
할머니께서 별세하셔서 잠시 TIL 작성을 중단하게 되었습니다. 오늘부터 다시 밀린 내용을 작성해보도록 하겠습니다.
1. 오늘의 학습 키워드
- 해시
- 리스트
- Counter
- 중복
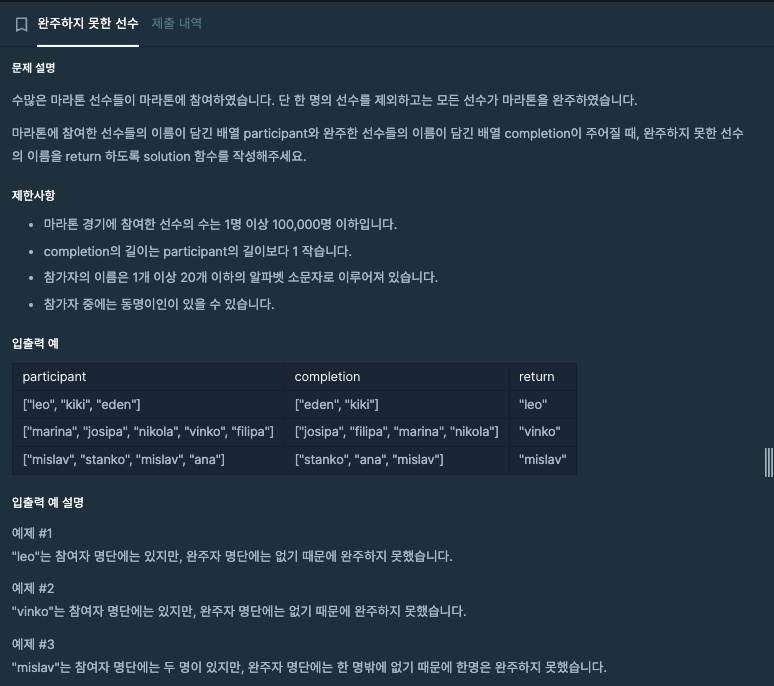
2. 문제: 완주하지 못한 선수
3. 나의 풀이
접근 방법
이 문제는 마라톤의 참가자와 완주자 명단을 주고, 완주하지 못한 선수의 이름을 return하는 문제이다. 완주하지 못한 선수는 단 1명이다. participant는 참가자, completion은 마라톤을 완주한 선수들의 이름이다.
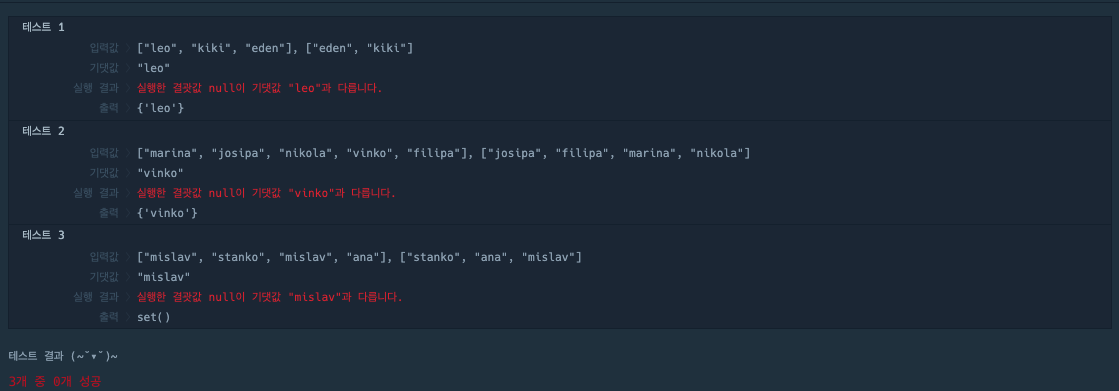
이 문제를 보자마자 떠올랐던 것은 집합 “자료형 (set)을 사용해서 빼면 되지 않을까?” 생각했다.
