train.corr()['Survived']- 'Survived' Column과 다른 Column들 간의 상관관계
- 1에 가까울 수록 강한 양의 상관관계, -1에 가까울 수록 강한 음의 상관관계, 0에 가까울수록 두 변수 간에는 상관관계가 없음
# transform numeric variable age to categorical variable
bins = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
labels = ['<10', '<20', '<30', '<40', '<50', '<60', '<70', '<80', '<90']
train['Age_cat'] = pd.cut(train['Age'], bins, right=False, labels=labels)- numeric 변수를 categorical 변수로 변환
# aggregate how many survived passenger were according to sex and ages
train.groupby(['Sex', 'Age_cat'])['Survived'].sum().unstack('Age_cat')- unstack()은 pivot 기능을 함
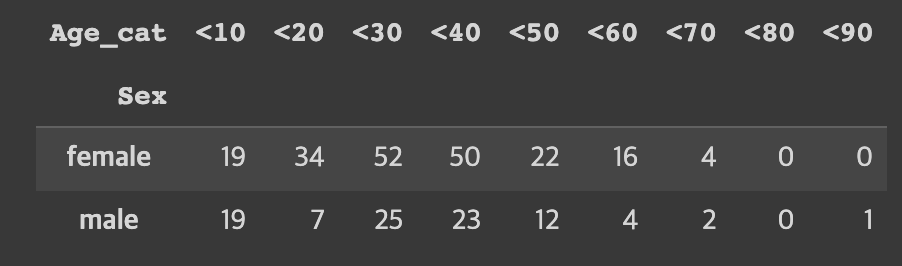
- 'Age_cat' Column이 열로 들어감 -> 2차원 데이터 형태로 변환됨
# aggregate how many survived passenger were according to sex and ages
train.groupby(['Sex', 'Age_cat'])['Survived'].sum().unstack('Age_cat')
# aggregate how many passenger were according to sex and ages
train.groupby(['Sex', 'Age_cat'])['Survived'].count().unstack('Age_cat')
# Ratio = Number of survived paseengers / Number of paseengers
round(train.groupby(['Sex', 'Age_cat'])['Survived'].sum().unstack('Age_cat')/train.groupby(['Sex', 'Age_cat'])['Survived'].count().unstack('Age_cat'), 2)- 'Sex', 'Age'별 생존자의 수를 전체 passenger의 수로 나누어 'Sex', 'Age'별 생존자의 비율을 표시

💼 Software Engineer @ LG Electronics | 🎓 SungKyunKwan Univ. CSE