
다변량 비시각화 탐색
다변량 비시각화 탐색은 2개 이상의 변수로 구성된 데이터의 관계를 교차표 및 상관계수 등으로 파악하는 데이터 탐색 유형이다.
-
일변량 데이터 탐색은 하나의 데이터 유형을 탐색하므로, 개별 데이터를 파악하는 것에 목적을 두었다. 그러나, 다변량 데이터 탐색은 개별 속성을 기반으로 변수 간의 관계를 수치 및 통계적 지표 기반으로 파악하는 것이 그 목적이다.
-
따라서, 일변량 분석과는 달리, 데이터 분석 단계에서 가장 많은 수고와 고려가 이루어져 분석 및 설계되는 단계이다.
-
변수 간의 관계 파악을 통해서, 변수를 선택하거나, 그룹핑하거나, 파생 변수를 생성하는 등의 고려 및 방안이 많이 존재한다.
다변량 비시각화의 종류
| 데이터 조합 | 비시각화 방안 | 목적 |
|---|---|---|
| 범주형 - 범주형 | 교차표 | 두 개 범주형 변수의 범주별 연관성 및 구성 파악 |
| 범주형 - 연속형 | 범주 별 통계량 | 범주 별 대표 통계량 비교 파악 |
| 연속형 - 연속형 | 상관계수 | 두 개 연속형 변수의 관계성 정도 파악 |
-
교차표 : 데이터가 범주별 조합에 따라 어느정도의 빈도로 구성되어 있고, 어느 특정 조합이 비교적 우위로 나타나는지 파악
- ex. 특정 범주 별 조합이 타깃인 변수와 관계가 깊고 얕음을 빈도 구성을 통해 파악 가능
-
범주 별 통계량 : 특정 기법이라기 보다는, 데이터별 특정 대표값을 파악하여 범주 별로 차이를 보기 위해 많이 사용되는 방안
-
상관계수 : 특정 변수 간 상관계수가 도출되고, 상관계수의 값이 높고, 낮음을 통해서 변수 간의 관계성이 큰지, 작은지 판단
교차표
범주형 - 범주형 변수 조합 간 연관관계 파악
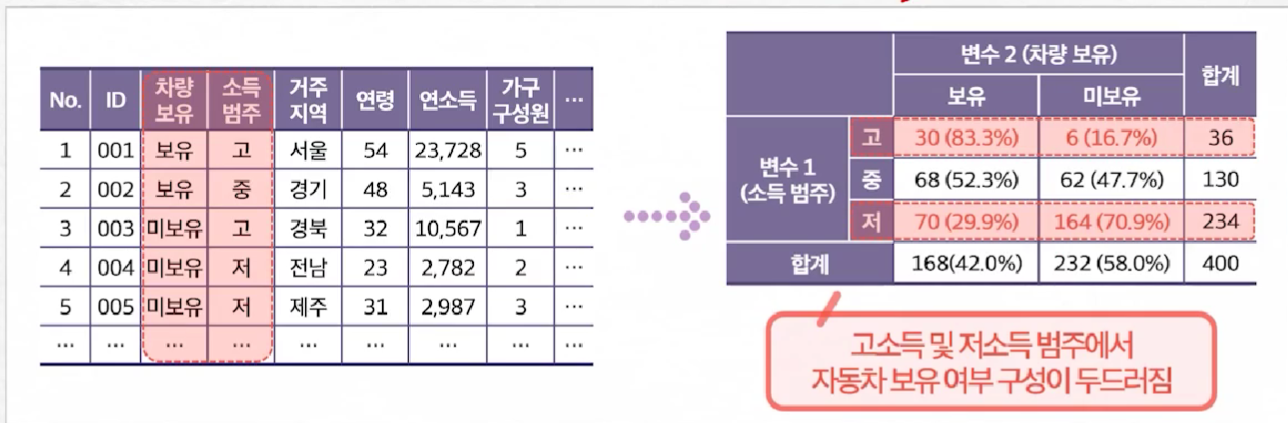
위의 그림처럼 서로 다른 범주를 묶어 교차표를 그려, 각 변수의 범주마다의 비교를 통해 새로운 인사이트를 구할 수 있음
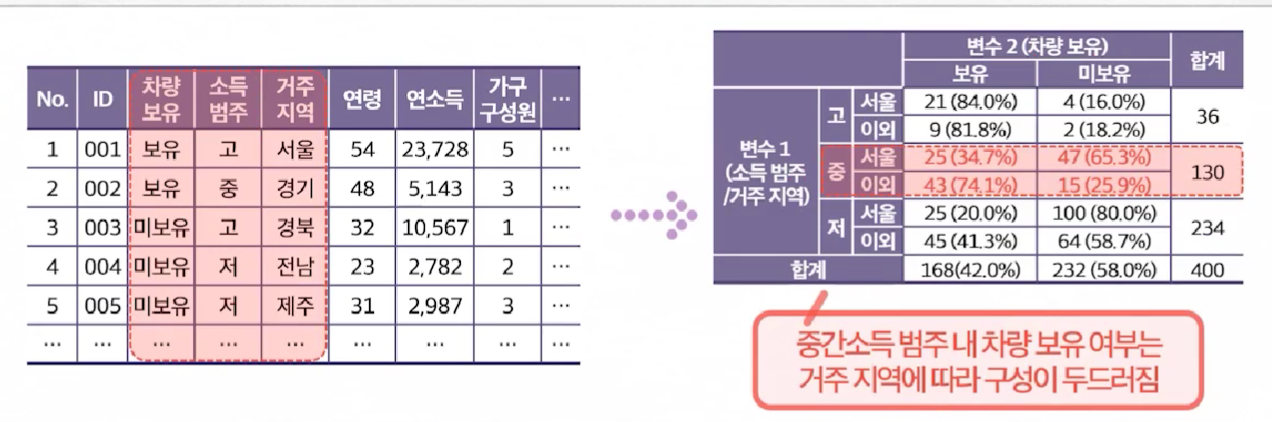
위의 그림 처럼 3개 이상의 범주형 특성을 이용하여 보다 세밀하게, 범주 간의 관계를 파악할 수 있음.