하지만, 참가자 명단에 같은 이름이 있으면, set() 을 사용한 방법에는 문제가 있다.
def solution(participant, completion):
print(set(participant)-set(completion))결과:
여기서 이제 생각한 방법은 Collections 모듈을 사용하는 방법이였다. Collections에서 Counter 메서드를 사용하면 되지 않을까? 생각해서 접근해보았다. 하지만 Counter함수에 대한 정확한 방법을 몰라 천천히 출력해보며 접근을 했다.
- 먼저, Collections 모듈의 Counter함수를 불러오고, participant와 completion 의 인자들을 Counter에 넣어보았다.
from collections import Counter
def solution(participant, completion):
print(Counter(participant))
print(Counter(completion))
결과:
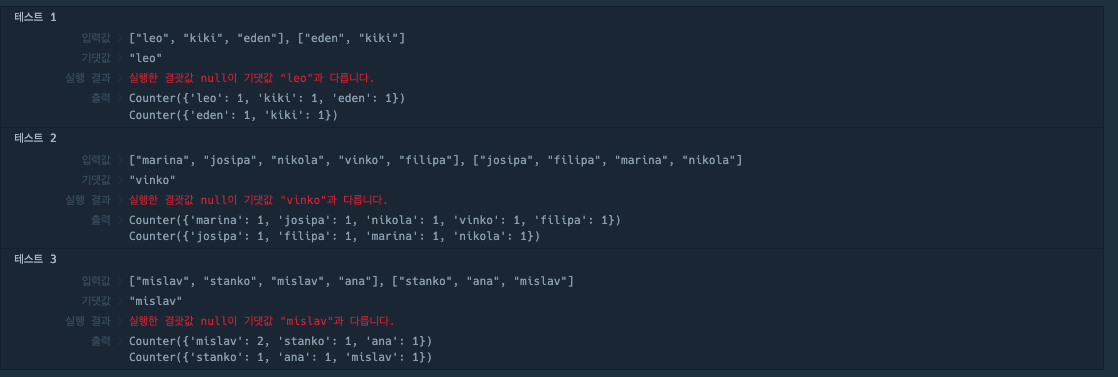
즉, 변수 (participant, completion)의 각 요소들이 변수안에 존재하는 횟수를 value, 요소를 key로하는 형태의 값이 생겼다.
- 1번에서 각 값들이 Counter({key:value, …, }) 형태로 나오는데 이것의 type이 뭘까?
from collections import Counter
def solution(participant, completion):
print(Counter(participant))
print(Counter(completion))
print(type(Counter(participant)))
print(type(Counter(completion)))결과:
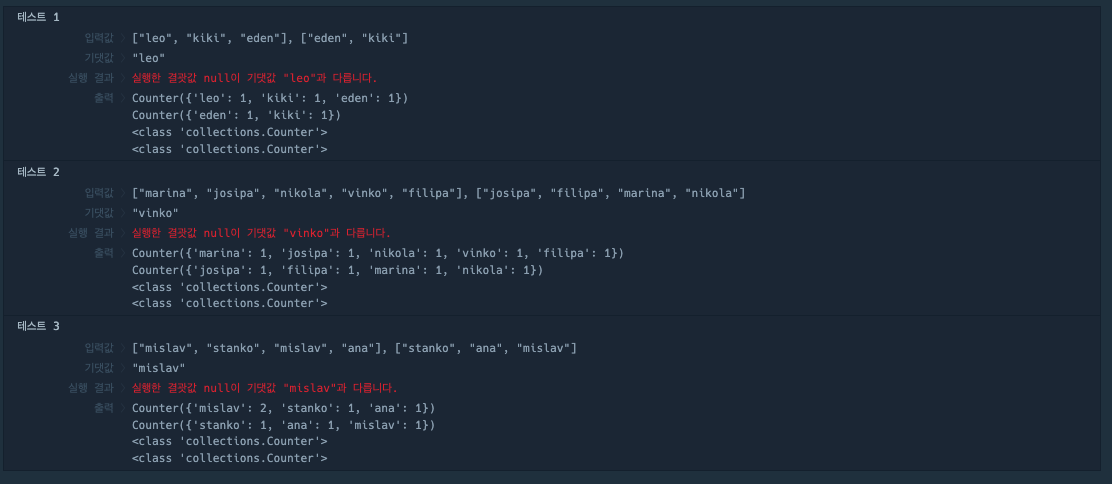
어떤 자료형에 Counter 메서드를 취하면 collections.Counter 카운터라는 클래스로 타입이 변경된다.
