
가설 검정
가설 검정이란 가설을 세우고, 해당 가설이 옳은지 검증하는 일련의 과정을 의미한다.
-
가설은 연구자의 주장을 기반으로 하는 것이 특징이다.
-
모집단의 어떤 가설을 설정한 뒤, 통계 기법을 이용한 가설의 채택 여부를 확률적으로 판정하는 통계적 추론의 방법이다.
-
ex. 의회에서 주류세를 인상했을 때, 음주운전율이 줄었다.
가설의 종류
여기서 가설이란, 일반적인 '지구는 둥글다'와 같은 것이 아닌, 통계를 위한 모집단의 모수(ex. 평균 ,분산)에 대한 잠재적인 주장이다. 따라서 통계적 가설은 아래와 같은 일정한 형식을 지닌다.
- 귀무 가설
- 비교하는 값과 차이가 없다는 것을 전제
- 기존 이론 가설
- : Null Hypothesis
- 대립 가설
- 비교하는 값과 차이가 있다는 것을 전제
- 연구자 목적, 주장
- : Alternative Hypothesis
가설 검정의 통계적 오류
가설 검정 시, 4가지의 경우의 수를 생각해 볼 수 있다.
실제 진실과 추론에 기반한 가설 채택의 예를 아래와 같이 표현했다.
| 진실 | 통계적 가설 검정 결과 | 최종 결과 |
|---|---|---|
| 피고인 = 범죄자 | 귀무가설 : 무죄 (채택) | 제2종 오류 |
| 피고인 = 범죄자 | 대립가설 : 유죄 (채택) | 옳은 결정 |
| 피고인 = 시민 | 귀무가설 : 무죄 (채택) | 옳은 결정 |
| 피고인 = 시민 | 대립가설 : 유죄 (채택) | 제1종 오류 |
위의 예를 살펴보면, 통계적 가설 검정 시 2가지 오류가 존재함을 확인할 수 있다.
-
제 1 종 오류() : 대립가설을 채택해 발생하는 오류
(유의 수준이라고도 함)- 가 참이지만, 으로 잘못 선택
-
제 2 종 오류() : 귀무가설을 채택해 발생하는 오류
- 가 참이지만, 으로 잘못 선택
| 귀무가설 : 진실 | 대립가설 : 진실 | |
|---|---|---|
| 귀무가설 선택 | 옳은 결정 (신뢰 수준 : 1- ) | 제2종 오류 () |
| 대립가설 선택 | 제1종 오류 (유의 수준 : ) | 옳은 결정 (검정력 : 1 - ) |
가설 검정 방법
모집단에 설정한 가설에 대해 표본관찰을 통해 해당 가설을 채택할지의 여부를 결정하는 가설을 검정하는 방법을 알아본다.
-
검정 통계량을 구할 때 확률 분포와 추정에 대해 상세하게 안다면, 많은 도움이 된다.
-
그러나, 지금은 모든 통계적인 과정이 충족되었다는 가정 하에 진행
가설 검정은 목적에 따라 아래의 2가지로 진행할 수 있다.
-
양측 검정
- 검정 통계량의 분포에서 기각영역이 양쪽에 나타나는 형태의 가설검정
- 귀무가설 :
(A는 B이다) - 대립가설 :
(A는 B가 아니다. - B는 A보다 클수도 있고 작을 수도 있다. [기각 영역이 양측]) - 가능성이 열려 있음
-
단측 검정
- 검정 통계량의 분포에서 기각영역이 한쪽에 나타나는 형태의 가설검정
- 귀무가설 :
(A는 B이다) - 대립가설 :
(A는 B가 아니다. - B는 A보다 크거나, 작다 [기각 영역이 한쪽]) - 연구자가 확고하게 목적을 가질 경우, 명확한 방향성을 지니고 단측 검정을 사용
가설 기반 의사 결정 방법
가설은 검정 통계량과 유의 확률을 토대로 가설 채택 여부를 결정한다.
검정 통계량
검정 통계량
귀무가설과 대립가설을 채택하기 위한 근거로 사용되는 통계량
귀무 가설이 참이라는 가정 하에 계산한다.
-
검정 통계량 값이 나타날 가능성이 크면, 귀무가설을 채택하고, 아니면 기각한다. (검정 통계량에 대해 채택, 기각 여부는 기각역을 세워 판단한다.)
- 검정 통계량 > 기각역 → 귀무가설 기각
- 검정 통계량 < 기각역 → 귀무가설 채택
기각역
기각역은 귀무가설을 기각하게 되는 검정 통계량의 관측값의 영역 -
귀무 가설이 옳다는 전제 하에, 검정 통계량이 기각역에 속할 확률이 유의수준인 검정 통계량 분포의 일부 영역이다.
-
구하고자하는 주제와 데이터에 따라 어떤 검정 통계량을 사용할지는 달라진다.
유의 확률
위의 검정 통계량이 아닌 유의 확률을 통해서도 귀무 가설의 채택, 기각 여부를 결정할 수 있다.
유의 확률
유의 확률은 검정 통계량의 확률이다.
유의 확률의 해석은 귀무가설 하에서 검정통계량의 값이 나타날 가능성을 측정한 확률 값을 의미한다.
- 유의 확률 < 유의 수준 → 귀무 가설 기각
- 유의 확률 > 유의 수준 → 귀무 가설 채택
유의 수준 ()
유의 수준은 위에서 언급했듯 제1종 오류의 최대 허용 한계가 된다.
- ex. 유의 수준이 5% 이고, 유의 확률이 11%이면, 귀무 가설을 채택한다.
