
특성 선택 (Feature Selection)
특성 선택이란, 주어진 원본 데이터에서 가장 좋은 성능을 보여줄 수 있는 데이터의 부분 집합(subset)을 찾아내는 방법이다.
모델 생성에 가장 효과적이고, 밀접한 데이터의 부분집합을 선택하여, 고차원 데이터를 저차원으로 변환하여 연산 효율성 및 모델 성능을 확보한다.
이전의 특성 생성과 마찬가지로 특성 공학(Feature Engeering)의 주요 주제이며, 현업에서도 많이 활용되는 기법이다.
목적 및 필요성
앞선 특성 생성과 다른 점은 특성을 추가적으로 만들어내는 것이 아닌, 기존의 특성에서 효과적인 특성을 골라낸다는 것에 초점을 맞춘다는 점이다.
다만, 그 목적은 모델의 성능 향상 및 연산 효율성 확보라는 동일한 목적을 갖는다.
- 연산 효울성
- 특성 생성과는 다르게 원 데이터 공간 내 유의미한 특성을 선택
- 원본 데이터에서 가장 유용한 특성만을 선택하여, 간단한 모델 구성 및 성능 확보를 목적으로 한다.
특성 선택 방안
특성을 선택하기 위한 방법에는 3가지가 존재한다.
-
필터 (Filter)
-
특성들에 대한 통계적 점수를 부여하여, 순위를 매겨 선택
-
통계적 집계 및 비교 방식을 활용하므로, 실행 속도가 빨라 시간 및 비용 측면의 강점을 가짐.
-
사전 도메인 지식 기반으로 잘 알려진 특성에 대해 실검증
-
도메인 기반으로 잘 알려진 유의미한 데이터의 활용 여부도 결정하는데 사용
-
-
래퍼 (Wrapper)
-
특성의 모든 조합을 지도학습 알고리즘에 반복적으로 적용하여 특성을 선택
-
원본 데이터내에서 모든 특성 조합을 구하고, 최적의 데이터 조합을 찾아, 성능 향상에 유용. 단, 시간 및 비용 소모가 크다.
-
-
임베디드 (embedded)
-
모델 내 변수 선택 함수를 활용하는 방안
(모델 자체의 변수를 선택할 수 있는 알고리즘이 적용된다.) -
모델 정확도에 기여하는 특성들을 선택, 해당 조합의 결과로 도출 (Filter와 Wrapper 장점 결합)
-
모델의 학습 및 생성 과정에서 최적의 특성을 선택하는 방법
-
필터 (Filter)
통계적 기법을 적용하여 구한 점수를 기반으로 특징들을 선택하는 방안으로, 전체 데이터 집합에서 변수별 유의미한 관계를 보이는 특성들을 판단 및 선택한다.
변수별 통계적 유의미성을 통계적으로 검증하고, 특성으로 도출하므로 연산속도가 매우 빠르고, 래퍼(Wrapper)를 적용하기 전, 선적용하기도 한다.
필터 방식에는 2가지 방안이 존재한다.
- 카이제곱 필터 (chi-square filter)
- 범주형인 독립 및 종속 변수 간의 유의미성을 도출하기 위한 통계적 방안
- 연속형 변수를 이산화(범주)를 하여 활용 가능
- 상관관계 필터 (Correlation filter)
- 연속형인 독립 및 종속 변수 간의 유의미성을 도출하기 위한 통계적 방안
- 보통 임계치(threshold)를 설정하여 변수 선택
일반적으로, 두 방식을 통해 구해진 유의미성이 낮은 특성은 분류 및 분석 과정에 큰 도움이 안된다고 가정하고 제외할 수 있으나, 단순히 유의미성(특성 간의 통계적 관계)이 높은 특성이라고 해서 해당 특성이 모델에 적합한지는 알 수 없음.
따라서, 전처리 과정에서 주로 사용하는 방안이며, 통계 기법을 사용해 상관관계 및 관계가 높은 데이터를 우선 추출 시 사용한다.