추후에 이 문제의 return값은 str이기 때문에, str로 변경해야 한다는 점을 명심하자.
- participant의 counter값과 completion의 counter값을 빼본다면 완주하지 못한 사람과, 그 사람이 몇명인지를 구할 수 있지 않을까?
이전에, set() 자료형을 사용하면, 중복된 값은 사라지기 때문에 participant에 동명이인이 있다면, 해결하지 못했다.
하지만, Counter(participant) - Counter(completion)을 수행한다면 participant와 completion의 같은 key에 해당하는 값의 차이를 알 수 있을것이다.
또한, 이 문제의 return 값은 str타입이므로, Counter(participant) - Counter(completion) 결과를 리스트로 변경하고 첫번째값을 가져온다면, participant에서 완주하지 못한 사람의 이름을 가져올 수 있다.
코드를 보자면 다음과 같다.
from collections import Counter
def solution(participant, completion):
return list(Counter(participant)-Counter(completion))[0]결과
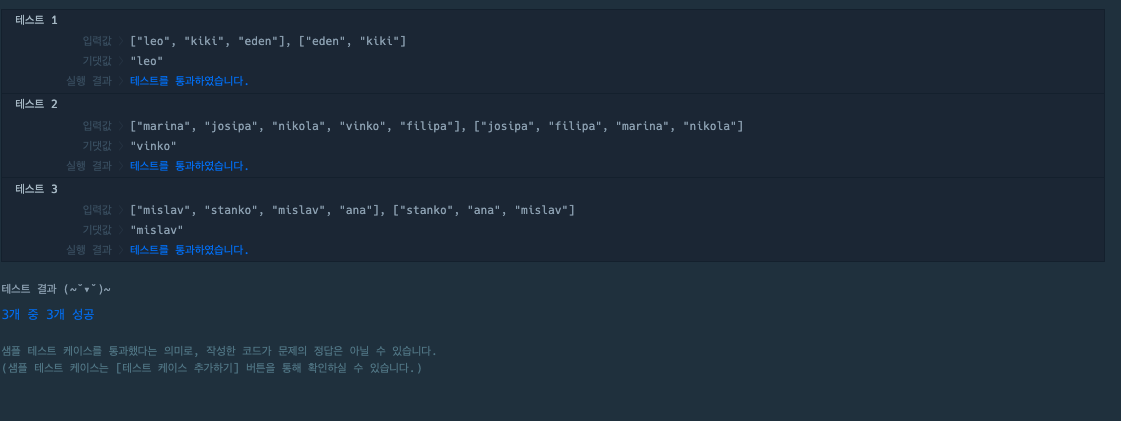

3.1 Collections
위 문제에서 Collections 모듈의 Counter 메서드를 사용했는데, Collections 모듈에서 자주 사용되는 메서드들을 알아보자.
Collections는 자료형을 도와주는 모듈
Collections 모듈은 파이썬의 자료형 (list, tuple, set, dict)들에게 확장된 기능을 주기 위해 제작된 파이썬의 내장 모듈이다.
이번 글에서는 Collections 모듈의 유용한 다섯 가지 클래스, namedtuple, deque, defaultdict, Counter, OrderedDict에 대해 알아보자. (필자는 deque, Counter를 써본 경험이 있다)
Collections module에서 제공하는 클래스는 다음과 같이 Import 하여 사용할 수 있다.
from Collections import 클래스명1. namedtuple
namedtuple은 튜플을 생성할 때 인덱스로만 접근하는 것 대신 이름으로 접근할 수 있도록 해주는 클래스이다. 이 클래스를 사용하면 코드를 이해하는 데 도움이 된다. 예를 들어, 좌표를 저장하는 튜플을 생성할 때, 다음과 같이 사용할 수 있다.
from collections import namedtuple
point = namedtuple('point',['x','y'])
p = point(1,2)
print(p) # point(x=1, y=2)
x,y = p
print(x,y) # 1 22. deque
deque는 스택 (Stack)이나 큐 (Queue)와 같은 자료구조를 구현하는 데 사용되는 클래스이다. deque라는 것은 double-ended queue의 줄임말이다.
