풀이 시간
- 1h 34m
- 계속 RecursionError(47%에서)랑 메모리 초과(2%에서)가 떠서 삽질하다가 python3으로 제출하니까 한번에 맞음. 내 코드가 문제는 아니었던걸로..(https://www.acmicpc.net/board/view/35748)
구현 방식
-
dfs + dp (memoization)으로 풂
-
memoization을 사용하는 이유: 불필요하게 반복적으로 재귀하여 탐색하는 경우를 막고자, dp table에 한 번 갔던 곳의 dfs 결과 값을 저장하여 이를 재사용하기 위함이다
-
dp table에는 해당 위치에서 판다가 이동할 수 있는 칸의 최대 개수가 저장되어야한다
-
구현 흐름
-> dp table을 -1로 초기화하고 2중 for문을 돌며 dfs를 호출한다
-> dp[x][y]가 갱신되어있는 상태라면 dp[x][y]는 해당 위치에서 판다가 이동할 수 있는 칸의 최대 개수임을 보장하기 때문에, 더이상 탐색을 하지 않고 바로 dp[x][y]를 반환해준다
-> 그렇지 않다면 상하좌우를 탐색하면서 조건에 맞는 경우에 dfs(nx, ny)를 호출해주고, 그 중 최댓값 + 1(현재 칸도 포함)을 dp[x][y]에 할당해주고 이를 반환해준다
4
14 9 12 10
1 11 5 4
7 15 2 13
6 3 16 8- 위의 예제 입력에 대해 dp table이 생성되는 단계는 아래와 같다
[[1, -1, -1, -1], [-1, -1, -1, -1], [-1, -1, -1, -1], [-1, -1, -1, -1]]
[[1, 3, 1, -1], [-1, 2, -1, -1], [-1, 1, -1, -1], [-1, -1, -1, -1]]
[[1, 3, 1, 2], [-1, 2, -1, -1], [-1, 1, -1, -1], [-1, -1, -1, -1]]
[[1, 3, 1, 2], [3, 2, -1, -1], [2, 1, -1, -1], [-1, -1, -1, -1]]
[[1, 3, 1, 2], [3, 2, 3, -1], [2, 1, -1, -1], [-1, -1, -1, -1]]
[[1, 3, 1, 2], [3, 2, 3, 4], [2, 1, -1, 1], [-1, -1, -1, -1]]
[[1, 3, 1, 2], [3, 2, 3, 4], [2, 1, 4, 1], [-1, -1, 1, -1]]
[[1, 3, 1, 2], [3, 2, 3, 4], [2, 1, 4, 1], [3, -1, 1, -1]]
[[1, 3, 1, 2], [3, 2, 3, 4], [2, 1, 4, 1], [3, 4, 1, -1]]
[[1, 3, 1, 2], [3, 2, 3, 4], [2, 1, 4, 1], [3, 4, 1, 2]] -> 최종 dp table코드
import sys
sys.setrecursionlimit(10**6)
dx = (-1, 1, 0, 0)
dy = (0, 0, -1, 1)
def dfs(x, y):
if dp[x][y] != -1:
return dp[x][y]
cnt = 0
for i in range(4):
nx = x + dx[i]; ny = y + dy[i]
if 0 <= nx < N and 0 <= ny < N:
if board[nx][ny] > board[x][y]:
cnt = max(cnt, dfs(nx, ny))
dp[x][y] = cnt + 1 #현재 칸도 포함
return dp[x][y]
N = int(sys.stdin.readline()[:-1])
board = []
for n in range(N):
board.append(list(map(int, sys.stdin.readline()[:-1].split())))
dp = [[-1] * N for _ in range(N)]
max_cnt = 0
for i in range(N):
for j in range(N):
if dp[i][j] == -1:
max_cnt = max(max_cnt, dfs(i, j))
print(max_cnt)결과
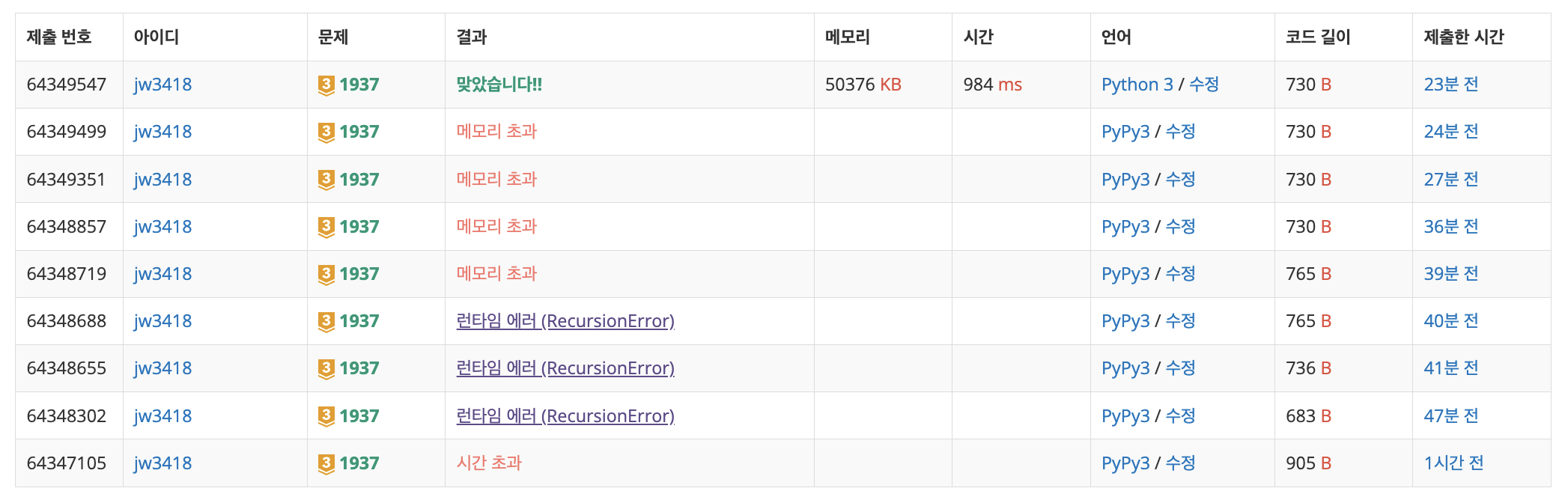
- setrecursionlimit과는 관계없이 pypy가 python3보다 더 많은 메모리를 잡아먹는 것 같다

💼 Software Engineer @ LG Electronics | 🎓 SungKyunKwan Univ. CSE