따끈따끈한 면접 질문을 가져왔다
잊기전에 정리해서 잘 기억...해보자
그나저나 이력서에 블로그를 올렸더니 블로그를 다 보신다...머쓱..
인덱스란?
데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조를 일컫는다
-위키백과-
인덱스는 데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료 구조입니다. 특정 컬럼에 인덱스를 생성하면, 해당 컬럼의 데이터들을 정렬하여 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장됩니다. -코딩팩토리-
음 그러니까 인덱스는 데이터 베이스에 생성해서 검색 속도를 높여주는거구나?
하지만 인덱스가 뭔데 추가해서 왜 검색 속도가 빨라지지?
검색해보자
혹시 업앤다운 게임 아시나요?
/pic8397749.jpg)
상대방이 1부터 100까지의 수 중에 하나를 생각하면 내가 그 숫자를 찾는 게임인데
내가 부른 숫자가 생각한 숫자보다 작으면 다운
크면 업을 불러주면 됩니다
보통 그러면 많은 사람들이 어디서 부터 숫자를 물어볼까요?
1? 100?
대부분 50부터 말합니다 절반씩 잘라내면 더 빠르게 찾을 수 있으니까요
좋아 그럼 데이터 베이스로 가봅시다
| id | 이름 | 이메일 | 나이 |
|---|---|---|---|
| 1 | 이ㅇㅇ | lee@mail.com | 12 |
| 2 | 김ㅇㅇ | kim2@mail.com | 23 |
| 3 | 이ㅇㅇ | lee2@mail.com | 43 |
| 4 | 박ㅇㅇ | park2@mail.com | 26 |
| 5 | 최ㅇㅇ | choi@mail.com | 61 |
| 6 | 최ㅇㅇ | choi1@mail.com | 19 |
| 7 | 박ㅇㅇ | park1@mail.com | 35 |
| 8 | 김ㅇㅇ | kim4@mail.com | 20 |
이런 데이터가 있다고 생각해봅시다
나이가 35인 사람을 찾고 싶으면 데이터베이스는 멍청하게도 id 1부터 8까지 하나하나 찾습니다
업앤다운게임에서 1부터 혹은 100부터 하나하나 찾아가는 것이지요
|1|이ㅇㅇ|lee@mail.com|12| <- 1. 음 이게 아니군
.
|2|김ㅇㅇ|kim2@mail.com|23| <- 2. 음 이것도 아니군
.
.
.
.
|7|박ㅇㅇ|park1@mail.com|35| <- 7. 여기있다!
지금은 데이터가 8개니까 괜찮지만 데이터가 몇백개 몇천개 몇억개면 너무너무 느려지겠죠?
그렇다면 절반씩 잘라서 데이터를 찾는 방법은 어떨까요?

