
이번 문제는 링크드 리스트를 잘 이해하고 활용하는 방법을 익히는데 도움이 되는 문제라 생각합니다. 문제를 살펴볼까요?
1. 오늘의 학습 키워드
- Linked List
- Two Pointer
- Hash Table
2. 문제: 160. Intersection of Two Linked Lists
- 단계: Easy
- 주제: Hash Table, Linked List, Two Pointers
- 출처: https://leetcode.com/problems/intersection-of-two-linked-lists/description/?envType=problem-list-v2&envId=linked-list&difficulty=EASY
Description
Given the heads of two singly linked-lists headA and headB, return the node at which the two lists intersect. If the two linked lists have no intersection at all, return null.
For example, the following two linked lists begin to intersect at node c1:
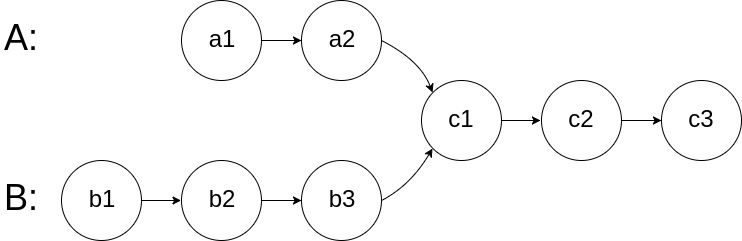
The test cases are generated such that there are no cycles anywhere in the entire linked structure.
Note that the linked lists must retain their original structure after the function returns.
Custom Judge:
The inputs to the judge are given as follows (your program is not given these inputs):
intersectVal- The value of the node where the intersection occurs. This is0if there is no intersected node.listA- The first linked list.listB- The second linked list.skipA- The number of nodes to skip ahead inlistA(starting from the head) to get to the intersected node.skipB- The number of nodes to skip ahead inlistB(starting from the head) to get to the intersected node.
The judge will then create the linked structure based on these inputs and pass the two heads, headA and headB to your program. If you correctly return the intersected node, then your solution will be accepted.
Example 1:
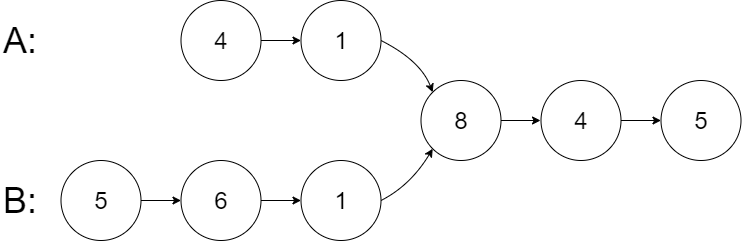
Input: intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
Output: Intersected at '8'
Explanation: The intersected node's value is 8 (note that this must not be 0 if the two lists intersect).
From the head of A, it reads as [4,1,8,4,5]. From the head of B, it reads as [5,6,1,8,4,5]. There are 2 nodes before the intersected node in A; There are 3 nodes before the intersected node in B.
- Note that the intersected node's value is not 1 because the nodes with value 1 in A and B (2nd node in A and 3rd node in B) are different node references. In other words, they point to two different locations in memory, while the nodes with value 8 in A and B (3rd node in A and 4th node in B) point to the same location in memory.
Example 2:
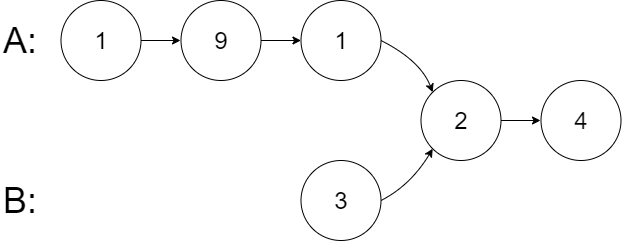
Input: intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
Output: Intersected at '2'
Explanation: The intersected node's value is 2 (note that this must not be 0 if the two lists intersect).
From the head of A, it reads as [1,9,1,2,4]. From the head of B, it reads as [3,2,4]. There are 3 nodes before the intersected node in A; There are 1 node before the intersected node in B.
Example 3:
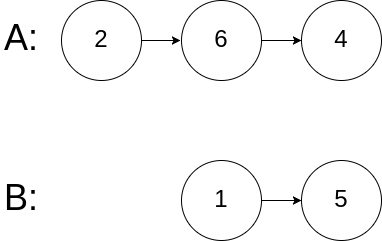
Input: intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
Output: No intersection
Explanation: From the head of A, it reads as [2,6,4]. From the head of B, it reads as [1,5]. Since the two lists do not intersect, intersectVal must be 0, while skipA and skipB can be arbitrary values.
Explanation: The two lists do not intersect, so return null.
Constraints:
- The number of nodes of
listAis in them. - The number of nodes of
listBis in then. 1 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA <= m0 <= skipB <= nintersectValis0iflistAandlistBdo not intersect.intersectVal == listA[skipA] == listB[skipB]iflistAandlistBintersect.
Follow up:
Could you write a solution that runs in O(m + n) time and use only O(1) memory?
3. 문제 풀이
Step1. 문제 이해하기
두 개의 단일 연결 리스트 headA와 headB가 주어졌을 때, 두 리스트가 교차하는 노드를 반환하는 문제입니다. 교차하지 않는다면 None을 반환합니다.
즉, 공통되는 노드를 찾으라는 문제입니다.
이 문제의 설명이 많아서 헷갈릴 수 있지만 핵심만 찾는다면 쉽게 해결될 문제입니다.
