
-
출처
-
되도록이면 책의 내용과 코드를 그대로 옮기기 보다는 요약과 보충설명!
읽기 전에
개념 정리
회귀의 성능 지표
평균 제곱근 오차(RMSE: Root Mean Square Error)
: 가설 를 사용하여 일련의 샘플을 평가하는 비용 함수 (더보기)
: 제곱항을 합한 것의 제곱근 계산
: 실제 값과 예측 값의 차이를 제곱해 평균(=MSE)한 뒤 루트를 씌웠기 때문에, 실제 값과 유사한 단위로 다시 변환하여 해석이 용이해짐. 유클리디안 노름에 해당.
: MAE에 비해 덜 직관적이고, 조금 더 이상치에 민감. 그렇지만 종 모양 분포처럼 이상치가 매우 드물 경우 잘 맞아서 널리 사용됨.
평균 절대 오차(MAE: Mean Absolute Error)(평균 절대 편차 MAD: Mean Absolute Deviation)
: 절댓값의 합 계산
: 실제 값과 예측 값의 차이를 절댓값으로 변환해 평균냄. 맨해튼 노름.
: 직관적이고, 이상치가 많을 경우 사용하기 좋음. 즉 로버스트(robust)하다! 극단적인 이상치로부터의 영향을 덜 받는다.
- : 데이터셋의 모든 샘플의 (레이블을 제외한) 모든 특성값을 포함하는 행렬
- 예:
- : 시스템의 예측 함수, 즉 가설
- : 샘플 수
- : 예측값
: 시스템이 하나의 샘플 특성 벡터를 받으면, 그 샘플에 대한 예측값을 출력 - : 데이터셋에 있는 번째 샘플의 전체 특성값의 벡터.
- 예:
- : 번째 샘플의 레이블, 즉 기대 출력값
- 예:
 왜 사진 크기 조절이 안되지..?
왜 사진 크기 조절이 안되지..?
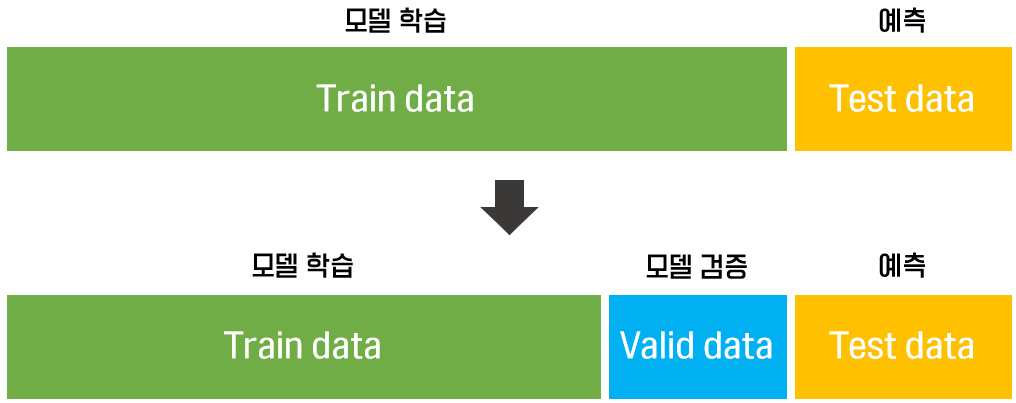
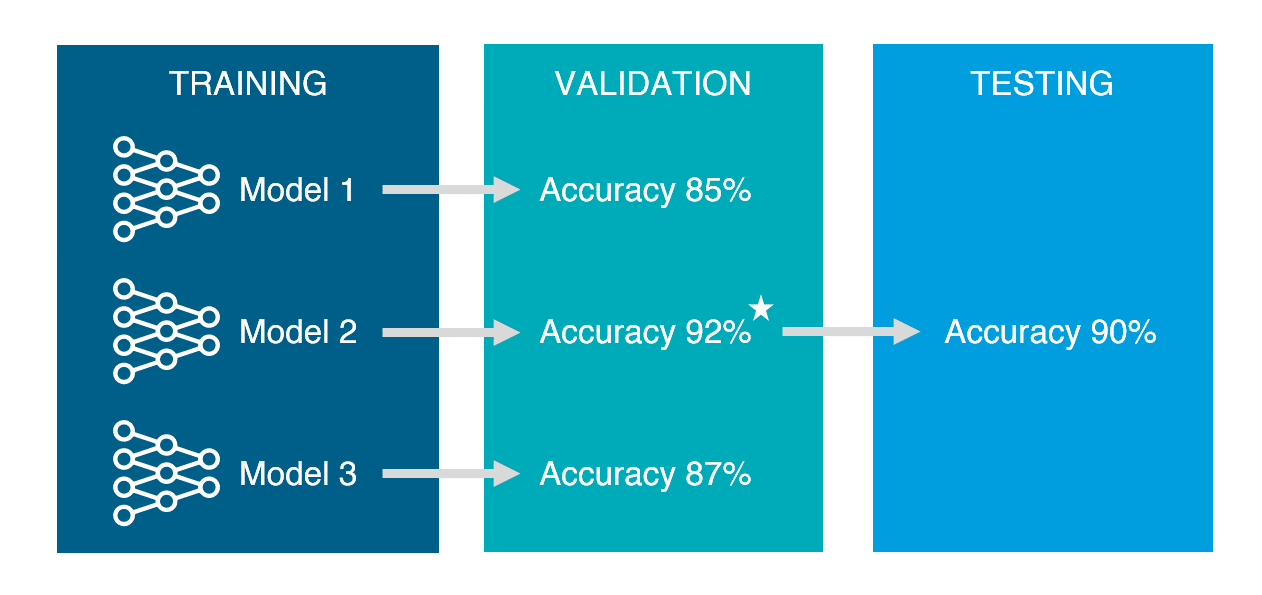
train, validation, test set
- train set: 모델 학습
- validation set: 학습된 모델을 검증. 최종 모델을 선정하기 위해 사용
- test set: 학습과 검증이 완료된 모델의 성능을 평가
사이킷런의 설계 원칙
- 일관성: 모든 객체가 일관되고 단순한 인터페이스를 공유(대부분 같은 함수나 파라미터를 사용)
