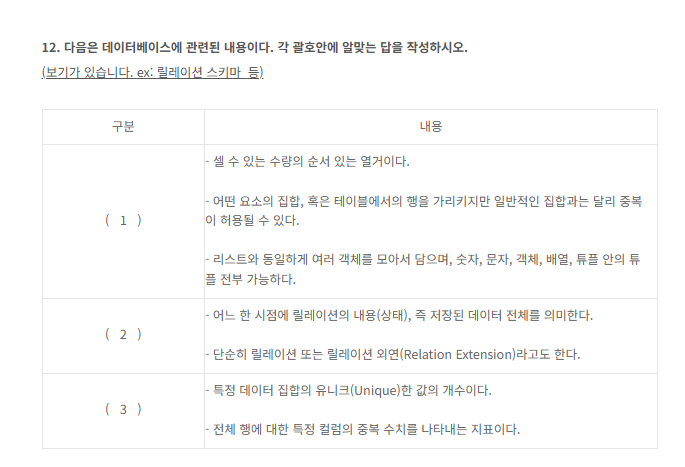
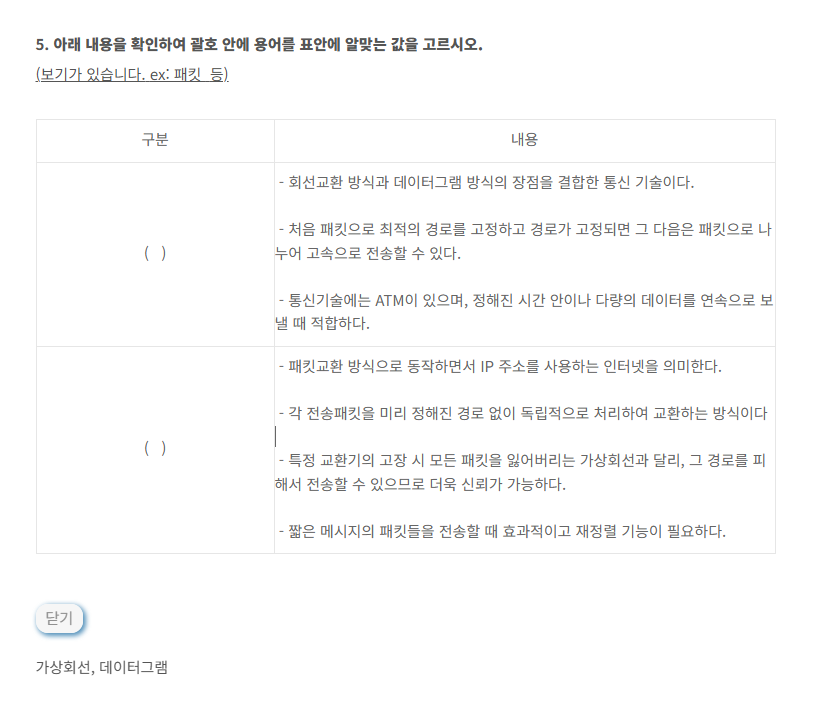
- 셀 수 있는 수량 , 순서 있는 열거
- 행을 가르킴 , 중복이 허용됨
- 리스트와 동일 , 여러 객체를 모아서 담음
풀이 : 셀 수 있고 행을가르키면 카디널리티아닌가??
- 어느 한시점에 릴레이션 , 저장된 전체 데이터
- 릴레이션 또는 외연이라고도함.
풀이 : 릴레이션 , 외연이 정확하게 뭔지모르겠으나 한시점에 저장된 데이터는 테이블아님??
- 특정 데이터 집합의 유니크
- 전체 행에 대한 특정 컬럼의 중복 수치
풀이 : 특정 데이터 집합의 유니크면 후보키 일 것 같음 , 컬럼의 중복수치가 뭘 가르키는거지??
정답

