pdf와 csv를 json으로 전처리
목적 : 벡터데이터베이스를 만들기 위해
import os import json import pandas as pd import pdfplumber from tqdm import tqdm from typing import List, Dict from pathlib import Path import re from collections import Counter import logging # 🔇 pdfminer 로그 레벨 낮추기 (CropBox 경고 제거용) logging.getLogger("pdfminer").setLevel(logging.ERROR) # 📌 불용어 리스트 (사용자 정의 확장) STOPWORDS = { "이", "그", "저", "및", "에서", "으로", "하고", "보다", "까지", "때문", "관련", "정보", "경우", "대한", "위한", "합니다", "따른", "또는", "따라", "한다", "있다", "관하여", "목적으로", "있는", "다음", "이상", "이하", "이런", "그런", "저런", "어떤", "무엇", "누구", "어디", "언제", "왜", "어떻게", "그것", "그녀", "그들", "우리", "너", "당신", "그대", "이것", "저것", "이하의", "처한다", "자는", "아니한다", "없는", "하는", "하는지", "하는가", "죄의", "죄를", "사실을", "이상의", "어느", "하나에", "해당되는", "해당하는", "해당", "경우에는", "관한", "본다", "전문개정", "호의", "정하는", "사람" } def extract_tags(text: str, top_k: int = 5) -> List[str]: text = re.sub(r"[^\uAC00-\uD7A3a-zA-Z\s]", " ", text) # 한글 및 영문 외 제거 words = re.findall(r'\b[가-힣]{2,}|\b[a-zA-Z]{3,}', text.lower()) # 한글 2자 이상 또는 영문 3자 이상 filtered = [w for w in words if w not in STOPWORDS] counter = Counter(filtered) return [w for w, _ in counter.most_common(top_k)] def chunk_text(text: str, chunk_size: int = 500) -> List[str]: sentences = re.split(r'(?<=[.!?])\s+', text) chunks, chunk = [], "" for sentence in sentences: if len(chunk) + len(sentence) < chunk_size: chunk += " " + sentence else: chunks.append(chunk.strip()) chunk = sentence if chunk: chunks.append(chunk.strip()) return chunks def process_pdf(filepath: str) -> List[Dict]: data = [] filename = os.path.basename(filepath) all_text = "" with pdfplumber.open(filepath) as pdf: for i, page in enumerate(pdf.pages): text = page.extract_text() or "" all_text += text + " " chunks = chunk_text(text) for idx, chunk in enumerate(chunks): data.append({ "page": i + 1, "chunk_id": f"{i + 1}-{idx + 1}", "source": filename, "text": chunk, "tags": extract_tags(chunk) }) # 파일 단위 태그 file_tags = extract_tags(all_text, top_k=10) for d in data: d["file_tags"] = file_tags return data def process_csv(filepath: str) -> List[Dict]: data = [] filename = os.path.basename(filepath) try: df = pd.read_csv(filepath, encoding="utf-8", low_memory=False) print(f"✅ CSV 파일 언어 및 포맷 인식 성공: {filepath}") except Exception as e: print(f"❌ CSV 파일 인식 실패: {filepath} - {e}") return [] all_text = "" for i, row in df.iterrows(): row_text = " ".join([str(cell) for cell in row.values if pd.notna(cell)]) all_text += row_text + " " chunks = chunk_text(row_text) for idx, chunk in enumerate(chunks): data.append({ "row": i + 1, "chunk_id": f"{i + 1}-{idx + 1}", "source": filename, "text": chunk, "tags": extract_tags(chunk) }) file_tags = extract_tags(all_text, top_k=10) for d in data: d["file_tags"] = file_tags