🍔 Group by
그룹별로 묶기
- 특정 컬럼의 값이 같은 것끼리 그룹으로 묶고, 집계 함수를 적용할 때 사용.
SELECT에는 그룹핑한 컬럼과 집계 함수만 올 수 있다
→ 이유: 그룹별로 하나의 결과만 출력해야 하므로, 그룹화되지 않은 일반 컬럼은 모호-- 직무별 평균 급여 구하기
select job, avg(sal)
from emp
group by job;그룹이 여러 개일 수 있다 → 예: job, deptno로 그룹
select job, deptno, sum(sal)
from emp
group by job, deptno;🦞 집계 함수 (Aggregate Functions)
✅ MAX, MIN, SUM, COUNT
- 여러 행의 데이터를 하나의 값으로 요약하는 함수.
- 집계 함수는 일반적으로
GROUP BY와 함께 사용
- 집계 함수는 일반적으로
-- 최대값 (MAX): 가장 큰 값을 구함
select max(sal) from emp;
-- 최소값 (MIN): 가장 작은 값을 구함
select min(sal) from emp;
-- 합계 (SUM): 숫자들의 총합
select sum(sal) from emp;
-- 평균 (AVG): 숫자들의 평균값
select avg(sal) from emp;
-- 개수 (COUNT): 행의 수를 셈 (null은 제외됨)
select count(*) from emp; -- 전체 행 수 (null 포함)
select count(comm) from emp; -- comm이 null이 아닌 행만 세어짐🥞 Having
그룹에 조건을 줄 때
GROUP BY로 생성된 그룹 결과에 조건을 줄 때 사용WHERE은 행(개별 레코드)에 조건 /HAVING은 그룹(요약된 집계)에 조건
-- 직무별 평균 급여가 2000 이상인 경우만
select job, avg(sal)
from emp
group by job
having avg(sal) >= 2000;🥊 WHERE vs HAVING
WHERE: 그룹핑 전에 데이터를 필터링 (행 단위 조건)HAVING: 그룹핑 후에 결과에 조건을 줌 (그룹 단위 조건)
-- sal 1000 이상만 고려해서 그룹화
select job, avg(sal)
from emp
where sal >= 1000
group by job;
-- 모두 그룹화한 후 평균이 1000 이상인 그룹만 추출
select job, avg(sal)
from emp
group by job
having avg(sal) >= 1000;🌮 집합 연산자 (Set Operators)
- 여러 개의
SELECT결과를 조합하는 연산자 - 조건: 열의 개수, 타입, 순서가 같아야 함
- 정렬은 맨 마지막
ORDER BY한 번만!

-- union: 중복 제거
select name from course1
union
select name from course2;
-- union all: 중복 포함
select name from course1
union all
select name from course2;
-- intersect: 교집합
select name from course1
intersect
select name from course2;
-- minus: 차집합
select name from course1
minus
select name from course2;
-- 별칭 쓸 때는 첫 번째 SELECT에서만 지정 가능
select name as n1 from course1
union
select name from course2
order by n1; -- 첫 SELECT의 alias 사용🍰 JOIN
- 여러 테이블을 연결해서 함께 조회할 때 사용
- 관계형 DB는 중복을 피하기 위해 데이터를 여러 테이블로 나누기 때문에 JOIN은 매우 중요!!!
🍬 INNER JOIN

select *
from emp
join dept on emp.deptno = dept.deptno;- 두 테이블에서 조건에 일치하는 공통 행만 조회
🍭 LEFT JOIN

select *
from emp
left join dept on emp.deptno = dept.deptno;- 왼쪽 테이블의 모든 행 + 오른쪽에서 조건 일치하는 것만
- 오른쪽에 없으면 NULL
🍡 RIGHT JOIN
select *
from emp
right join dept on emp.deptno = dept.deptno;- 오른쪽 테이블의 모든 행 + 왼쪽 조건 일치
🧁 FULL OUTER JOIN