- 추정기(estimator)
: 데이터셋을 기반으로 일련의 모델 파라미터들을 추정하는 객체.
:fit()으로 추정. - 변환기(transformer)
: 데이터셋을 변환하는 추정기.
: fit()된 데이터셋을 매개변수로 받아transform()로 변환된 데이터셋을 반환.
:fit_transform(): 값 추정과 자료 변환을 동시에, 즉 fit()과 transform()을 연달아 호출하는 것과 동일(method chaining). - 예측기(predictor)
:predict()로 새로운 데이터셋을 받아 예측값 반환
:score()로 예측의 품질을 측정
- 추정기(estimator)
- 검사 기능
: 사용자가 지정한 매개변수, 하이퍼파라미터는 strategy 같은거고, 사이킷런 class가 학습(훈련)한 결과는 statistics_ 처럼 언더바(_)를 붙임. - 클래스 남용 방지
- 조합성
- 합리적인 기본값
하이퍼파라미터(Hyper parameter)
: 모델링할 때 사용자가 직접 세팅해주는 값
원-핫 인코딩(one-hot encoding)
-
범주형 변수를 0과 1의 이진 벡터로 표시한다.
: 한 특성은 1, 나머지 특성은 0으로 표시
: 만약 n개의 특성이 존재한다면, n개의 특성 배열을 n차원 벡터로 표현 -
밀집된 넘파이 배열이 아닌 사이파이(ScyPy) 희소 행렬(sparse matrix)로 출력
: 밀집된 넘파이 배열로 바꾸려면OneHotEncoder(sparse=False)또는toarray()사용

희소행렬(sparse matrix)
: 행렬의 값이 대부분 0인 경우.
: 대부분 0인데, 이걸 행렬로 다 나열하는건 메모리 낭비임. 더 간단히 표현할 수 있음
: COO matrix, CSR matrix, DOK 방식 등
덕 타이핑(duck typing)
: 동적 타이핑의 한 종류로, 객체의 변수 및 메소드의 집합이 객체의 타입을 결정하는 것을 말한다.
"만약 어떤 새가 오리처럼 걷고, 헤엄치고, 꽥꽥거리는 소리를 낸다면 나는 그 새를 오리라고 부를 것이다."
