분류의 개요
ML에는 두 부류가 있다. 지도학습과 비지도학습이 그것이다.(강화학습도 ML의 부류라고 하는데, 아예 다른 세상이라고 한다.)
- 지도학습 : 학습 데이터에 정답이 주어져 모델을 학습하는 ML 방식. 대표적으로 분류(classification)과 회귀(regression)이 있다.
- 분류 : target 데이터가 범주형 변수인 경우
- 회귀 : target 데이터가 연속형 변수인 경우
- 비지도학습 : 정답 데이터가 주어지지 않고 데이터의 특성만을 파악하는 모델. 대표적으로 군집화가 있다.
결정 트리
01) 결정트리 개요
결정트리는 데이터에 있는 규칙을 찾아내 트리 구조로 구조화하고 데이터를 분류하는 알고리즘이다.(마치 스무고개 게임처럼) 결정트리를 간략히 나타내면 아래와 같다.
< 결정트리의 구조 >
검은색 마름모는 규칙노드(Dicision Node) 라고 부르며 트리를 데이터를 분류할 때 조건이 된다. 검은색 마름모 아래의 타원 모양의 '사망'과 '생존'은 리프노트(Leaf Node) 로 분류가 완료된 클래스 값들이다. 하나의 규칙으로 분류가 되지 않은 데이터들은 위 서브트리(Sub Tree)가 생성되어 데이터를 다시 분류한다.(위 그림에서 나이나 sibsp로 규칙을 또 다시 적용하는 것)
< 이미지 출처 >
위키백과
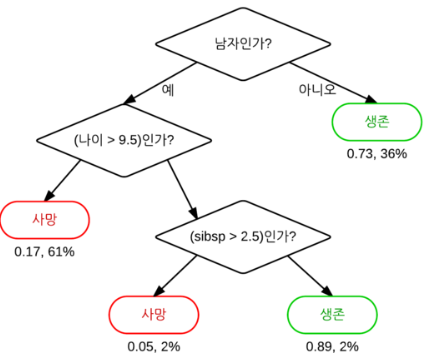
그런데 결정트리의 최대 단점이 여기에서 나오는데, 데이터가 완벽히 분류될 때까지 계속 새로운 규칙을 찾아내어 과적합(overfitting)의 위험이 있다는 것이다. 규칙노드가 많아질수록 모델의 깊이(depth)가 깊어져 학습 데이터에만 fitting 되기 때문이다. 따라서 결정트리가 일반화 되기 위해서는 적절한 질문을 선택하여 한 번에 최대한 정확하게 분류하고, 모델의 깊이는 너무 깊어지지 않도록 해야한다.
결정트리가 적절한 질문을 선택하는 기준은 정보의 균일도이다. 아래 그림을 통해 정보의 균일도에 대해 알아보자.
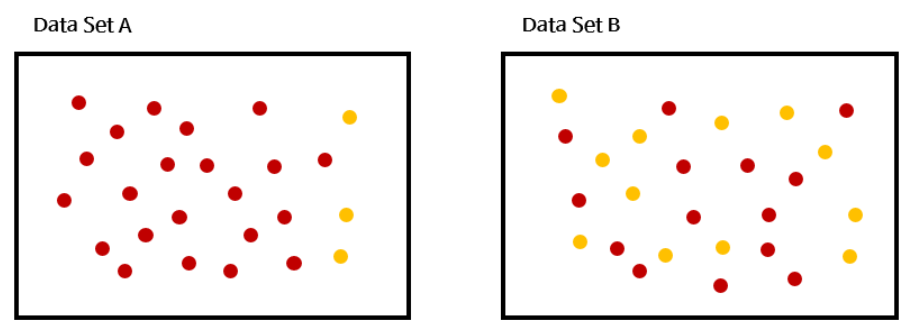
< 적절한 질문인지 판단하는 기준 - 정보 균일도>
위 이미지에서 정보 균일도가 높은 데이터셋은 어떤 것일까? 한눈에 봐도 A가 높다. A는 대부분의 데이터가 붉은색인 반면, B는 붉은색 데이터와 노란색 데이터가 혼재되어있다. 만약 A와 B가 각각 리프노드라고 가정해보았을 때 A는 결과를 쉽게 붉은색 클래스로 결정할 수 있지만, B는 한 번 더 분류를 해야한다.따라서 한 번 규칙노드를 도입할 때 최대한 정확하게 분류를 해야하고, 정확하게 분류한다는 것은 정보 균일도를 기준으로 판단한다.
추가적으로 정보 균일도를 측정하는 방법은 엔트로피를 이용한 정보이득(Information Gain)과 지니계수가 있다.
< 이미지 출처 >
https://dlearner.tistory.com/27
< 정보이득과 지니계수 >
- 정보이득은 엔트로피 개념을 사용한다. 위 이미지 중 데이터셋 A처럼 동일한 데이터만 있으면(일부 노란색 데이터도 있지만) 엔트로피가 낮고, 데이터셋 B처럼 서로 다른 데이터가 섞여 있으면 엔트로피가 높다. 정보이득은 (1 - 엔트로피)로 구한다. 따라서 정보이득은 1에 가까울 수록 좋다.