이 클래스를 사용하면 리스트 대비 연산 시간을 더욱 효율적으로 사용할 수 있다.
덱 객체는 다음과 같은 메서드를 지원한다.
- append(x)
- dequq의 오른쪽에 x를 추가한다.
- appendleft(x)
- dequq의 왼쪽에 x를 추가한다.
- clear()
- deque에서 모든 요소를 제거하고 길이가 0인 상태로 만든다.
- count(x)
- x와 같은 deque 요소의 수를 센다.
- extend (iterable)
- iterable 인자에서 온 요소를 추가하여 덱의 오른쪽을 확장한다.
- extendleft (iterable)
- iterable에서 온 요소를 추가하여 덱의 왼쪽을 확장한다.
- index(x[, start[, stop]])
- 덱에 있는 x의 위치를 반환한다 (인덱스 start 또는 그 이후, 그리고 인덱스 stop 이전).
- insert(i, x)
- x를 덱의 i 위치에 삽입한다.
- pop()
- 덱의 오른쪽에서 요소를 제거하고 반환한다.
- popleft()
- 덱의 왼쪽에서 요소를 제거하고 반환한다.
- remove(value)
- 덱에 있는 value값 중 처음으로 등장한 value를 삭제한다.
- reverse()
- 덱의 요소들을 제자리에서 순서를 뒤집고 None을 반환한다.
- rotate(n=1)
- 덱을 n 단계 오른쪽으로 회전한다. n이 음수이면, 왼쪽으로 회전한다.
- 덱이 비어있지 않다면, 덱.rotate(1)을 하는 것은 덱.appendleft(덱.pop())와 같음.
- 또한, 덱.rotate(-1)을 하는 것은 덱.append(덱.popleft())와 같음
- maxlen
-
덱 생성시, 정했던 덱의 최대 크기, 정하지 않았으면 None을 반환
# 최대 크기를 정했을 시 from collections import deque # deque(iterable,maxlen: int) queue = deque('find', 3) print(queue) # deque(['i', 'n', 'd'], maxlen=3) print(queue.maxlen) # 3 -
maxlen이 지정되지 않거나
None이면, 덱은 임의의 길이로 커질 수 있습니다. 그렇지 않으면, 덱은 지정된 최대 길이로 제한됩니다. 일단 제한된 길이의 덱이 가득 차면, 새 항목이 추가될 때, 해당하는 수의 항목이 반대쪽 끝에서 삭제됩니다.
-
3. defaultdict
defaultdict는 딕셔너리의 기본값을 설정해 놓고 사용할 수 있는 클래스이다. 딕셔너리에 존재하지 않는 키를 참조할 경우 KeyError가 발생하는 것 대신 ,기본 값을 반환한다. 이 클래스를 사용하면 코드를 더욱 간결하게 만들 수 있다. 예를 들어, 다음과 같이 defaultdict를 사용하여 딕셔너리를 초기화 할 수 있다.
from collections import defaultdict
d = defaultdict(int)
print(d) # defaultdict(<class 'int'>, {})
d['a'] += 1
d['b'] += 1
print(d) # defaultdict(<class 'int'>, {'a': 1, 'b': 1})
print(d['c']) # 0defaultdict를 세는(counting)하는 데 유용하게 사용할 수 있다.
s = 'mississippi'
d = defaultdict(int)
for k in s:
d[k] += 1
print(d) # defaultdict(<class 'int'>, {'m': 1, 'i': 4, 's': 4, 'p': 2})4. Counter
Counter 클래스는 시퀀스(리스트, 튜플등)에서 각 요소가 몇 번 등장했는지를 셀 수 있는 클래스이다. Counter 클래스는 딕셔너리 형태로 요소와 등장 횟수를 지정한다.
from collections import Counter
fruits = ['apple','banana','apple','orange','banana','grape']
cnt = Counter(fruits)
print(cnt) # Counter({'apple': 2, 'banana': 2, 'orange': 1, 'grape': 1})Counter 객체는 다음과 같은 메서드를 지원한다.
