1. Callable
1.1. 함수 - 심화
1.1.1. parameter와 argument
1.1.1.1. *와 /
Python에서 parameter 설명을 보다보면 *와 /가 나온다. 이건 무슨 뜻일까? parameter를 설정할 때 *를 넣으면 * 앞에는 무조건 positional 방식으로 agument를 지정해야 한다는 뜻이다. /가 있으면, / 뒤에는 반드시 keyword 방식으로 argument를 전달해야 한다는 뜻이다.
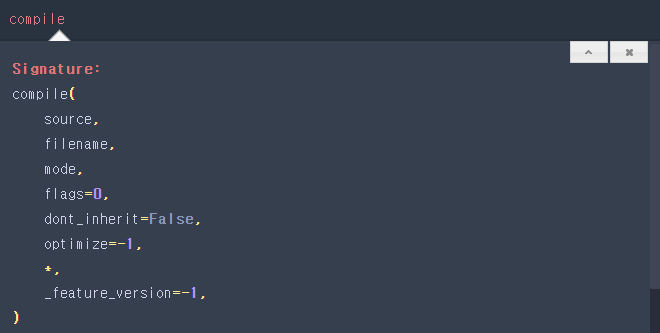 compile 함수의 설명을 보면, optimize 다음에 *가 나온다. 그러므로 optimizer 까지는 반드시 positional 방식으로 사용해야 한다.
compile 함수의 설명을 보면, optimize 다음에 *가 나온다. 그러므로 optimizer 까지는 반드시 positional 방식으로 사용해야 한다.
 반대로 위와 같이 /가 있을 때에는 / 뒤에 오는 parameter는 반드시 keyword 방식으로 사용해야 한다.
반대로 위와 같이 /가 있을 때에는 / 뒤에 오는 parameter는 반드시 keyword 방식으로 사용해야 한다.
1.1.1.2. *args와 **kwargs
다른 설명을 보다모면 아래와 같이 *args나 **kwargs를 많이 볼 수 있다. 이건 무슨 뜻일까?
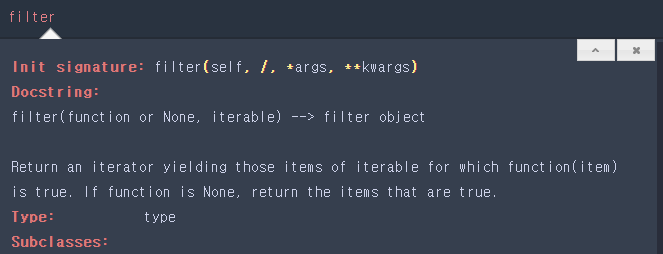
함수 기능을 업데이트 하면서 추가된 parameter들을 *args와 **kwargs에 쓴다. 그래서 설명 아래부분까지 살펴볼 필요가 있다.
*와 **의 차이는 아래와 같다.
- *가 한 번 쓰일 때 : positional 방식으로 개수 상관없이 argument를 넣을 수 있다.
- *가 두 번 쓰일 때 : 반드시 keyword 방식으로 argument가 전달되어야 한다.
1.1.2. 함수와 연산자
아래는 함수를 선언하는 코드이다.
def f(x):
return x함수는 무엇일까?
- f
- f()
- f(2)
함수는 f이다. 이름 자체가 함수이다. 괄호는 연산자이다. 괄호의 의미는 인스턴스화에 대한 이해가 있어야 하므로 추후에 다시 설명하겠다.
연산자는 __call__이 정의된 인스턴스들에 붙을 수 있다. 예를 들면 함수, 클래스가 있으며 사용자가 임의로 __call__를 지정한 인스턴스에도 붙을 수 있다.
1.2. generator
1.2.1 iterator와 generator
우리는 앞서 iterator에 대해 공부했다. __iter__ 라는 메소드가 있는 것(iterable)이 객체가 되면 iterator가 된다. iterator는 메모리에서 데이터를 하나씩 뽑아낼 수 있는 객체라고 했다.
iterator와 generator는 만드는 방법만 다르고 내부 구조는 동일하다. 따라서 generator도 메모리에서 데이터를 하나씩 뽑아낼 수 있는 객체이다.
1.2.2. generator 생성하는 방법
generator를 만드는 방법은 tuple에 comprehension을 적용하거나, 함수에 yield를 사용 하는 것이다.(comprehension에 대한 내용은 아래에 나온다)
# generator 만들기 1
(i for i in range(10))
# generator 만들기 2
def f():
yield 'x'
yield 'y'
yield 'z'1.2.3. generator의 중요한 특징 - next
iterator와 generator가 갖는 가장 중요한 특징은 데이터를 메모리에서 하나씩 꺼낸다는 것이다. 바로 next 함수를 통해서 가능하다.
a = [1, 2, 3, 4]
b = iter(a) # a를 iterator 객체로 만들어줌
next(b) next가 호출될 때마다 하나의 데이터를 메모리에 올리고 다음 데이터를 올릴 준비를 한다. 호출 될 때만 일을 한다고 해서 lazy technique라고 한다. 모든 데이터셋을 소진하면 StopIteration 에러를 발생시킨다. 이 점을 미루어 볼 때 for문은 내부적으로 next를 반복적으로 수행하고, 예외처리를 한 것이다.