지피티
✅ 1번: 셀 수 있는 수량의 순서 있는 열거 → 튜플 (Tuple)
🔍 네 풀이:
"셀 수 있고 행을 가리키면 카디널리티 아닌가?"
→ 💡 착각 포인트야!
카디널리티는 "유니크한 값의 개수", 즉 속성(컬럼) 중심의 개념이고,
여기서 말하는 건 행(row), 즉 레코드를 의미해!
튜플 = 행(Row) = 하나의 데이터 레코드
카디널리티행(Row)의 수 = 전체 튜플 개수
✅ 2번: 릴레이션의 한 시점의 상태 → 릴레이션 인스턴스 (Relation Instance)
🔍 네 풀이:
릴레이션/외연이 뭔지 모르겠지만, 저장된 데이터니까 "테이블" 아닐까?
→ 오케이, 거의 근접했어!
여기서 말하는 건 정적인 "테이블 구조"가 아니라,
그 구조에 따라 실제로 채워진 데이터 = "릴레이션의 인스턴스 상태"야.
한 시점의 릴레이션 → 특정 시간의 "데이터 상태"를 의미
저장된 데이터 전체 → 즉, 현재 테이블에 있는 실제 데이터
외연(Extension) → 인스턴스와 같은 말 (내포는 스키마!)
✅ 3번: 유니크한 값의 개수 → 카디널리티 (Cardinality)
🔍 네 풀이:
후보키 아닐까? 유니크하면... 컬럼 중복 수치는 뭘까?
→ 여기도 혼동되기 쉬운 포인트!
후보키는 유일성을 보장하는 키 후보를 말하는 거고,
카디널리티는 어떤 컬럼 안에 "서로 다른 값이 몇 개인가"를 말해!
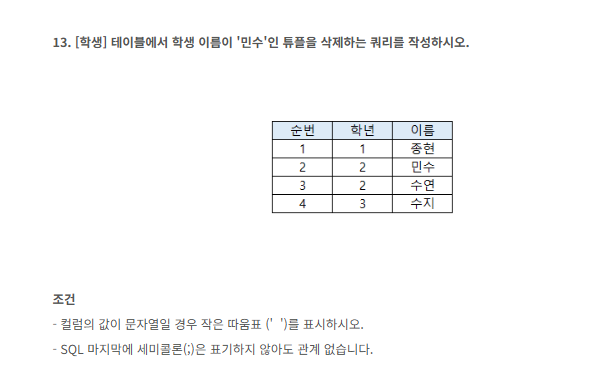
- 튜플을 삭제하는 쿼리문을 알야함
- 아마 DELETE 어쩌구 일 것으로 예상 , 혹은 DROP 어쩌구 근데이건 테이블 삭제할 때 사용하는 것같으니 DELETE로가자
- 임의로 작성한 SQL문
DELETE 학년
FROM 학생
HAVE 학년 = 2
정답

지피티
정답 : DELETE FROM 학생 WHERE 이름 = '민수'
잘한 점 : DELETE, FROM 방향성은 OK
고쳐야 할 점 : DELETE는 컬럼이 아니라 행 삭제, HAVING → WHERE로 수정 필요
팁 : 문자열 조건은 꼭 '작은따옴표' 사용!
HAVING -> GROUP BY랑 함께 쓰이는 조건절 (평균, COUNT 등에만 사용)
14. 다음 코드에서 괄호안에 알맞는 값을 변수명으로 작성하시오.
public class Sort { public static void swap(int[] arr, int idx1, int idx2){ int temp = arr[idx1]; arr[idx1] = arr[idx2]; arr[( 1 )] = temp; } public static void Usort(int[] array, int length){ for (int i = 0; i < length; i++) { for (int j = 0; j < length - i - 1; j++) { if (array[j] > array[j + 1]) { swap(array, j, j + 1); } } } } public static void main(String[] args) { int[] item = new int[] { 5, 3, 8, 1, 2, 7 }; int nx = 6; Usort(item, ( 2 )); for (int data : item) { System.out.print(data + " "); } } }
출력 값 : 1 2 3 5 7 8
- 오름차순으로 정렬되어있음
- swap함수가 자리를 바꾸려는 것으로보아 (1)은 idx2 일 것임
- main에서 배열 생성 , 변수 생성
- Usort에 배열과 어떤 값을 집어넣었음
- Usort함수 분석 2중 반복문임
- i길이만큼 반복 i는 length의 길이만큼
- j는 length에서 -i-1 한만큼 반복 이게 무엇을 의미하는가?
- 두번째 반복문안에서 오름차순 정렬이 일어남
- 의 의미 i가 증가하면 j는 그만큼 반복하는 횟수가 줄어듬 , 버블 정렬과같음
- 총 6번 반복해야하므로 Usort()에들어가는 (2)는 nx가 됨
정답 : idx2, nx

- a라는 아마도 튜플?? 생성
- 베트남 추가, 중국 (이미있음) 추가, 일본제거 // 한국 중국 베트남
- update는 아마도 여러개를 add 하는것과 비슷할 것 같음 홍콩
- 한국(이미있음), 태국, 홍콩 추가
- 정답은아마도 , {한국 중국 베트남 홍콩 태국} ??