- elements()
개수만큼 반복되는 요소에 대한 이터레이터를 반환한다. 요소는 처음 발견되는 순서대로 반환된다.
from collections import Counter
fruits = ['apple','banana','apple','orange','banana','grape']
cnt = Counter(fruits)
print(cnt.elements()) # <itertools.chain object at 0x7a220d94f2b0>
print(sorted(cnt.elements())) # ['apple', 'apple', 'banana', 'banana', 'grape', 'orange']
print(sorted(cnt.elements(),reverse=True)) # ['orange', 'grape', 'banana', 'banana', 'apple', 'apple']
- most_comon([n])
n개의 가장 흔한 요소와 그 개수를 가장 흔한 것부터 가장 적은 것 순으로 나열한 리스트를 반환한다. n이 생략되거나 None이면, most_common()은 모든 요소를 반환한다.
from collections import Counter
fruits = ['apple','banana','apple','orange','banana','grape']
cnt = Counter(fruits)
print(cnt.most_common(3)) # [('apple', 2), ('banana', 2), ('orange', 1)]
print(cnt.most_common()) # [('apple', 2), ('banana', 2), ('orange', 1), ('grape', 1)]- subtract([iterable-or-mapping])
이터러블이나 다른 매핑으로부터 온 요소들을 뺀다. 입력과 출력 모두 0이나 음수일 수 있다.
c = Counter(a=4, b=2, c=0, d=-2)
d = Counter(a=1, b=2, c=3, d=4)
print(c) # Counter({'a': 4, 'b': 2, 'c': 0, 'd': -2})
print(d) # Counter({'d': 4, 'c': 3, 'b': 2, 'a': 1})
c.subtract(d)
print(c) # Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6})- total()
compute the sum of the counts.
from collections import Counter
fruits = ['apple','banana','apple','orange','banana','grape']
cnt = Counter(fruits)
print(cnt) # Counter({'apple': 2, 'banana': 2, 'orange': 1, 'grape': 1})
print(cnt.total()) # 65. OrderedDict
OrderedDict 클래스는 딕셔너리를 상속받는 클래스로, 키-값 쌍의 추가 순서를 기억한다. 일반적인 딕셔너리는 키-값 쌍을 추가한 순서를 기억하지 않는다. 그러나 OrderedDict 클래스는 추가한 순서를 기억하기 때문에, 아래의 예제에서는 키-값 쌍의 추가 순서대로 출력된다.
하지만 파이썬 3.7 버전부터는 일반적인 딕셔너리도 순서가 적용된다.
from collections import OrderedDict
od = OrderedDict()
od['a'] = 1
od['b'] = 1
od['c'] = 2
print(od) # OrderedDict([('a', 1), ('b', 1), ('c', 2)])4. 다른 풀이 (Hash를 사용한 방법)
이 문제는 해시 자료구조를 사용하여 풀수도 있다. 접근해보자.
해시는 파이썬에서 딕셔너리로 사용할 수 있다. 또한 파이썬에서는 hash 함수가 주어지는데, 이것은 우리가 흔히 아는 hash function이라고 볼 수 있다.
- 해싱 함수 (Hashing Function) : Key에 대한 산술 연산을 이용해 데이터 위치를 찾을 수 있는 함수
즉, hash(데이터의 키) = 데이터 (값)
코드는 아래와 같다.
def solution(participant, completion):
hashdict = {}
sumHash = 0
# 1. Hash : Participant의 dictionary 만들기
# 2. Participant의 sum(hash) 구하기
for part in participant:
hashdict[hash(part)] = part # key는 hash한 값이 되고, Value는 각 선수의 이름이 된다.
sumHash += hash(part)
# 3. completion의 sum(hash) 빼기
for comp in completion:
sumHash -= hash(comp)
return hashdict[sumHash]5. 결론
이 문제는 해시라는 문제 종류가 미리 나와있어서, 해시로 풀 수 있었지만 만약 나와있지 않았다면 바로 Counter 모듈을 사용해서 풀 것 같다. 이런 문제를 여러 익혀서 좀 더 다양한 문제를 풀어봐야겠다.
읽어주셔서 감사합니다.