범주 별 요약 통계량
범주형 - 연속형 변수 조합 간 범주 별 대표 수치 비교
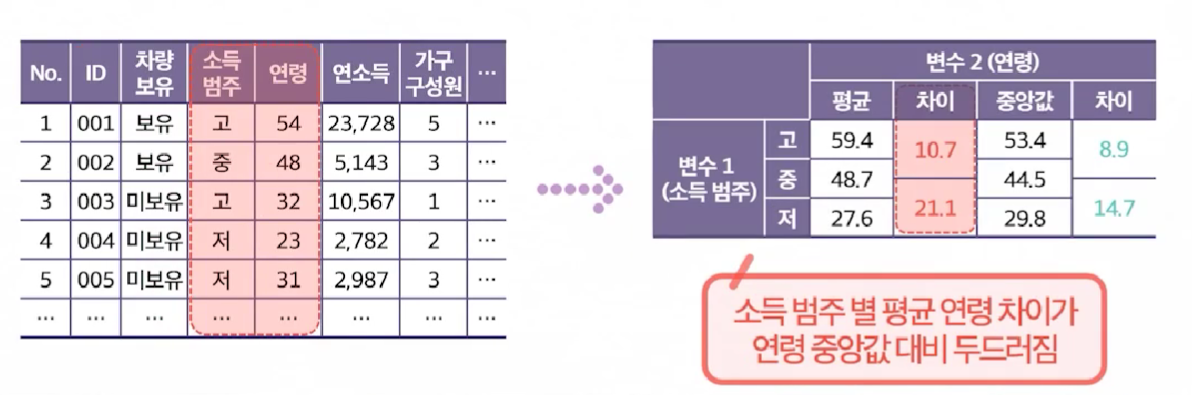
-
이는 특정 기법이라기 보다는 데이터별, 범주별 특정 대표값을 찾아내고, 범주별 차이를 찾기 위해 많이 사용되는 방안이다.
-
각 범주 별 특정 기술통계량을 기반으로 범주들의 특징을 통계 지표로 확인하고 파악한다.
-
일종의 집계 분석 기반이므로, 데이터의 성격을 간단하게 파악하기 위한 방안으로 활용 가능하다.
-
혹은 집계 분석을 이용하여 범주별 요약 데이터를 만들고, 모델링을 위한 데이터 생성 방안으로 활용할 수 있다.
위와 같은 방법은 데이터를 설명하기 위한 리포팅 자료나 보고서에서도 많이 사용됨.
상관계수
연속형-연속형 변수 간의 관계성 강도 파악
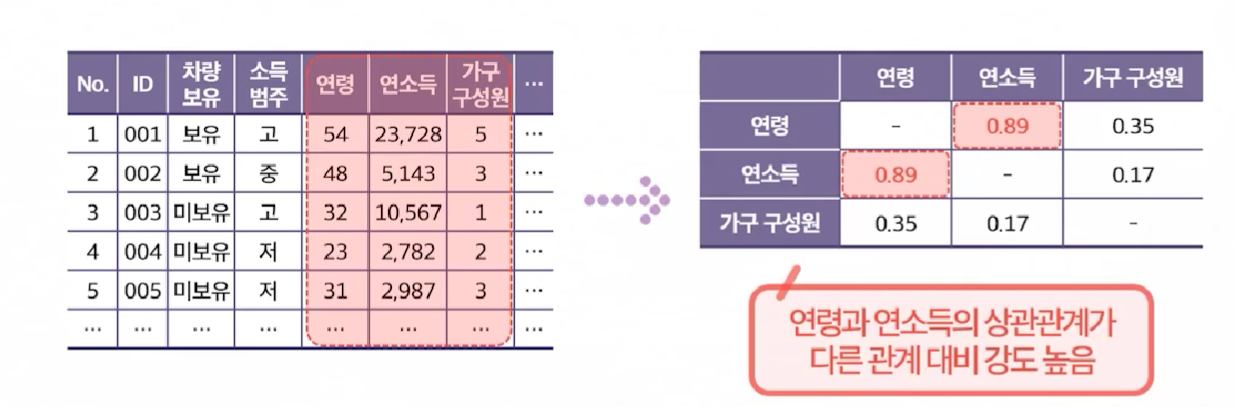
-
연속형 변수들 간의 어떤 관계를 가지고 있는지 파악하기 위한 방법으로, 두 변수가 서로 독립적이거나, 상반된 관계일 수 도 있으며, 이러한 관계를 상관관계로 지칭한다.
