Spark SQL
- 구조화된 데이터를 다루는한 SQL은 데이터 규모와 상관없이 쓰임
- 모든 대용량 데이터 웨어하우스는 SQL 기반
- Redshift, Snowflake, BigQuery
- Hive/Presto
- Spark도 예외는 아님
- Spark SQL이 지원됨
Spark SQL이란?
- Spark SQL은 구조화된 데이터 처리를 위한 Spark 모듈
- 데이터 프레임 작업을 SQL로 처리 가능
- 데이터프레임에 테이블 이름 지정 후 sql함수 사용가능
- 판다스에도 pandasql 모듈의 sqldf 함수를 이용하는 동일한 패턴 존재
- HQL(Hive Query Language)과 호환 제공
- Hive 테이블들을 읽고 쓸 수 있음 (Hive Metastore)
- 데이터프레임에 테이블 이름 지정 후 sql함수 사용가능
Spark SQL vs. DataFrame
- SQL로 가능한 작업이라면 DataFrame을 사용할 이유가 없음
- 하지만 두 개를 동시에 사용할 수 있다★
- Familiarity/Readability
- SQL이 가독성이 더 좋고 더 많은 사람들이 사용가능
- Optimization
- Spark SQL 엔진이 최적화하기 더 좋음 (SQL은 Declarative)
- Catalyst Optimizer와 Project Tungsten
- Spark SQL 엔진이 최적화하기 더 좋음 (SQL은 Declarative)
- Interoperability/Data Management
- SQL이 포팅도 쉽고 접근권한 체크도 쉬움
Spark SQL 사용법 - SQL 사용 방법
- 데이터 프레임을 기반으로 테이블 뷰 생성: 테이블이 만들어
- createOrReplaceTempView: spark Session이 살아있는 동안 존재
- createOrReplaceGlobalTempView: Spark 드라이버가 살아있는 동안 존재
- Spark Session의 sql 함수로 SQL 결과를 데이터 프레임으로 받음
SparkSession 사용 외부 데이터베이스 연결
- Spark Session의 read 함수를 호출(로그인 관련 정보와 읽어오고자 하는 테이블 혹은 SQL을 지정). 결과가 데이터 프레임으로 리턴됨
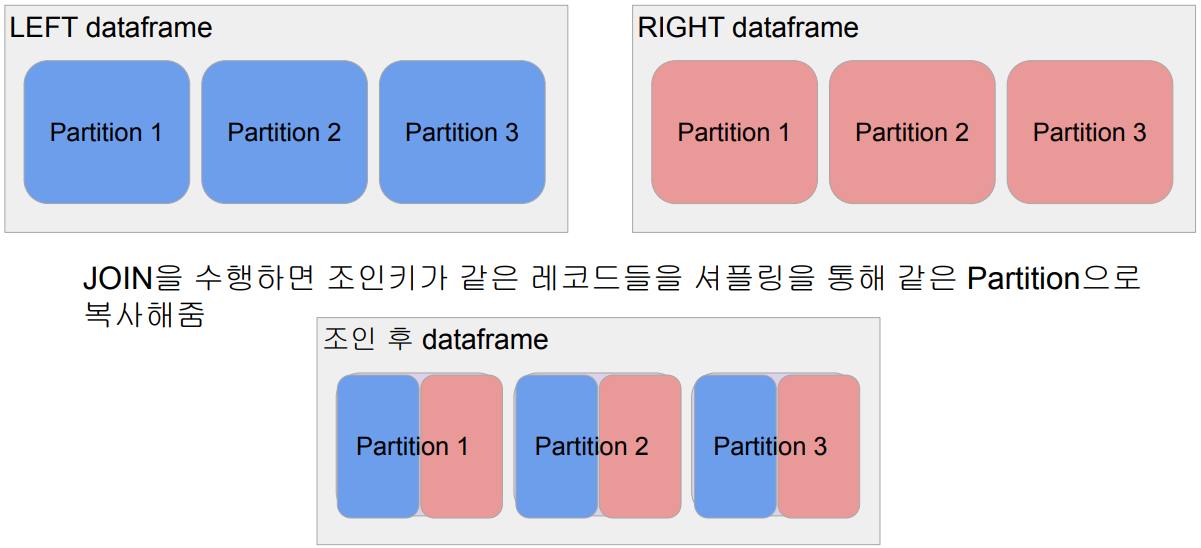
최적화 관점에서 본 조인의 종류들
- Shuffle JOIN
- 일반 조인 방식
- Bucket JOIN: 조인 키를 바탕으로 새로 파티션을 새로 만들고 조인을 하는 방식
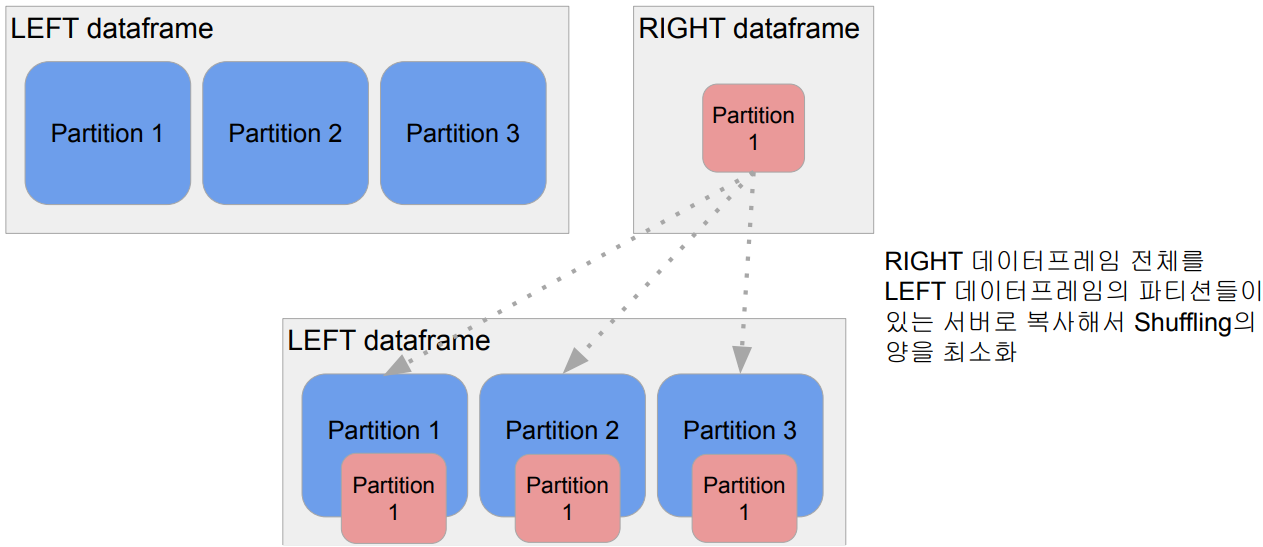
- Broadcast JOIN
- 큰 데이터와 작은 데이터 간의 조인
- 데이터 프레임 하나가 충분히 작으면 작은 데이터 프레임을 다른 데이터 프레임이 있는 서버들로 뿌리는 것 (broadcasting)
- spark.sql.autoBroadcastJoinThreshold 파라미터로 충분히 작은지 여부 결정

꾸준히 학습하고 기록하기 위한 log