지피티
집합(set)으로 인식 ✅ 정확하게 set으로 이해했어 (튜플 아님!)
add vs update 차이 인식 ✅ add는 하나 추가, update는 여러 개 추가 → 잘 구분했어
중복 제거 특징 인식 ✅ set은 중복 허용하지 않는다는 점도 잘 짚었어
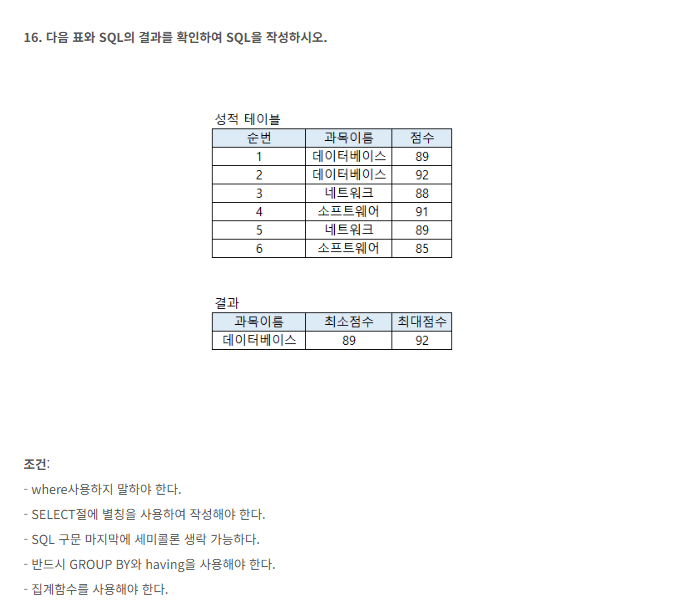
- 테이블에서 결과 도출하는 sql문 작성
- 조건을 참고할 것
- 임의로 작성한 sql문
SELECT 과목이름 AS MIN 최소점수 , AS MAX 최대점수
FROM 성적
GROUP BY 점수
having DECRESE
정답

지피티
SELECT 사용 ✅ 시작 구조 잘 잡음
GROUP BY 사용 시도 ✅ 필수 조건 고려함
AS 키워드 시도 ✅ 별칭(alias) 개념 접근했음
AS MIN 최소점수 ❌ 문법 오류 MIN(점수) AS 최소점수 형태로 써야 함
GROUP BY 점수 ❌ 잘못된 기준 → 과목이름으로 그룹화해야 함
HAVING DECRESE ❌ 존재하지 않는 키워드 → HAVING AVG(점수) >= 90 등 집계 조건 사용해야 함
✅ 기억 포인트 정리 (자격증 대비)
개념 설명 예시
MIN(컬럼) 최소값 MIN(점수)
MAX(컬럼) 최대값 MAX(점수)
AVG(컬럼) 평균값 AVG(점수)
GROUP BY 그룹핑 GROUP BY 과목이름
HAVING 집계 후 조건 HAVING AVG(점수) >= 90
AS 별칭 설정 AS 최소점수
✅ 집계함수 사용 필수 (MIN, MAX, AVG 등)
17. 다음 JAVA 코드에서 알맞는 출력 값을 작성하시오.
abstact class Vehicle { String name; abstract public String getName(String val); public String getName() { return "Vehicle name: " + name; } } class Car extends Vehicle { public Car(String val) { name=super.name=val; } public String getName(String val) { return "Car name:" + val; } public String getName(byte val[]) { return "Car name:" + val; } } public class Main { public static void main(String[] args) { Vehicle obj = new Car("Spark"); System.out.println(obj.getName()); } }
- Car객체 생성 객체명 obj
- obj에서 getName 메서드 호출
- Car객체에 getName메서드가 두개있음 , 그리고 1.에서 객체 생성했을때 부모 클래스를 호출 했었음 부모클래스 Spark
- 2.에서메서드 호출할때 인스턴스 안보냈음
- 인스턴스가 없을때 호출하는 메서드는 Car객체의 부모클래스인 Vehicle클래스에 존재
- Vehicle name: Spark 일것으로 추정됨
정답
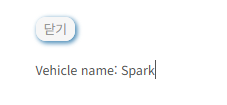
지피티
호출된 메서드 : getName()은 Vehicle 클래스의 기본 메서드
name 값 : 생성자에서 "Spark"로 설정됨
추가정보
오버라이딩 : getName(String) ← Car에서 오버라이딩
오버로딩 : getName(byte[]) ← Car에서 오버로딩 (다른 시그니처)
| 구분 | 오버라이딩 (Overriding) | 오버로딩 (Overloading) |
|---|---|---|
| 의미 | 상속받은 메서드를 "덮어쓰기" | 같은 이름의 메서드를 여러 개 만들기 |
| 클래스 | 부모 → 자식 관계 | 같은 클래스 안에서 정의 |
| 조건 | 메서드 이름, 파라미터(개수+타입), 리턴형 전부 완전히 같아야 함 | 메서드 이름만 같고, 파라미터는 달라야 함 |
| 목적 | 부모 기능을 내 방식대로 바꾸기 | 다양한 입력을 받을 수 있게 확장하기 |

