정밀도와 재현율
정밀도(Precision)와 재현율(Recall)은 Positive 레이블에 대한 성능에 중점을 둔 성능 측정 방법이다. 정밀도와 재현율을 구하는 방법과 각각의 의미는 아래와 같다.
< 정밀도 >
→ 모델이 Positive로 예측한 것들 중에(=FP+TP) 실제 Positive인(=TP) 비율
< 재현율 >
→ 실제 Positive인 것들(=TP + FN) 중 모델이 Positive로 예측한(=TP) 비율
각각의 지표가 중요한 경우는 아래와 같다.
- 정밀도가 중요한 업무는 실제 Nagative인 값을 Positive로 판단하면 큰 이슈가 되는 업무
ex) 어린이 요금 대상을 예측하는 모델 → 어른 고객을(N) 어린이 고객(P)으로 판단하는 경우 회사에 손실이 생김 - 재현율이 중요한 업무는 실제 Positive인 값을 Nagative로 판단하면 큰 이슈가 되는 업무
ex) 암환자 예측 모델 → 암환자를(P) 정상환자로(N) 판단하는 경우 생명이 위험할 수 있음 / 반대의 경우 검사를 한 번 더 하면 되므로 상대적으로 영향이 적음
파이썬으로 정밀도와 재현율 계산하기
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
# 정밀도 계산
precision = precision_score(y_test, predicted)
# 재현율 계산
recall = recall(y_test, predicted)trade-off 관계
정밀도나 재현율이 강조되어야 하는 경우 임계값을 조정하여 각각의 수치를 높일 수 있다. 하지만 정밀도와 재현율은 trade-off 관계에 있기 때문에 한 지표를 높이면 다른 지표는 떨어지게 된다.
📌 < 왜 정밀도와 재현율은 trade-off 관계일까? >
모델은 Positive, Nagative을 판단할 때 확률로써 판단한다. 예를 들면 한 레코드에 대하여 결과가 0일 확률 45%, 1일 확률 55%로 판단한다면, 우리에게 결과로 1을 반환해주는 식이다. default로 사용하는 임계치는 50%이기 때문이다. 이 때 임계치를 50%에서 높이게 되면 어떻게 될까?
위의 사진 처럼 임계치를 올리게 되면 기존에는 Positive로 판단했던 데이터들 중 일부를 Nagative로 판단하게 된다. 이 결과 TN과 FN은 값이 커지고 FP와 TP는 값이 작아진다. 따라서 임계치를 올리게 되면 정밀도는 높아지고 재현율을 낮아진다.(구하는 식 참고) 반대로 임계치를 낮게 조정하는 경우 정밀도는 낮아지고 재현율을 높아진다.
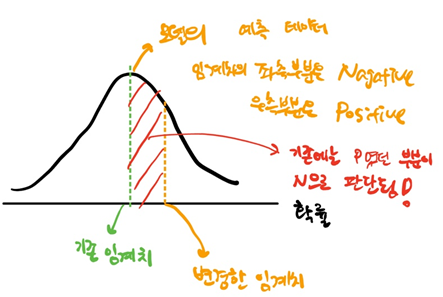
아래 코드는 임계치 조정에 의해 어떻게 결과값이 달라지는지를 보여주는 코드다.
from sklearn.preprocessing import Binarizer
x = [[1, -1, 2],
[2, 0, 0],
[0, 1.1, 1.2]]
# 임계치보다 큰 것은 1로 예측
binarizer1 = Binarizer(threshold=0.5)
print('임계치 0.5\n',binarizer1.fit_transform(x))
binarizer2 = Binarizer(threshold=1.1)
print('\n임계치 1.1\n',binarizer2.fit_transform(x))
임계치를 높이니 기존에는 1로 판단했던 데이터들 중 일부가 0으로 변경됨을 볼 수 있다.
결과값의 확률을 구하는 방법은 없을까? scikit learn의 predict_proba()를 이용하면 된다. 해당 메서드의 반환값은 각 레이블 별 확률이다.(이진 분류에서 첫 번째 컬럼은 Nagative일 확률, 두 번째 컬럼은 Positive일 확률)
# '1. 정확도' 설명에서 사용한 코드에서 이어짐
pred_proba = model.predict_proba(x_test)
print(pred_proba)
정밀도와 재현율은 사용자가 임계값을 조정함에 따라 그 값이 달라질 수 있다. 그런데 문제는 정밀도와 재현율이 모델의 성능을 평가하는 지표라는 것인데, 성능 지표를 사용자가 마음대로 변경할 수 있으면 과연 그 결과를 믿을 수 있을까? 이런 고민 끝에 나온 지표가 F1 score이다.