: 객체의 속성이나 매서드가 (즉, 무엇을 할 수 있는지 없는지) 객체의 유형을 결정하는 방식
: 만약 두 class가 동일한 값을 출력한다면(가진 함수가 같다거나), 덕 타이핑에서는 두 class를 같은 타입으로 본다.
특성 스케일링(feature scaling)
min-max 스케일링(정규화 nomalization)
: 데이터에서 최솟값을 뺀 후, 최댓값과 최솟값의 차이로 나눠준다.
: 반환 결과는 0 ~ 1 범위로, 이 범위 안에 들도록 값을 이동하고 scale을 조정하는 방법
: 이상치에 매우 민감(이상치가 매우 크면 분모가 매우 커져서 변환된 값이 0 근처에 몰림)
표준화(standardization)
: 데이터에서 평균을 빼고 표준편차로 나누어 분산이 1이 되도록 해준다.
: 표준 정규 분포를 따르게 된다
: 이상치에 덜 민감
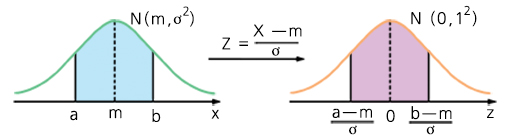
과대적합
- 과대적합을 해결하는 방법
- 모델을 간단히 만들기
- 제한(규제) 하기
- 더 많은 훈련 데이터를 모으기
k-겹 교차 검증(k-fold cross-validation)
: 훈련 세트를 k개의 폴드(fold)로 무작위 분할하여, k번 훈련하고 평가함.
: 훈련할 때마다 매번 다른 하나의 폴드를 평가에 사용, 나머지 k - 1개 폴드는 훈련에 사용. k개의 평가 점수가 담긴 배열을 생성
앙상블 학습
: 여러 다른 모델을 모아서 하나의 모델을 만드는 기법
: 즉, 교차 검증을 일반화 시킨 모델 학습법임.
: 머신러닝 알고리즘의 성능을 극대화는 방법 중 하나
python 정리
os: Operating System의 약자. 환경 변수나 디렉터리, 파일 등의 OS 자원을 제어할 수 있게 해주는 모듈.os.path.join(): 운영체제에 맞게 폴더 구분자를 다뤄서 경로를 생성해줌. 그냥 join이나 +로는 운영체제가 다를 때 에러가 발생하기 때문.
urllib.request.urlretrieve(): url에 대응되는 대상 압축파일을 사용자가 지정한 이름으로 다운받음.tarfile: 여러 개의 파일을 tar 형식으로 합치거나 이를 해제할 때 사용하는 모듈- 다운받은 tar 압축파일들을
tarfile.open()함수를 이용하여 열고,extractall()함수를 이용하여 지정한 경로에 압축 해제
- 다운받은 tar 압축파일들을
iloc( ): index 기반 selecting.loc( ): 라벨 값 기반 selecting.df.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise'): pandas dataframe의 행/열 삭제. axis(0: 행, 1: 열). inplace: 원본 변경 여부df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False): axis(0: 행 삭제, 1: 열 삭제), subset: 열 라벨toarray(): 희소 행렬을 밀집된 넘파이 배열로 바꿈get_params()와set_params(): 사이킷런의 파이프라인과 그리드 탐색에 꼭 필요한 메서드 (아직 이해X)np.c_: 열에 대하여 분리된 것을 연결 시켜줌 (행은 np.r_)데이터프레임명.values또는데이터프레임명.to_numpy(): 데이터프레임을 numpy 배열 형식으로 변환
2장 머신러닝 프로젝트 처음부터 끝까지
: 실제 데이터를 가지고 데이터 전처리부터 모델 훈련, 예측까지 전과정을 경험해보자
- 캘리포니아 주택 가격 데이터셋 사용
- 전체 주피터 노트북: https://github.com/rickiepark/handson-ml2
1. 큰 그림 보기
문제 정의
Q. 비즈니스의 목적이 정확히 무엇인가?
: 나의 모델의 출력이 다른 신호들과 함께 다른 머신러닝 시스템의 입력이 되는가?
Q. 현재 솔루션은 어떻게 구성되어 있는가?
머신러닝 분류 체계에 따르면.. (더보기)
- 지도 학습? 비지도 학습? 강화 학습?