그러면 이런 특성이 왜 중요할까? 우리가 사용할 데이터셋의 크기는 매우매우 커서 데이터셋 전체를 메모리에 올릴 수 없다. 따라서 데이터의 일부만 메모리에 올려서 처리할 수 있는 iterator(generator)가 매우 중요한 것이다!(딥러닝 학습 과정을 생각해보자)
2. 함수형 프로그래밍(Functional Programming)
2.1 함수형 프로그래밍이란
2.1.1. 개념
사실 함수형 프로그래밍에 대해 명확히 설명하는 것은 한계가 있다고 한다.(파이썬 언어 만드는데 참여한 David Mertz도 못한다고 함) 다만 어렴풋이라도 이야기 하자면, 수학적 함수를 프로그래밍 한다는 것이다. 수학적 함수는 input과 output이 명확해야 한다.(그런데 Python 함수는 input이 없을 수도 있고 output이 없을 수도 있다.)
어쨌든 명확히 말할 수 없으므로 쓰다보면 느낌이 온다고 한다.
함수형 프로그래밍과 관련된 공식 문서 링크는 아래와 같다.
https://docs.python.org/3/howto/functional.html
2.1.2. 특징
특징에 대해 먼저 이야기 해보자. 간략히 소개하자면 아래와 같다.
- first class : 함수 자체가 데이터와 같이 사용될 수 있다. 그래서 함수는 expression 자리에 올 수 있다.(단, 연산자를 빼고 함수 이름만)
- recursion : 함수 내부에서 함수 자기 자신을 불러올 수 있다.
- list processing : 여러개의 결과 값을 효과적으로 한 번에 처리할 수 있다.
- side effect : 함수는 repr이나 기타 다른 것에 정신이 팔리지 말아야 하며 input과 output에 집중해야 한다.
- expression : 수학적 함수를 지향하기 때문에 어떤 문(statement)보다 식(expression)을 선호한다.
- what rather than how: 계산하는 방법(how)보단 계산하는 대상(what)에 집중한다.
- higher order : 함수를 인자로 받거나 함수를 리턴할 수 있는 함수이다. => 그런데 이건 생각해보면 first class 특징이 있으므로 무조건 만족한다. 함수는 데이터(=값)이기 때문에 input이 될 수도 output이 될 수도 있다.
2.1.3. first class
함수는 데이터(=값)로 사용될 수 있다. 단, 연산자인 괄호를 빼고 말이다.
>>> a = print
>>> a('first class')
'fisrt class'
>>> b = [print, len]
>>> b[1]('abc')
3위와 같이 함수는 expression이기 때문에 identifier에 넣을 수 있다. 그렇게 지정된 identifier는 넣은 함수와 동작이 정확히 일치한다.
2.1.4. comprehension
comprehension은 함수형 프로그래밍의 대표적인 방법이다. 복잡한 코드가 줄어들고 수행 속도가 굉장히 빠르다. 익히 알고 있는 한줄 for, 한줄 if라고 생각하면 될 듯 하다.(정확한 것은 아님)
# comprehension의 예
[i for i in range(10)]속도가 빠르다고 했는데 얼마나 빠르길래 그럴까? %%timeit ~ %timeit을 사용해서 실행 속도 차이를 확인해보자.
%%timeit
temp = []
for i in range(1000000):
temp.append(i)
temp
%timeit [i for i in range(1000000)]
단순히 for문을 쓰면 개당 204ms가 걸리는데 comprehension을 쓰면 119ms밖에 안걸린다. 코드도 간략하니 쓰지 않을 이유가 없다.(그런데 배우기 어려움,,)
comprehension으로 만들 수 있는 구문 예제는 아래와 같다.
# 중첩 comprehesion
[(i, j) for i in range(10) for j in range(6,10)]
# 조건도 걸 수 있음
[i for i in range(10) if i%2==0]comprehension로 사용할 수 있는 객체는 3개가 전부이다. list, set, dictionary이다. 이 세 객체는 모두 mutable한 container이다. 그러면 tuple로 comprehension을 만들면 어떻게 될까?
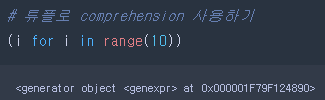
tuple로 comprehension을 사용하니 generator 객체가 되었다. generator가 뭐지???
