
데이터의 조회 성능을 향상시키는 방법은 데이터베이스의 종류에 따라 또 데이터의 규모에 따라 다양합니다. 이번 포스트로 알아볼 것은 데이터 조회 성능을 향상시킬 수 있는 가장 기본적인 index 적용에 대하여 알아보고 실제 벌크 데이터를 활용하여 성능을 비교해보겠습니다.
인덱스란?
흔히 index라는 단어는 사전이나 두꺼운 책의 맨 뒷부분에서 찾아볼 수 있습니다. 읽는이로 하여금 찾아보고싶은 키워드가 몇 페이지에 있는지 빠르게 찾아볼 수 있도록 만들어둔 별도의 페이지를 인덱스라합니다.
데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조를 일컫는다. 인덱스는 테이블 내의 1개의 컬럼, 혹은 여러 개의 컬럼을 이용하여 생성될 수 있다. 고속의 검색 동작뿐만 아니라 레코드 접근과 관련 효율적인 순서 매김 동작에 대한 기초를 제공한다. 인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작다. (왜냐하면 보통 인덱스는 키-필드만 갖고 있고, 테이블의 다른 세부 항목들은 갖고 있지 않기 때문이다.) 관계형 데이터베이스에서는 인덱스는 테이블 부분에 대한 하나의 사본이다.
위키피디아(인덱스)
대부분의 관계형 데이터베이스는 인덱스 기능을 제공합니다. Mysql, Oracle, Postgresql은 물론 이번 포스팅에서 사용할 H2 데이터베이스 역시 인덱스 기능을 지원합니다.
[Mysql]
SHOW INDEX FROM tablename; ## Table 내 인덱스 조회
ALTER TABLE tablename ADD INDEX indexname (column1, column2 ...); ## Table에 새로운 인덱스 추가성능 조회 테스트
성능 조회는 테스트를 위하여 Gym과 Member 테이블을 만들었습니다.
create table Gym (
gym_id bigint primary key, ## 8byte
name varchar(255), ## 255byte
location varchar(255), ## 255byte
address varchar(255), ## 255byte
phone_number varchar(255), ## 255byte
is_open tinyint, ## 1byte
open_time timestemp, ## 4byte
close_time timestemp ## 4byte
); ## 총 1037byte
create table Member (
member_id bigint primary key, ## 8byte
real_name varchar(255), ## 255byte
gym_name varchar(255), ## 255byte
desc varchar(512), ## 512byte
test_str1 varchar(255), ## 255byte
test_str2 varchar(255), ## 255byte
test_str3 varchar(255), ## 255byte
append_date timestemp, ## 4byte
update_date timestemp ## 4byte
); ## 총 1803 byteGym 테이블에는 15000개의 데이터가, Member 테이블에는 30000개의 데이터가 들어가있습니다.
데이터 조회를 위한 Spring 프로젝트를 생성하여 전체 조회에 소요되는 시간을 계산해보았습니다.
 |  |
|---|
(단위:ms)
특정 컬럼에 인덱스를 추가하여 where 연산으로 성능을 측정할수도 있지만, join인 연산을 활용하여 member 테이블과 gym 테이블이 조인된 30000개의 데이터를 조회하는 것으로 성능 테스트를 진행해보겠습니다.
 | 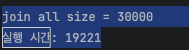 |
|---|
조인된 30000개의 데이터를 조회하는데 무려 19221ms(19sec)의 시간이 소요되었습니다. 어떤 웹 페이지에서 데이터 목록을 조회하는데 19초동안이나 응답이 없다는 것은 말도 안되는 응답 시간입니다.
인덱스 추가 후 성능 테스트
이제 join 조건이 되는 Gym 테이블의 name 컬럼에 인덱스를 추가해주겠습니다.
[H2]
create index gym_name on gym(name);
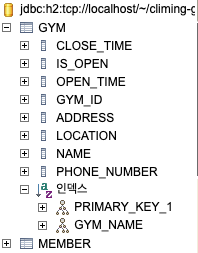
이제 앞서 테스트했던 join 연산과 동일한 로직을 실행하여 실행 시간을 비교해보겠습니다.

그 결과 연산 수행 시간이 19221ms -> 1792ms로 10배 이상의 성능 향상이 된 결과를 볼 수 있습니다.
이처럼 데이터베이스에 적절한 인덱스를 추가하는 간단한 작업만으로도 성능을 폭발적으로 향상 시킬 수 있습니다. 실제 제가 있는 회사에서는 방대한 데이터로 인하여 join 연산 수행 중에 결과값을 얻지 못하고 쿼리가 죽어버리는 경우가 있었습니다. 문제의 테이블에는 join 연산에 사용되는 컬럼에 어떠한 인덱스도 추가되어있지 않아 간단하게 인덱스만을 추가하는 작업으로 수행 시간을 평균 900ms까지 줄일 수 있었습니다.
이처럼 만약 실무에서 쿼리가 실행되는 데 과도하게 시간이 많이 걸린다면 연관된 테이블을 확인하여 인덱스를 추가하는 방안을 고려해 볼 수 있겠습니다.
다음 포스트로는 인덱스만으로는 더 이상 조회 성능의 향상을 기대하기 어려울 때 고려해 볼 수 있는 캐시 메모리의 적용을 redis적용 예제를 진행하며 알아보겠습니다.