- 개인의 입장에서 필요한 데이터베이스의 논리적 구조를 정의
- 데이터베이스에서 한 논리적인 부분
- 서브 스키마
- 하나의 DB안에 여러개의 외부 스키마 존재
- 하나의 외부 스키마를 여러개의 프로그램(혹은 사용자)에서 공유
풀이 : 정답이 문제에 있는것같음 서브 스키마 아닐까?? 데이터베이스 내부에 한부분이잖아. , 그리고 하나의 db안에 있는 여러개의 외부 스키마가 의미하는바가 하나의 db안에 각각의 서브 스키마를 의미하는 것은 아닐까?? , 개념적 스키마로 예상됨
- 데이터베이스의 전체적인 논리구조
- 필요한 데이터를 종합한 조직 전체의 데이터베이스로 하나만 존재
- 보안 및 무결성 규칙에 관한 명세를 정의
- 데이터베이스 파일에 저장되는 데이터 형태
- 기관이나 조직체의 관점에서 데이터베이스를 정의한 것
풀이 : 필요한 하나의 DB로 존재하고 , 명세도하고 뭐일까.. 개체스키마 이런 단어가 있나?? , 논리적 스키마로 예상됨
- 물리적인 저장장치입장에서 데이터가 저장되는 방법을 기술
- 실제 db에 저장될 물리적인 구조
풀이 : 물리적 스키마 일것으로 예상
지피티
오답은 없고, 용어 선택이 약간 헷갈렸을 뿐! 전체적인 맥락은 다 정확히 잡았어! 💯
| 스키마 종류 | 정의 | 관점 | 예시 비유 |
|---|---|---|---|
| 외부 스키마 | 사용자/프로그래머가 보는 부분적 논리 구조 | 사용자 관점 (View) | 앱 사용자 화면, 마이페이지 |
| 개념 스키마 | DB 전체의 논리적 구조, 관계/제약/보안 포함 | 조직 전체 관점 | 회사 전체 데이터 설계도 |
| 내부 스키마 | 물리적 저장 구조, 저장 방식/순서/인덱스 등 | 시스템 관점 (Storage) | 창고 배치도, 실제 상자 구조 |
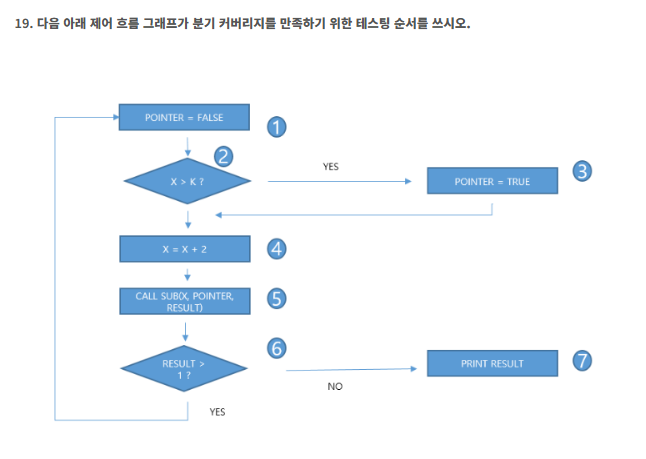
- 분기커버리지는 아마도 분기별로 나눠서 모든 흐름을 한번씩 겪어보는 것
- 예상 테스팅순서
X>K (T) 트루 한번했음 , RESULT(F) 폴스 한번했음
X>K (F) 폴스 한번했음 , RESULT(T) 트루 한번했음
1 2 3 4 5 7
1 2 4 5 6 1
정답
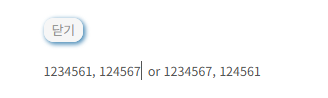
20. 다음 자바 코드에 대한 출력 값을 작성하시오.
class Parent { int x = 100; Parent() { this(500); } Parent(int x) { this.x = x; } int getX() { return x; } } class Child extends Parent { int x = 4000; Child() { this(5000); } Child(int x) { this.x = x; } } public class Main { public static void main(String[] args) { Child obj = new Child(); System.out.println(obj.getX()); } }
- Child 객체 생성, 객체명 obj
- obj의 메서드 getX()호출
- Child객체에 obj메서드가없음
- 부모클래스의 getX()
- 부모클래스의 생성자가 예상이안가서 x가 어떻게 출력될지모르겠음.
- 예상되는값은 그래도 부모클래스에서 x가 100이니 100출력예상
정답

지피티
🔹 1단계: Child obj = new Child();
→ 기본 생성자 Child() 호출
Child() { this(5000); // 🔥 여기서 아래 생성자 호출됨! }
🔹 2단계: Child(int x) 호출됨
Child(int x) { this.x = x; // 🔥 자식 클래스의 x에 5000 저장 }
근데!! 👇
자바에서 모든 자식 클래스 생성자 호출 시
부모 클래스의 생성자도 자동으로 먼저 호출돼!
👉 super(); 가 생략되어 있음!
→ 그래서 부모 클래스의 Parent() 생성자가 먼저 실행됨