- 분류? 회귀? 아님 다른거?
- 배치 학습? 온라인 학습?
- 정답: 지도 학습, 다중 회귀, 단변량 회귀, 배치 학습
: '중간 주택 가격' 레이블이 있고(지도 학습), 하나의 값을 예측 해야 하며(단변량 회귀), 예측에 사용할 특성이 여러개(다중 회귀)
- 정답: 지도 학습, 다중 회귀, 단변량 회귀, 배치 학습
성능 측정 지표 선택
: 회귀에서의 평가 지표를 선택하자
: RMSE? MAE?
가정 검사
: 예: 만약 출력된 가격 값이 하위 시스템에서 카테고리로 바꾼다면? 가격을 정확히 예측하는 건 필요 없고, 카테고리를 구하면 됨.
2. 데이터 가져오기
: 파이썬, 패키지, 주피터 노트북은 설치되어 있다고 하자.
데이터 다운로드
: housing.csv를 압축한 housing.tgz를 다운 받아 압축을 풀고, 판다스로 데이터를 읽어 들이면 데이터프레임으로 반환됨.
데이터 살펴보기
: head(), info(), value_counts(): 범주형 카테고리, describe(): 숫자형 특성, hist()
test set 만들기 (더보기)
-
why 지금 테스트 세트를 만들고, 보지 말아야 하는가?
: 데이터 스누핑 편향(data snooping)
: 우리의 뇌는 과대적합되기 쉬워서, 테스트 세트를 들여다보게 되면 겉으로 드러난 특성에 맞는 모델을 선택할지도 모름. 그렇게 되면 새로운 데이터에 잘 일반화 되지 않고 오차가 크게 발생하 것임. -
사이킷런(scikit-learn)의 model_selection 패키지 안에
train_test_split모듈을 활용하여 손쉽게 train set과 test set을 분리할 수 있음. -
책의 split_train_test()은 테스트 세트를 만들기 위한 일련의 과정을 보여준 예시일 뿐.
만약, 계층적 샘플링을 해야한다면?
- 예: 중간 소득이 중간 주택 가격을 예측하는데 매우 중요하다면.
pd.cut()으로 연속적인 숫자형인 'median_income'을 카테고리로 나누어 원본 데이터에 'income_cat' 추가- 계층 샘플링
2-1. 사이킷런의StratifiedShuffleSplit사용
2-2. 더 간편한 방법:train_test_split()의 stratify 파라미터 사용
: stratify에 지정된 target(여기서는 'income_cat')의 class 비율을 유지 한 채로 데이터 셋을 split함
: 책에 없는 이유는.. 저자가 집필 할 당시, stratify가 없었기 때문 - 계층적 샘플링이 끝났으니, 사용된 'income_cat'은
drop()으로 삭제
3. 데이터 이해를 위한 탐색과 시각화
plot()으로 산점도 그려보기
: 아하, 주택 가격은 지역과 인구 밀도에 관련이 매우 크구나!corr(),scatter_matrix로 피어슨 상관계수(r) 살펴보기- 여러 특성의 조합을 시도하기
: 전체 방의 개수를 가구 수로 나눈 가구 당 방 개수를 추가한다던가.. - 다시 상관관계 보기.. 반복하면서 데이터 탐색
4. 머신러닝 알고리즘을 위한 데이터 준비
: train set에서 예측 변수와 레이블을 분리.
- 이때, 수작업 하기 보다는 함수를 만들어서 데이터를 준비하자
: 새로운 데이터에도 쉽게 반복 가능하고, 여러가지 변환을 시도하는데 편리함.
데이터 정제
결측치(missing value)가 존재한다면?
- 해당 데이터를 제거한다(행 삭제)
:dropna()등 - 해당 특성을 삭제한다(열 삭제)
:drop()등 - 어떤 값으로 채운다(0, 평균, 중간값 등)
:fillna(), SimpleImputer 등
: 일반적으로 결측치가 너무 많지 않다면, 이 방법 선택
: 계산된 값을 저장하여, 시스템 평가 시 test set의 결측치와 실제 새로운 데이터의 결측치를 채워넣어야함.