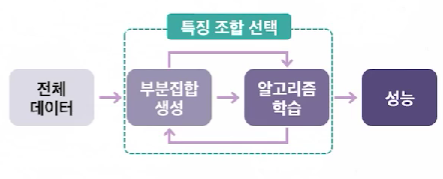
래퍼 (Wrapper)
성능 관점에서 유용한 방안이며, 원본 데이터 내 변수 조합을 탐색하여 최적의 특성 조합을 선택하는 방안이다.
반복적 특성 조합 탐색 방식을 이용한다.
Wrapper 방식의 특성은 다음과 같다.
-
원본 데이터 셋 내의 변수들의 다양한 조합을 모델에 적용
-
최적의 부분 데이터집합을 도출하는 방법론
-
대표적 방식으로 재귀적 특성 제거(Recursive Feature Elimination) 존재
-
기존 데이터에서 테스트를 진행 할 테스트 셋(holdout set)을 별도로 두어야 한다.
-
반복적으로 특징 조합을 도출하고, 적용하여 성능 파악을 하는 과정이 발생하므로, 시간 및 비용이 매우 많이 발생하나, 최종적으로 Best feature subset을 찾으므로, 모델 성능 면에서는 바람직하다.
-
Wrapper를 적용하는 모델의 파라미터나 알고리즘의 완성도가 높아야 제대로된 부분 집합을 찾아낼 수 있는 측면도 존재한다.
Wrapper 방식에는
- 변수가 없는 상태에서 1개씩 추가해 나가는 방법과
- 전체에서 중요하지 않은 변수를 1개씩 제거해 나가는 - 재귀적 특성 제거(RFE)
방법이 있다.
임베디드 (embedded)
모델을 학습하여, 정확도에 기여하는 특성을 선택하는 방안으로, 모델 자체에 변수 선택이 포함된 알고리즘을 활용하여, 모델의 정확도에 기여하는 특성을 선택하고, 학습하여 모델 성능을 향상하는 방식이다.
임베디드 방식의 특징은 다음과 같다.
-
알고리즘 내 자체 내장 함수로 특성을 선택하는 방식으로, 모델 성능에 기여하는 특성을 선택한다.
-
모든 조합을 고려하고, 결과를 도출하는 Wrapper 방식과 달리 학습과정에서 최적화된 변수를 선택한다. (Wrapper과 Filter의 장점만 조합)
-
트리 계열 모델 기반의 특성 선택이 대표적이다. (랜덤 포레스트 기반 Feature Importance 기반)
-
모델 학습 동안, 모델 기여도가 높은 특성을 선택하는 방식으로, 학습 중에 가중치 및 중요도를 평가할 수 있는 모델을 선택해야 한다.
-
Wrapper 처럼 모델 자체의 파리미터, 알고리즘의 완성도가 높아야 한다.
특성 선택 알고리즘
랜덤 포레스트 기반의 알고리즘을 소개한다.
-
보루타 알고리즘 (Boruta Algorithm)
-
Boruta Algorithm은 기존의 데이터를 임의로 복제하여, 랜덤 변수(shadow)를 생성하고, 원 자료와 결합하여 랜덤 포레스트 모형에 적용
-
shadow 보다 중요도가 낮은 경우, 중요하지 않은 변수로 판단 후 제거
-
➡️ 즉, 보루다 알고리즘은 기존의 데이터를 임의로 복원 추출해서 만든 랜덤 변수 (shadow)보다 모델 생성에 영향을 주지 못했다면, 가치가 크지 않은 특성을 판단하고 제거하는 형태이다.
제거되지 않은 특성들의 조합을 선택한다...
랜덤 변수 (Shadow)
원본 데이터를 복제하고, 임의의 값을 섞어 만들어진 임의의 변수.
이러한 무작위성을 통해 생성된 변수는 기존의 특성과의 중요도를 비교하기 위한 참조값으로 사용한다.
실습 코드
