
인과 관계 규명에 특화된 회귀 분석의 종류와 특징에 대해 알아본다.
회귀 분석을 위한 기본 지식
회귀 분석 기본 가정
회귀 분석은 인과관계의 규명할 수 있는 분석, 예측 통계하는 방법이므로, 그만큼 강력한 가정이 필요하다.
- 선형성 : 독립변수(X)와 종속변수(Y)는 선형 관계이다. (두 변수가 선형 관계임을 보장하기 위한 가정)
- 독립성 : 종속변수 Y는 서로 독립이어야 한다. (한 관측값이 다른 관측치에 의해 영향을 받으면 안됨.)
- 등분산성 : 독립변수 X의 값에 상관없이 종속변수 Y의 값이 일정하다.
- 정규성 : 독립변수 X의 고정된 어떤 값에 대하여 종속 변수 Y는 정규분포를 따른다.
위 가정을 만족하지 못하면 회귀 분석으로 도출된 결과를 일반화하기 어렵다. (인과 관계 규명 X)
물론, 회귀 분석의 종류는 여러가지가 있으므로, 위의 가정에서 변형된 가정을 가지기도 한다. (특정 경우, 가정이 더 강화되고, 특정 경우는 더 완화될 수 있음)
-
회귀 분석의 모형
-
추정 회귀 식
최소제곱법
회귀 분석에서 중요한 이론 중 하나이다. 따라서 간단히 살펴본다.
- 최소제곱법 외에도 절댓값의 합을 구하는 등 여러가지 방법이 존재, 일반적으로는 수학적으로 편리한 최소제곱법 사용.
X와 Y의 값에 대해 아래의 식을 통해 산점도로 표현
산점도를 통해 잔차에 대한 정보를 얻을 수 있음.
잔차()
잔차란 실제 값과 추정된 값의 차이를 의미한다. 수식으로 표현하면 다음과 같다.
각 지점마다의 잔차에 대한 정보를 제곱하여 합한 값을 최소화하는 것이 최소제곱법(OLS)이다. (물론, 수학적으로 좀 더 깊게 최소값을 구할 수 있음)
- → (잔차를 최소화하는 회귀 계수 추정)
최소제곱법을 통해, 모델의 설명력을 높인다.
결정계수
잔차를 최소화하면 모델의 설명력을 높일 수 있다. 그러한 모델의 설명력을 정량적으로 설명한 것이 결정계수($R^2)이다.
-
총 변동을 회귀 분석이 얼마나 설명할 수 있는지를 0 ~ 1사이의 값으로 정량화하여 표시한 계수이다. (총 변동을 설명함에 있어 회귀선에 대하여 설명되는 변동 기여 비율)
-
( : 회귀 제곱 합, : 전체 제곱합)
- 해당 식을 통해 회귀 제곱이 전체 제곱에서 얼만큼의 비율을 차지하는지 알 수 있음
t 검정
단순 회귀 계수를 검정할 때, 개별 회귀 계수의 통계적 유의성을 t검정을 통해 확인 가능.
ex.
회귀 분석 가정이 만족한다고 할 때, 회귀분석 모델 이 있다고 한다면, 가 변화할 때 마다, 변화되는 의 변화가 통계적으로 유의 한지 검정할 필요가 있다.
이 때, 귀무 가설과 대립 가설을 세우고, 해당 식이 통계적 유의성이 있는지 확인한다.
위의 예시에서의 귀무 가설과 대립 가설은 다음과 같다.
-
귀무 가설() : (추정 값과 실제 값이 같음.)
-
대립 가설() : (추정 값과 실제 값이 다름.)
-
검정 통계량 :
- 여기서 는
[결과해석]
결과는 구해진 P-value(유의 확률)와 결정한 유의 수준에 의해 결정한다.
-
p-value가 유의수준()보다 낮으면, 통계적 의미를 가짐.
- 여기서는 대립 가설을 채택하는 경우가 통계적 의미를 가진다.
-
기각
-
채택
단순 회귀 분석
한 개의 종속 변수(Y)와 한 개의 독립 변수(X) 사이의 관계를 분석하는 통계 기법
Y와 X의 관계를 일차식(선형)에 대입하여, X의 변화가 Y에 어떻게 영향을 미치는지를 예측할 때 사용한다.
다중 회귀 분석
다중 회귀 분석은 독립변수가 2개 이상인 경우에 대한 회귀 분석을 의미한다.