select *
from emp
full outer join dept on emp.deptno = dept.deptno;- 양쪽 테이블의 모든 행 포함 (조건 불일치 시 NULL)
🍩 CROSS JOIN
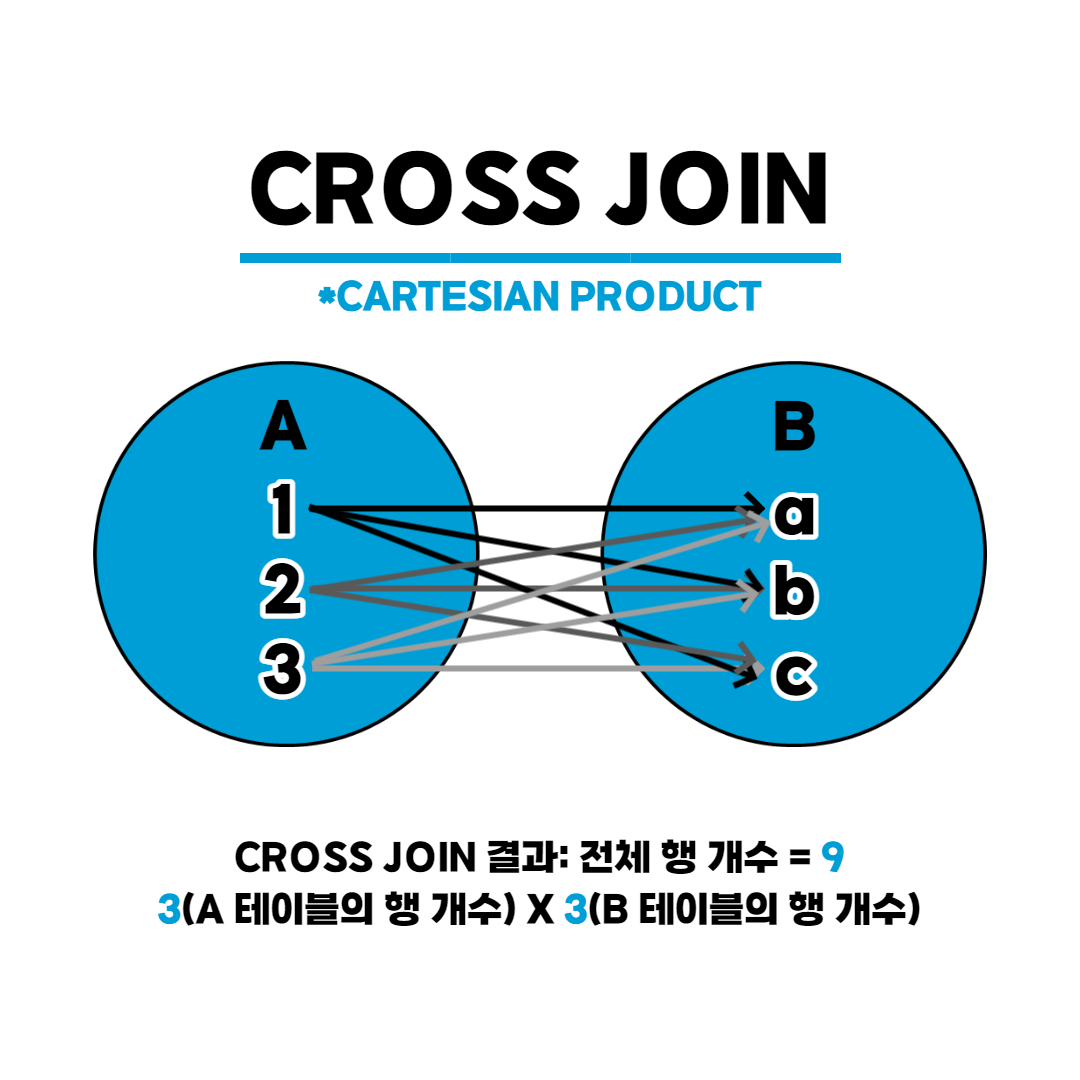
select *
from emp
cross join dept;
- 곱집합: 각 행마다 모든 행을 조합
+⍺ USING 절
- 공통 컬럼명이 같을 때, 중복 없이 자동 연결
select *
from emp
join dept using(deptno);+⍺ 조건부 JOIN
-- BETWEEN으로 범위 조건
select *
from emp
join salgrade on sal between losal and hisal;
-- 다른 조건도 가능!
select *
from emp
join salgrade on sal >= losal and sal <= hisal;-- JOIN 여러 개도 가능!
select *
from emp
join dept on emp.deptno = dept.deptno
join salgrade on sal between losal and hisal;
햇내기 개발자 지망생