연구 목적에 따른 가설 검정 예제
| 연구 목적 | 변수 유형 | 통계 분석 기법 | 가설 수립 |
|---|---|---|---|
| 인테리어 종류(고전, 현대)에 따라 고객 만족도에 차이가 있는가? | X : 인테리어 종류 Y : 고객 만족도 | 독립 표본 t 검정 | 귀무 가설 : 인테리어 종류에 따라 고객 만족도에 차이 없음 대립 가설 : 인테리어 종류에 따라 고객 만족도에 차이 있음 |
| 인터넷 상품(A, B, C)에 따라 고객 만족도 차이가 있는가? | X : 인터넷 상품 Y : 고객 만족도 | ANOVA | 귀무 가설 : 인터넷 상품에 따라 고객 만족도 차이 없음 대립 가설 : 인터넷 상품에 따라 고객 만족도 차이 있음 |
| 연령대에 따른 채널별 마케팅 효과에 차이가 있는가? | X : 연령대 Y : 채널 | 카이제곱 | 귀무 가설 : 연령대에 따른 채널별 마케팅 효과에 차이 없음 대립 가설 : 연령대에 따른 채널별 마케팅 효과에 차이 있음 |
| 자동차의 중량과 연료 소비량 간의 상관관계가 있는가? | X : 자동차 중량 Y : 연료소비량 | 상관분석 | 귀무 가설 : 자동차의 중량과 연료 소비량 간의 상관관계 없음 대립 가설 : 자동차의 중량과 연료 소비량 간의 상관관계 있음 |
-
"인터넷 상품(A, B, C)에 따라 고객 만족도 차이가 있는가?" 의 경우 위의 인테리어 종류와 유사하여, 독립 표본 t 검정을 사용해도 될 것으로 보인다.
- 독립 표본 t 검정은 2개의 그룹에 대해서 비교, ANOVA는 3개 이상에 대해 비교 가능
- 물론, 독립 표본 t 검정을 잘 이해하고 쓴다면, 사용 가능한 부분이 있음 [단, 복잡해짐 {A,B},{B,C},{C,A}]
- 3개 이상의 t 검정은 과잉 검증 문제를 유발 할 수 있다.
과잉 검증 문제 (Over testing problem)
통계적 검증 절차를 남용하여, 확률적 의사 결정에서 발생할 수 있는 오류의 확률을 필요 이상으로 증기사키는 문제 -
"연령대에 따른 채널별 마케팅 효과에 차이가 있는가?" 는 연령대, 채널이 모두 범주형 데이터인 특징을 가짐
- 범주형 데이터 간 비교는 카이제곱 사용
-
"자동차의 중량과 연료 소비량 간의 상관관계가 있는가?" 는 연속형-연속형 데이터의 비교로 상관 분석 사용
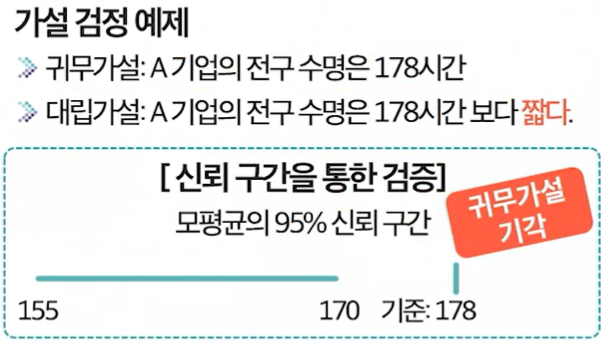
단일 표본 t 검정
가설 검정을 위해서는 독립 변수와 종속 변수의 알맞은 통계 방법을 선택해야 하는데, 여기서는 그 방법 중 하나를 살펴본다.
단일 표본 t 검정은 가장 기본적이면서 직관적인 가설 검정 방법 중 하나로, 한 모집단의 평균값과 기준값의 차이를 비교하는 분석법이다.
- 모집단에서 표본을 추출하고, 표본 평균을 구해, 표본 평균을 바탕으로 모평균을 추론해, 기준이 되는 실제 평균값과의 비교
 -
-
독립 표본 t 검정
앞서서 본 단일 표본에 대한 t 검정이었다면, 독립 표본 t 검정은 그룹 간의 평균을 비교하는 t 검정이다.
- 독립된 두 집단의 표본 간 평균의 차이에 대한 가설을 검정하는 t 검정법
- 평균 간의 차이가 통계적으로 유의미한지를 판단
- 이 외에도 다양한 방법이 존재
(독립되지 않은 한 집단 내(동일 그룹)에서 약효를 검증하는 경우, 대응표본 t 검정 방식 사용)
ex.
[가설 검정]
- 귀무가설 : 성별에 따라 몸무게의 차이가 없다.
- 대립가설 : 성별에 따라 몸무게의 차이가 있다.
[기본 가정]
- 독립성 : 독립변수의 그룹군은 서로 독립
- 정규성 : 집단별 종속변수는 정규분포를 만족
- 등분산성 : 집단별 종속 변수 분포의 분산은 각 군마다 동일
가설 검정 순서
- 가설 수립 : 주장에 대한 가설 수립
- 판단 기준 수립 : 유의수준() 결정
- 통계 기법 산출 : 데이터에 따라 독립 변수 t 검정, ANOVA 등 결정
- 분석 통계량 산출 : 검정 통계량 산출
- 판단 기준 : P-value라는 검정 통계량의 확률을 통해 판단
- 결과 검출
실습 링크
참고 문헌