- 사이킷런의
SimpleImputer클래스
: train setfit()한 다음에transform()하여(더보기) 모든 수치형 특성의 결측치를 중간값으로 대체
텍스트와 범주형 특성
- 사이킷런의
OrdinalEncoder클래스
:fit_transform()사용하여 범주형 카테고리의 텍스트를 숫자로 변환
범주형을 수치형으로 변환했을 때, 문제점
: 범주형을 숫자로 변환했을 때, 숫자(순서) 자체에는 아무 의미가 없을지라도 머신러닝 알고리즘은 가까이 있는 두 값을 떨어져 있는 두 값보다 더 비슷하다고 생각함.
: 예: 봄 여름 가을 겨울을 1, 2, 3, 4로 하면.. 가을은 봄의 3배의 의미를 지니는가? NO!
-> 더미 특성을 만들어서 해결하자
- 원-핫 인코딩(one-hot encoding) (더보기)
: 사이킷런의OneHotEncoder클래스
나만의 변환기 만들기
: 사이킷런은 상속이 아닌 덕 타이핑(더보기)를 지원한다.
: 따라서, fit(), transform(), fit_transform() 메서드를 구현한 파이썬 클래스를 만들면 사이킷런의 기능을 이용하여 어디서든 적용할 수 있는 나만의 변환기를 만들 수 있다.
TransformerMixin상속
:fit_transform()메서드BaseEstimator상속
: 하이퍼파라미터 튜닝에 필요한get_params()와set_params()를 얻게 됨(이때, no *args & **kargs)CombinedAttributesAdder()
: 나만의 변환기로 만든 클래스
: 조합 특성을 추가하는 변환기(가구당 방 개수, 가구당 인구 수, 방 수당 침대 수(선택))
주의 사항
- 모든 변환기의 fit() 메서드는 훈련 데이터에 대해서만 적용
- transform() 메서드는 모든 데이터에 대해 적용
- 훈련 세트를 이용하여 필요한 파라미터를 확인한 후 그 값들을 이용하여 전체 데이터셋트를 변환
: 예를 들어, 따로 떼어놓은 테스트 데이터들은 훈련 데이터를 이용하여 확인된 값들을 이용하여 특성 스케일링을 진행
특성 스케일링(feature scaling)(더보기)
: 일반적으로 머신러닝 알고리즘은 입력 숫자 특성들의 스케일이 많이 다르면 잘 작동하지 않음.
-
min-max 스케일링
: 사이킷런의MinMaxScaler변환기
: 사이킷런의Normalizer라는 전처리 기능과 혼동하지 말 것('정규화'는 여러 의미로 사용되니까 조심하자) -
표준화
: 사이킷런의StandardScaler변환기
변환 파이프라인
: 변환 단계가 많기 때문에, 정확히 순서대로 실행되는게 중요함
-
사이킷런의
Pipeline클래스
: 연속된 변환을 순서대로 처리
: 연속된 단계를 나타내는 이름/추정기 쌍의 목록을 입력으로 받고, 차례대로 fit()과 transform()을 하고, 한 단계의 출력을 다음 단계의 입력으로 전달. 마지막 단계에서는 fit() 메서드만 호출 -
ColumnTransformer클래스
: 하나의 변환기로 각 열마다 적절한 변환을 적용하여 모든 열을 처리
: 여기서는 수치형과 범주형 각각 변환
5. 모델 선택과 훈련
전처리 후 두 요소를 결정해야함
- 학습 모델: 회귀 모델
- 회귀 모델 성능 측정 지표: 평균 제곱근 오차(RMSE)
모델 훈련 시도
LinearRegression()으로 선형 회귀 모델 훈련- RMSE: 68628.198...
- 더 복잡한 모델 시도:
DecisionTreeRegressor()훈련
: 강력하고, 데이터에서 복잡한 비선형 관계를 찾을 수 있음- RMSE: 0.0
- 과대적합됨
교차 검증
: 테스트 세트를 보지 않기 위해 훈련 세트의 일부분으로 훈련을 하고 다른 일부분은 모델 검증에 사용하기로 함
-
train_test_split(): 훈련 세트를 더 작은 훈련 세트와 검증 세트로 나눔 -
훌륭한 대안: 사이킷런의 k-겹 교차 검증(k-fold cross-validation)(더보기)
: 결정 트리 교차 검증 RMSE 평균: 71407.687...