정말 좋은 방법이지만 이 방법에는 치명적인 단점이 있습니다
정렬되어있지 않은 데이터는 반반 전법을 쓸 수 없어요
그럼 어떻게 해야할까요? 나이 데이터를 따로 순서대로 정렬하는 방법은 어떨까요?
네 그럼 찾기 쉽겠네요! 저게 인덱스입니다
데이터 사본을 따로 정렬해서 저장한것이지요
하지만 문제가
테이블의 데이터는 계속 추가 / 삭제되므로 항상 정렬 상태를 유지하기 어려워요
데이터가 많아지면 일반적인 배열 탐색보다 더 빠른 구조가 필요해요
그래서 특별한 자료구조를 사용하여 인덱스를 관리하기로 합니다
바이너리 서치 트리
느낌은 비슷해요
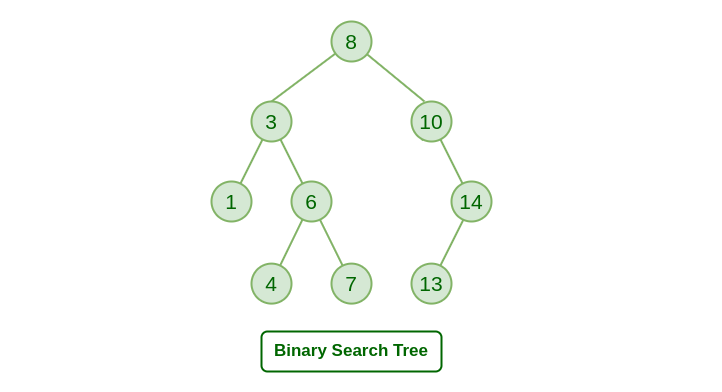
생각하시는 숫자가 4보다 작나요? 네
2보다 작나요? 아니요
그럼 3입니다!
B-Tree
바이너리 서치를 써봤는데 생각보다 좋았어요
그래서 레벨업된 친구 비트리를 만들었습니다
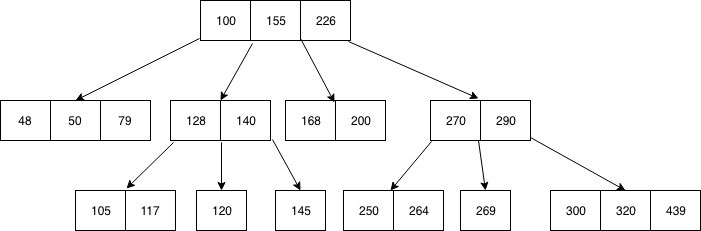
어때요 이제 반반 전법이 아니라 3분의 2씩 쳐낼수있는 트리가 완성되었어요
B+Tree
그러나
여기서 끝이 아니다!!

잔뜩 업그레이드된 비쁠트리
비쁠은 무려 노드들이 옆으로도 포인터를 가지고 있어 범위를 검색하기 좋습니다
아니 그런데 실제로 이걸 어케 써요
자자 봅시다
| id | 이름 | 이메일 | 나이 |
|---|---|---|---|
| 1 | 이ㅇㅇ | lee@mail.com | 12 |
| 2 | 김ㅇㅇ | kim2@mail.com | 23 |
| 3 | 이ㅇㅇ | lee2@mail.com | 43 |
| 4 | 박ㅇㅇ | park2@mail.com | 26 |
| 5 | 최ㅇㅇ | choi@mail.com | 61 |
| 6 | 최ㅇㅇ | choi1@mail.com | 19 |
| 7 | 박ㅇㅇ | park1@mail.com | 35 |
| 8 | 김ㅇㅇ | kim4@mail.com | 20 |
아까 그 데이터입니다 여기서 나이가 35인 사람을 찾아봅시다
나이만 따로 복사 정렬해둔 데이터 베이스에서 빠르게 나이가 35인 사람을 찾습니다
|나이|
|12|
|19|
|20|
|23| <- 1. 이것보다 크네
|26|
|35| <- 2. 찾았다
|43|
|61|그리고 해당 데이터에는 다른 정보도 저장되어있는데 원본 데이터의 주소입니다
인덱스에서 빠르게 정보를 찾고 해당 데이터의 주소를 따라 원본 데이터를 찾아갈 수 있습니다.
단점
인덱스라고 다 좋은 건 아니고 당연히 단점도 있는데요

1. 데이터가 추가되거나 변경될 때, 모든 인덱스도 함께 갱신해야 함
새로운 데이터를 추가할 때 모든 인덱스도 업데이트해야 합니다.
-> 인덱스가 많다면 INSERT/UPDATE/DELETE 작업 속도가 저하됩니다.
2.저장공간 증가
위에서 언급했듯, 인덱스는 데이터와 별도로 저장됩니다.
-> 인덱스가 늘어날 수록 디스크 공간을 많이 차지
특히 대용량 데이터베이스에서 불필요한 인덱스는 디스크 낭비를 초래할 수 있습니다.
이런 곳에서 써봅시다
- WHERE 조건이 자주 사용됨 -> ✅ 인덱스 가보자고
- JOIN에 사용되는 컬럼 -> ✅ 인덱스 OK
- ORDER BY, GROUP BY에 사용되는 컬럼 ->✅ 굿
자주 변경되는 컬럼 (UPDATE, DELETE...) -> ❌ 작업속도가....
너무 적은 데이터 (수백 개 이하의 행) -> ❌ 굳이 안 써도...