3. 값을 정하는 순서 - LEGB
3.1. local, enclosed, global
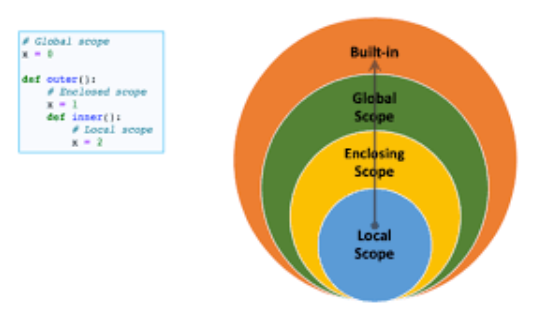
Python에서는 변수, 함수, 객체의 이름이 동일해서 충돌이 나는 경우를 대비해서 값을 지정하는 순서가 있다. 가장 먼저 local 범위를 확인하고 다음으로 enclosed, global 순으로 확인하다. 각각 어떤 것을 의미하는지 살펴보자
-
local
local은 가장 작은 범위로 함수에서 정의되는 범위이다. 함수 밖에서 접근이 불가능하다. -
enclosed
중첩 함수에만 존재하는 범위이다. 바깥 함수에서만 접근이 가능하다. 아예 함수 밖에서는 접근이 불가능한데, enclosed에 들어가려면 local을 거쳐야 하기 때문이다. -
global
Python에서 제일 넓은 범위로 모든 이름이 정의된다.
# 1. 왜이럴까 => local에 a가 없기 때문에 global a 를 가져옴
a = 1 # global
def x():
return a
x()
# 2. 왜이럴까 => local에서 이미 값을 찾았으므로 local
a= 1
def xx():
a = 2 # local
return a
xx()첫 번째 코드 실행 결과는 1이고, 두 번째 실행 결과는 2이다. LEGB 규칙때문이다.
# k는 local 변수이기 때문에 global 영역에서 접근할 수 없다
def b():
k=1
return k
b(), k
local변수를 gobal 영역에서 접근하려고 하면 위와 같이 에러가 난다.
a=1
def x():
def y():
a = a+1
return a
return y
x()()위 실행 결과는 어떨까? 바로 UnboundLocalError가 뜬다. 왜냐하면 지금 a는 함수 밖에서 선언 되었으므로 gloabl 영역에 속해있다. 그리고 함수 y 안에서 a가 호출되는데 문제는 y는 enclosed 영역이라는 점이다.(중첩된 함수 이므로) a = a+1의 영역을 정리해서 보면 enclosed 영역 = global 영역 이므로 범위(scope)가 맞지 않아 에러가 뜬다. 그래서 위 코드를 아래처럼 바꾸면 UnboundLocalError를 피할 수 있다.
# UnboundLocalError 에러 피하기
a=1
def x():
def y():
global a
a = a+1
return a
return y
x()()a를 enclosed 영역에서 global 키워드를 통해 범위를 맞춰주면 연산이 가능한 편법이다. 그런데 a는 1로 최초에 선언되었는데, x()()를 호출할 때마다 1씩 늘어난다.(a+1 이므로) 그래서 편법이라고 하는 것이고 잘 안쓰는게 낫다.
local 영역에 있는 변수를 enclosed 영역에서 사용하기 위해서는 nonlocal 로 선언하면 된다.
3.2. closure 기법
# 함수 안에 또 다른 함수를 만들 수 있다 -> 함수는 데이터니까(firt class)
# 이렇게 하면 x 함수는 z에서만 접근할 수 있는 함수가 된다!!!!
def z():
def x():
return 1
return x()
z()이런식으로 함수는 중첩해서 선언할 수도 있다. 이 코드를 살짝 바꿔서 아래와 같이 바꿔보자
# 함수안에 함수를 만들면 아래와 같은 일이 생길 수 있다! -> z()의 리턴은 x 만 되므로 x에도 ()를 붙여야 연산
def z():
def x():
return 1
return x
z()()이렇게 괄호가 두개 붙는 기법을 closure 기법이라고 한다. 딥러닝에서 자주 쓰이므로 잘 알아야 한다.
# 한 단계 더
def z(m):
def x():
return m
return x
z(3)()
# z(3)의 결과로 x가 반환되니까 x()가 되고 m=3을 넣었으므로 x함수의 리턴값인 m, 즉 3이 나옴# 변수가 두개니까 더 다양하게 사용
# closure technique : 괄호 두개 붙는 함수
def z(m):
def x(n):
return m + n
return x
z(3)(6)위와 같이 m은 고정하고 n만 변경해서 모든 값에 3을 더하는 식으로 사용도 가능하다. 변수를 조절할 수 있으므로 더 유연하게 사용이 가능하다.