: 오히려 선형 회귀 모델보다 나쁜 결과- 선형 회귀 모델을 교차 검증하면?
: RMSE 평균: 69052.461...
- 선형 회귀 모델을 교차 검증하면?
-
앞서 결정 트리가 과대적합 되었기 때문에, 교차 검증에서 선형 회귀보다 나쁜 성능을 보임
-
RandomForestRegressor모델 교차 검증
: 특성을 무작위로 선택해서 많은 결정 트리를 만들고 그 예측을 평균 내는 방식.
: 앙상블 학습 (더보기)
: 훈련 세트에 대한 랜덤 포레스트 RMSE 평균: 18603.515...
: 교차 검증한 RMSE 평균: 50182.303...- 훈련 세트에 대한 점수가 검증 세트에 대한 점수보다 훨씬 낮으므로, 여전히 훈련 세트에 과대적합 되어 있음.
6. 모델 세부 튜닝
그리드 탐색
: 비교적 적은 수의 조합을 탐구할 때 사용
- 사이킷런의
GridSearchCV
: 탐색하고자 하는 하이퍼파라미터와 시도해볼 값을 지정하면, 모든 하이퍼파라미터 조합에 대해 교차 검증을 사용해 평가.RandomForestRegressor모델에 대해 시도
: RMSE: 49682.253...이 최적의 솔루션
랜덤 탐색
: 하이퍼파라미터 탐색 공간이 커질때 사용
RandomizedSearchCV
:GridSearchCV와 차이점은, 각 반복마다 하이퍼파라미터에 임의의 수를 대입하여 지정한 횟수만큼 평가.
앙상블 방법
최상의 모델과 오차 분석
: 최상의 모델을 분석하여 통찰을 얻을 수 있음. 예를 들어, 상대적으로 덜 중요한 특성을 제외하거나, 추가 특성을 포함하거나, 이상치를 제외할 수 있음.
테스트 세트로 시스템 평가하기
: 테스트 세트에서 예측 변수와 레이블을 얻은 후 full_pipeline을 사용해 데이터를 변환(이때, 테스트 세트에서는 훈련하면 안되므로 transform()만 호출해야함)하고 테스트 세트에서 최종 모델을 평가.
: RMSE: 47730
-
95% 신뢰 구간 측정하기
:scipy.stats.t.interval() -
하이퍼파라미터 튜닝을 많이 했다면, 검증 데이터에서 좋은 성능을 내도록 셈리하게 튜닝되었기 때문에 새로운 데이터셋에서는 조금 성능이 낮게 나오는게 일반적임.
7. 론칭, 모니터링, 유지보수
연습문제
: 본문을 다 이해한 다음에 하자..ㅜㅜ
궁금증
-
86p. "예를 들어 각 샘플마다 식별자의 해시값을 계산하여 해시 최댓값의 20%보다 작거나 같은 샘플만 테스트 세트로 보낼 수 있습니다."가 잘 이해되지 않습니다. 해시값은 그 샘플만의 고유값이며, 그 고유값은 변하지 않기 때문에 식별자로 사용한다는 것은 이해하였습니다. 그러나 '해시 최댓값의 20%보다 작거나 같은 샘플만 테스트 세트로 보낸다'는 것이 이해가 되지 않습니다. 만약 새로운 데이터가 추가되면, 그 데이터들의 해시 최대값이 현재 해시 최댓값보다 크다면 해시 최댓값의 20%가 변경되지 않나요? 즉 '해시 최대값'이 어떤 것을 의미하는지 궁금합니다.
-
105p. 나만의 변환기 제작 파트에서 BaseEstimator를 사용하는 이유가 이해되지 않습니다. 또한 get_params()와 set_params()를 포함하는데, 이 두 메서드가 *args나 **kargs는 사용할 수 없는 구체적인 이유가 무엇인지 궁금합니다. 생성자에 명시된 매개변수 이외의 다른 변수가 들어가면 어떤 오류가 발생하는걸까요?
-
108p. "파이프라인 객체는 마지막 추정기와 동일한 메서드를 제공합니다."가 잘 이해되지 않습니다. 본문에서는 StandardScaler가 마지막 추정기인데, 이것이 무엇을 의미하나요? 만약 본문의 세 추정기들간 순서가 바뀌면 어떤 일이 일어나는건가요?