따라서 모델의 수식도 다음과 같이 여러 독립 변수를 가지게 된다.
-
단순 회귀 분석과의 차이점 : 단일 개의 독립변수가 아닌 여러 개의 독립변수 사용
-
다중 공선성
- 다중선형회귀분석 : 각 독립변수 간의 독립성 가정
다중 공선성 : 독립변수 간의 상관성 존재를 의미 → 독립성 X
- 여러개의 독립 변수가 존재할 때, 종속변수의 영향을 주는 독립변수를 찾는 것이 중요하며, 최적의 변수 선택의 필요
쉽게 설명하면, 여러개의 독립 변수가 존재하면, 독립변수간 상관성이 나타나게 되고, 그중 독립변수간의 상관성이 높으면서, 종속변수에도 지대한 영향을 주는 변수들에 대해서는 일부는 배제하는 등의 최적의 성능을 구하기 위한 변수 선택이 필요하다는 것을 의미한다.
- 다중 공선성 이슈를 해결하기 위해 VIF 같은 방식으로 해당 이슈 해결을 위한 아이디어를 얻을 수 있다.
이차 회귀 모델
이차 회귀 모델은 데이터 변환으로 선형성을 확보하기 어렵거나, 데이터가 비선형성을 가진다고 한다면 이차 회귀 모델과 같은 비선형성에 맞는 모델을 만들어 적용해야 한다.
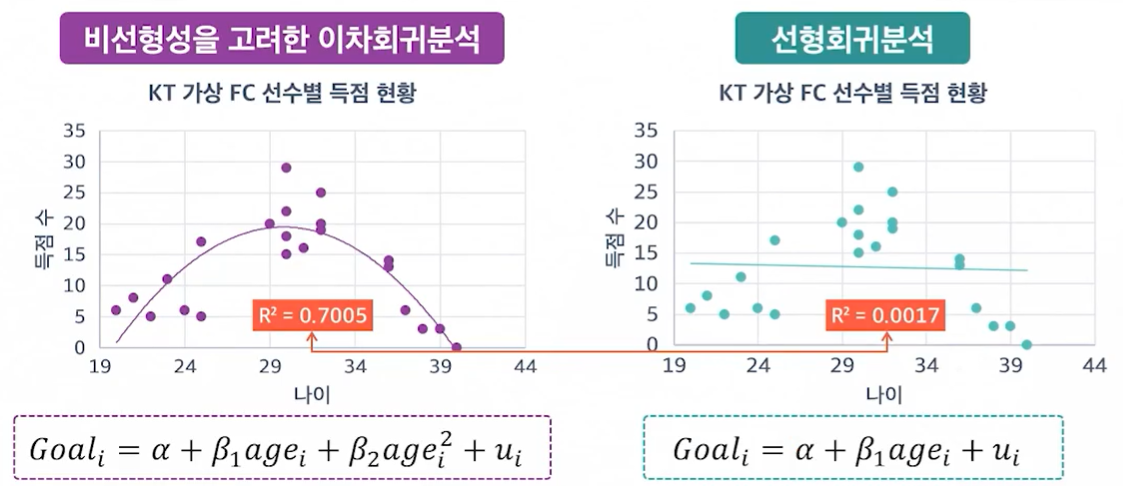
데이터 자체가 위의 그림처럼 선형으로 표현하기 어려운 경우에는 이차 항등을 고려하여, 비선형적인 모델을 생성하면, 데이터를 더 많이 반영함을 확인할 수 있다.
실제 현실에서는 데이터의 비선형성을 보이는 경우가 많으므로, 비선형 분석을 하는 경우도 많이 발생한다. 따라서, 비선형 회귀 모델의 고려가 필요하다.
다항 회귀 모델
이차 이상의 비선형 데이터를 고려하기 위한 다차항 회귀 모델을 의미한다.
- 2차 이상 3차, 4차, , n차 회귀 모형을 의미한다.
- 변수간 상호 작용이 가능하다는 특징을 가진다.
- 비선형적 추세를 고려할 수 있다.
- 데이터에 따라 log 및 차분을 통해 선형화하여 계산할 수 있다.
기본적으로 데이터를 선형화하여 보다 쉽게 계산하는 것이 좋으므로, 선형화가 가능하면, 선형화하는 것이 좋다.
실습 코드