return data def process_all_files(folder_path: str, output_dir: str): folder = Path(folder_path) os.makedirs(output_dir, exist_ok=True) for file in tqdm(list(folder.glob("*"))): print(f"\n🔄 Processing file: {file.name}") if file.suffix.lower() == ".pdf": try: chunks = process_pdf(str(file)) print(f"✅ PDF 추출 성공: {file.name} | OCR 여부: ❌ (pdfplumber 기준)") except Exception as e: print(f"❌ PDF 처리 실패: {file.name} - {e}") continue elif file.suffix.lower() == ".csv": chunks = process_csv(str(file)) else: continue # 개별 파일 저장 output_path = os.path.join(output_dir, f"{file.stem}_processed.json") with open(output_path, "w", encoding="utf-8") as f: json.dump(chunks, f, ensure_ascii=False, indent=2) print(f"📁 저장 완료: {output_path} ({len(chunks)} 청크)") # 전처리 실행 if __name__ == "__main__": input_folder = "C:/Users/r2com/Documents/final-project/embedding/Before_processing/6. 일상생활" output_folder = "C:/Users/r2com/Documents/final-project/embedding/After_processing/6. 일상생활" process_all_files(input_folder, output_folder)
흐름도
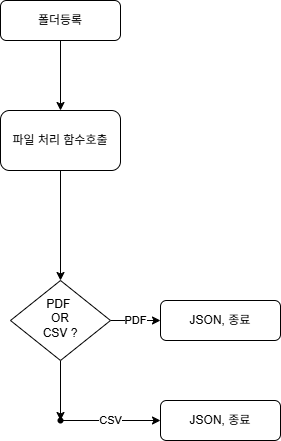
기본 흐름
1. 필요한 라이브러리들
import os import json import pandas as pd import pdfplumber from tqdm import tqdm from typing import List, Dict from pathlib import Path import re from collections import Counter import logging
pdfplumber : PDF 텍스트 추출
pandas : CSV 처리
tqdm : 진행 상태 랜더링
2. 저장될 파일 저장후 파일 input_folder , outputfolder 만듬
input_folder = "C:/Users/r2com/Documents/final-project/embedding/Before_processing/6. 일상생활" output_folder = "C:/Users/r2com/Documents/final-project/embedding/After_processing/6. 일상생활"
3. process_all_files 함수 호출
process_all_files(input_folder, output_folder)
, 매개변수로 input_folder , outputfolder를 사용
4. process_all_files(folder_path: str, output_dir: str)
folder = Path(folder_path) os.makedirs(output_dir, exist_ok=True)
folder는 Path 객체로 변환해서 파일 다루기 쉽게만듬
결과를 저장할 output_dir 폴더가 없으면 새로 만듦.
5. 반복문
for file in tqdm(list(folder.glob("*"))):
folder 안의 모든 파일을 가져와 하나씩 처리
tqdm으로 진행 상태를 보여줌 , 진행바
🔹 folder.glob("*") 의 의미
folder는 Path 객체로, 특정 폴더를 가리켜.
glob("*")는 해당 폴더 안의 모든 파일과 폴더를 가져오는 메서드야.
6. 파일 유형에 따라 분기
if file.suffix.lower() == ".pdf":
파일 확장자가 .pdf인 경우 process_pdf() 호출
elif file.suffix.lower() == ".csv":
.csv 이면 process_csv() 호출
7. 처리된 결과는 저장
output_path = os.path.join(output_dir, f"{file.stem}_processed.json")
파일 이름에서 확장자 제외한 stem만 가져와서 저장 파일 이름 지정
visa.pdf → visa_processed.json
with open(output_path, "w", encoding="utf-8") as f: json.dump(chunks, f, ensure_ascii=False, indent=2)
앞서 chunks에 저장된 전처리 결과 리스트를 JSON으로 저장
함수
1. extract_tags
한글 및 영문 제거 , 너무 자주 사용되는 용어 제거 , 가장많이 사용되는 데이터 상위 몇개 출력
2. chunk_text
텍스트 자르기 , 500사이즈로 자름
3. process_pdf
pdf를 청크별로 태그를 달아줌 , 파일 단위로 태그를 달아줌
4. process_csv
csv를 청크별로 태그를 달아줌 , 파일 단위로 태그를 달아줌

뭐가될지 모름