1. 데이터의 산포
현실 세계에서 관측되는 모든 데이터는 산포성(=데이터가 퍼져있는 성질)을 가지고 있다. 대표적인 예로 사람의 키와 몸무게는 유전적 요인, 후천적 환경 등에 영향을 받고 같은 환경에 있더라도 모두 키와 몸무게는 달라진다. 이러한 성질을 산포성이라 한다.
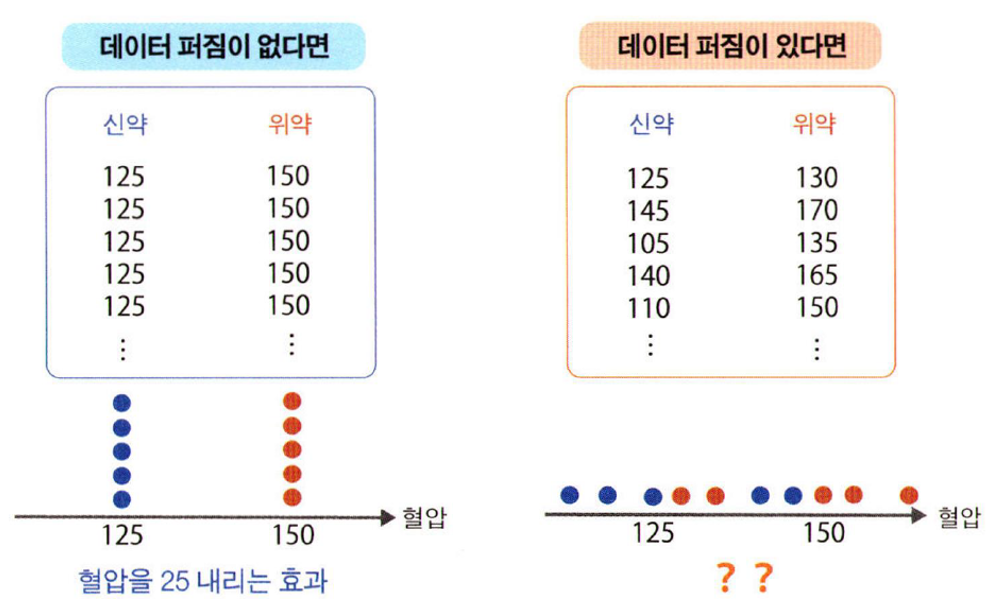
데이터의 산포성은 데이터의 성질이나 관계성을 파악하는 데에 어려움이 된다. 통계학에서는 이런 데이터의 산포성을 불확실성이라고 판단한다. 아래 사진은 데이터의 산포성 때문에 정확한 예측 및 분석이 어려운 사례이다.
데이터의 산포성이 없었다면, 모든 사람들의 혈압은 150일 것이고, 혈압약을 먹은 후에는 125로 동일하게 떨어질 것이다. 그런데 현실 데이터는 산포성이 있기 때문에 모든 사람들의 혈압도, 복용 결과도 달라진다.
2. 통계에서 확률을 사용하는 이유
데이터가 퍼져서 분포하는 산포성 때문에 완벽한 해석과 예측이 불가능하다. 따라서 통계에서는 확률을 사용한다. 확률로써 예측이나 사건의 발생할 가능성을 계산한다.