그럼 입출력을 살펴보도록 하겠습니다.
- Input:
- 입력값이 많아 보이지만 다 이해를 돕기 위한 것들입니다.
- 실제로는 headA와 headB가 입력입니다.
- 두 연결 리스트의 길이는 1이상 이하입니다.
- 보다 효율이 좋은 시간 복잡도로 구현해야할 것으로 보입니다.
- Output:
- 교차하는 노드를 반환합니다.
Step2. 문제 분석하기
두 연결 리스트를 탐색(순회)하면서 공통된 노드가 있는지를 판단하면 됩니다. 저는 이 문제를 보자마자 떠오른 것은 해쉬 테이블(집합) 자료구조입니다.
유무를 판별하는데는 in연산자를 사용하는데 in연산자의 시간 복잡도가 O(1)인 것은 해쉬와 집합이기 때문이죠!
또 다른 방법이 있다면, 해당 문제는 두 개의 연결 리스트가 주어집니다. 그 뜻은 두 개의 출발점에서 시작하여 만나는 점이 교차 노드란 것을 알 수 있습니다. 두 개의 지점? 바로 투 포인터를 활용하면 될 것 같습니다.
바로 코드 설계하러 가보겠습니다.
Step3. 코드 설계하기
Hash Table 방식
- 첫 번째 연결 리스트
headA를 순회하며 모든 노드를set에 추가합니다.- 이 과정에서 각 노드의 참조를 저장하므로 동일한 노드인지 빠르게 확인할 수 있습니다.
- 시간 복잡도는 이며, 공간 복잡도는 입니다.
- 두 번째 연결 리스트
headB를 순회하며 각 노드가set에 존재하는지 확인합니다.- 존재하면 해당 노드가 두 리스트의 교차 지점입니다. 존재하지 않으면 None을 반환합니다.
Two Pointer 방식
- 두 개의 포인터
a와b를 각각headA와headB로 초기화합니다. - 두 포인터를 각각의 리스트를 따라 순회합니다. 만약 포인터가 끝에 도달하면 다른 리스트의 시작으로 이동합니다.
- 두 리스트가 길이가 다르더라도, 두 포인터는 동일한 시간에 교차 지점에서 만나게 됩니다.
- 교차 지점이 없다면 둘 다
None에서 만나게 됩니다.
- 시간 복잡도는 , 공간 복잡도는 입니다.
Step4. 코드 구현
Hash Table
# Definition for singly-linked list.
class ListNode(object):
def __init__(self, x):
self.val = x
self.next = None
class Solution(object):
# # 1. Hash Table
def getIntersectionNode(self, headA, headB):
# https://leetcode.com/problems/intersection-of-two-linked-lists/submissions/1468999186
"""
:type head1, head1: ListNode
:rtype: ListNode
"""
node_set = set()
while headA:
node_set.add(headA)
headA = headA.next
while headB:
if headB in node_set:
return headB
headB = headB.next
return None- 코드 설명:
set을 활용해 첫 번째 리스트의 모든 노드를 저장.- 두 번째 리스트를 순회하며
set에 포함된 노드를 찾으면 반환.
- 시간 복잡도: O(m + n)
- 첫 번째 리스트를 순회하여 노드를 Hash Table에 저장하는 데 O(m), 두 번째 리스트를 순회하며 교차 노드를 확인하는 데 O(n).
- 공간 복잡도: O(m)
- 첫 번째 리스트의 노드를 저장하는 데 O(m) 공간이 필요.
- 결과: https://leetcode.com/problems/intersection-of-two-linked-lists/submissions/1468999186
Two Pointer
# Definition for singly-linked list.
class ListNode(object):
def __init__(self, x):
self.val = x
self.next = None
class Solution(object):
# # 2. Two Pointer
def getIntersectionNode(self, headA, headB):
# https://leetcode.com/problems/intersection-of-two-linked-lists/submissions/1468996370
"""
:type head1, head1: ListNode
:rtype: ListNode
"""
a, b = headA, headB
while a != b:
if not a:
a = headB
else:
a = a.next
if not b:
b = headA
else:
b = b.next
return a- 코드 설명:
- 두 포인터
a와b를 각각 두 리스트의 머리로 초기화. a가 끝에 도달하면headB로,b가 끝에 도달하면headA로 이동.- 두 포인터는 결국 교차 지점에서 만나거나 교차 지점이 없으면 None에서 만나게 됨.
- 두 포인터
- 시간 복잡도: O(m + n)
- 두 포인터가 각각 두 리스트를 순회하며 교차 지점을 찾음.
- 공간 복잡도: O(1)
- 추가 자료구조를 사용하지 않음.
- 결과: https://leetcode.com/problems/intersection-of-two-linked-lists/submissions/1468996370
4. 마무리
이번 문제는 링크드 리스트의 구조적 특징을 활용해 교차 노드를 찾는 문제입니다.
Hash Table 방식은 구현이 직관적이고 이해하기 쉬우며, 시간 복잡도는 효율적이지만 추가 공간이 필요합니다. 반면 Two Pointer 방식은 추가 공간 없이 O(1)의 공간 복잡도로 해결할 수 있어 더 효율적입니다.
배운 점:
- 링크드 리스트에서 중복 여부나 교차 지점을 탐색할 때 Hash Table은 매우 유용합니다.
- Two Pointer는 공간을 절약하면서 문제를 해결할 수 있는 강력한 도구입니다.
읽어주셔서 감사합니다!
매일 매일 발전합시다💪💪💪