-
상관계수는 두 변수 간의 연관된 정도를 나타낼 뿐으로, 원인과 결과를 확인하는 것은 아니다.
-
두 변수 간의 인과관계는 회귀 분석을 통해서 인과관계의 방향, 정도 등을 확인할 수 있다.
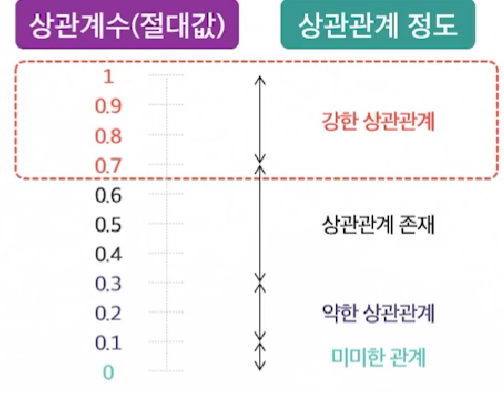
절대값으로 표현했으나, 상관계수는 -1 ~ 1의 값으로 표현하게 된다.
- 1은 완벽한 양의 선형 상관관계를 나타내며,
- -1은 음의 상관관계를 의미
- 0은 상관관계가 없음
높은 상관계수
비슷한 정보를 제공하는 밀접한 관계의 변수 (강한 상관관계를 가진 변수)
-
회귀 분석에서 독립 변수 간에 강한 상관관계 발생 시,
- 다중 공선성 발생
다중 공선성
독립 변수들간의 강한 상관관계를 나타냄.
독립 변수의 일부가 다른 독립 변수의 조합으로 표현될 수 있는 경우처럼 독립 변수들이 서로 독립이 아니라, 상호간의 강한 관계를 보일 때 발생
이는 분석에 사용되는 변수의 정의에 어긋나게 되는 점이 있다. (회귀 분석 시, 변수가 서로 의존하는 관계를 가지면, Overfitting 등의 문제가 발생 - 결과의 안정성을 해침)
- 다중 공선성 발생
-
독립 변수 간의 관계는 독립적이라는 회귀분석 가정 위배
-
회귀 계수가 불안정하여 종속 변수에 미치는 영향력을 올바르게 설명치 못하므로 모델의 안정성 저해
따라서, 높은 상관관계를 가지는 경우, 데이터의 의존성으로 인해 모델링에 문제를 야기하므로, 미리 데이터 분석 과정에서 이에 대한 사전 고려가 필요하다.
- 만약, 타깃 변수를 예측하는 것이 유일한 목표이고, 독립 변수의 영향력에 대해서 파악할 필요가 없다면, 상관없이 그냥 사용해도 된다 라는 연구 결과도 일부 존재하기는 함. (다만, 현업에서는 결과와 해석 모두 중요할 수 있으므로 해당 부분은 고려가 필요)
다중 공선성을 해결하기 위한 몇가지 방안이 존재한다.
-
실제 데이터는 시간에 따라 어느정도 변화하기 때문에, 완벽하게 다중 공선성을 제거하고, 100% 독립 변수만 남기는 것은 불가능하다.
- 따라서, 상관계수가 기준치보다 높게 나오는 컬럼 중에서 하나를 고르고, 나머지는 삭제하는 방안을 통해 변수 선택을 고려할 수 있다.
-
분석의 목표를 고려하여 좀더 적합한 컬럼을 선택하거나, 종속 변수와 상관관계가 더 밀접한 관계를 가지고 있는 변수를 선택한다.
-
도메인 지식을 바탕으로 의존적으로 변수를 삭제하거나,
-
상관성이 높은 변수들을 PCA 등의 방법으로 변수를 통합하여 새로운 특징을 생성하거나,
-
변수의 간격을 정규화 등으로 조절하여 해결하는 등의 방안이 존재
위와 같이 서로 다른 변수들을 조합해보며, 데이터의 특성 및 상관관계를 찾아나가는 과정이 다변량 탐색 과정이며, 이러한 과정을 통해 새로운 규칙 기반의 파생 변수 생성, 변수 선택 및 구성에 대한 근거를 마련할 수 있다.
실습 코드