- 지니계수는 사회의 불평등 지수를 나타내는 지표이다. 0일때 모든 사회 구성원이 평등하고, 1에 가까워질수록 불평등해진다. 이런 개념은 데이터의 균일도에 적용되는데 균일도가 높으면(데이터가 평등하면) 0, 균일도가 낮으면(데이터가 불평등하면) 1이다. (데이터가 평등/불평등하다는 것이 참 어색한데, 말하자면 그렇다는 것이다.)
< 결론 >
정보이득은 1에 가까울 수록 좋고, 지니계수는 0에 가까울 수록 좋다.
자, 그러면 위에서 말한 '한 번의 질문으로 정확하게 분류한다'라는 말의 의미가 이해된다. '한 번 결정노드를 만들 때 정보이득이 1이 되도록, 혹은 지니계수가 0이 되도록 하는 질문을 선정해야 한다'라는 의미로 이해하면 된다.
02) 결정트리 특징
'Black box'라고 불리는 다른 모델들과는 다르게 결정트리는 인간이 이해할 수 있는 몇 안되는 모델이다.(최근에는 '설명가능한 인공지능(XAI)'이 나오고 있지만, 결정트리는 모델 자체가 사람이 이해할 수 있는 모델이다.) 결정트리의 주요 특징은 아래와 같다.
- 알고리즘을 인간이 이해할 수 있고 직관적이다.
- 정보 균일도에 입각해 분류를 진행하므로 feature의 스케일링이나 정규화 같은 전처리가 불필요하다.
- (별다른 규제가 없으면) 데이터가 완벽히 분류될 때까지 가지를 뻗어나간다. Overfitting의 위험이 있다.
세 번째 특징은 일반화가 중요한 ML 모델에게 크리티컬하기 때문에 여러 파라미터를 통해 트리의 깊이를 제한한다. 다음은 트리의 깊이를 제한하는 여러 파라미터들을 간략히 알아보자.
03) 결정트리 파라미터
결정트리는 sklearn에서 DecisionTreeClassfier와 DecisionTreeRegresor 클래스에 구현되어있다. 두 클래스 동일한 파라미터를 사용한다.
< 결정트리의 주요 파라미터 >
- min_samples_split
- 노드를 분할하기 위한 최소한의 데이터 수
- 작게 설정할수록 데이터를 더 많이 쪼갤 수 있으므로 과적합의 위험 증가
- min_samples_leaf
- 리프노드가 되기 위한 최소한의 데이터 수
- max_feature
- 학습에 참여할 feature의 최대 개수 지정
- int/float/sqrt/log가 파라미터로 들어올 수 있으며 각각의 데이터 형에 맞게 계산되어 feature 개수 지정(float형은 퍼센트)
- none은 모든 feature 사용함
- max_depth
- 트리의 최대 깊이를 지정함
- max_leaf_nodes
- 리프노드의 최대 개수를 지정
< min_samples_split과 min_samples_leaf >
두 파라미터는 굉장히 헷갈린다. 아래 예시를 통해 두 파라미터의 차이를 살펴보자.(악필이다,,ㅎㅎ)
빨간색 노드의 경우 한 번 더 분할될 수 있을까? 노드의 데이터는 7개로 split으로 지정된 5보다 크므로 ok. 다음 노드에 A가 3, B가 4개로 완벽히 분류된다면 leaf의 조건도 만족하므로 한 번 더 분할이 가능하다.
이 경우는 어떨까? 사실 이 예제는 틀린 예를 보여주기 위해 넣었다. leaf 조건이 3인데 빨간색 노드의 개수는 2개이다. 리프노드가 되려면 데이터가 최소한 3개 있어야 하는데 빨간 노드에는 데이터가 2개 밖에 없으니 규칙에 위배되므로 이 규칙은 도입되면 안된다.
이 경우 파란색으로 분할이 가능할까? split 조건은 노드의 데이터 개수가 더 많으므로 만족하여 분할할 수 있다. leaf 조건을 살펴보면 리프노드가 되려면 데이터의 개수가 최소 3개 이상 있어야하는데, 파란색 두 노드 모두 3개 이상이므로 조건을 만족하므로 분할할 수 있다.(하지만 정보 이득 부분은 또 따른 문제이므로 분할하는 조건이 정확한지 다시 판 단 필요 )
04) 결정트리 시각화
[02-02. 결정트리 특징]에서 결정트리는 사람이 이해할 수 있는 몇 없는 모델이라고 했다. 인간이 이해할 수 있는 논리로 데이터를 분할하기 때문이다. 따라서 결정트리는 이해가 가능한 만큼 시각화도 할 수 있다. 결정트리의 시각화는 Graphviz 패키지를 이용하고, sklearn의 export_graphviz() 함수로 이미지를 출력한다.
※ Graphviz는 따로 설치가 필요한데, 설치 과정은 기술하지 않겠다.
아래는 Graphviz를 통한 시각화 예시이다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 모델 생성
dt = DecisionTreeClassifier(random_state=11)
# 데이터 로드 및 분할
iris_data = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state=11)
# 학습
dt.fit(x_train, y_train)from sklearn.tree import export_graphviz
# export grapgviz 결과로 tree_result.dot 파일 생성됨
export_graphviz(dt, out_file='tree_result.dot', class_names=iris_data.target_names,
feature_names=iris_data.feature_names, impurity=True, filled=True)import graphviz
# tree_resut.dot을 시각화
with open('tree_result.dot') as f:
graph = f.read()
graphviz.Source(graph) # 시각화
# PDF 형식으로 저장
# graphviz.Source(graph).view() 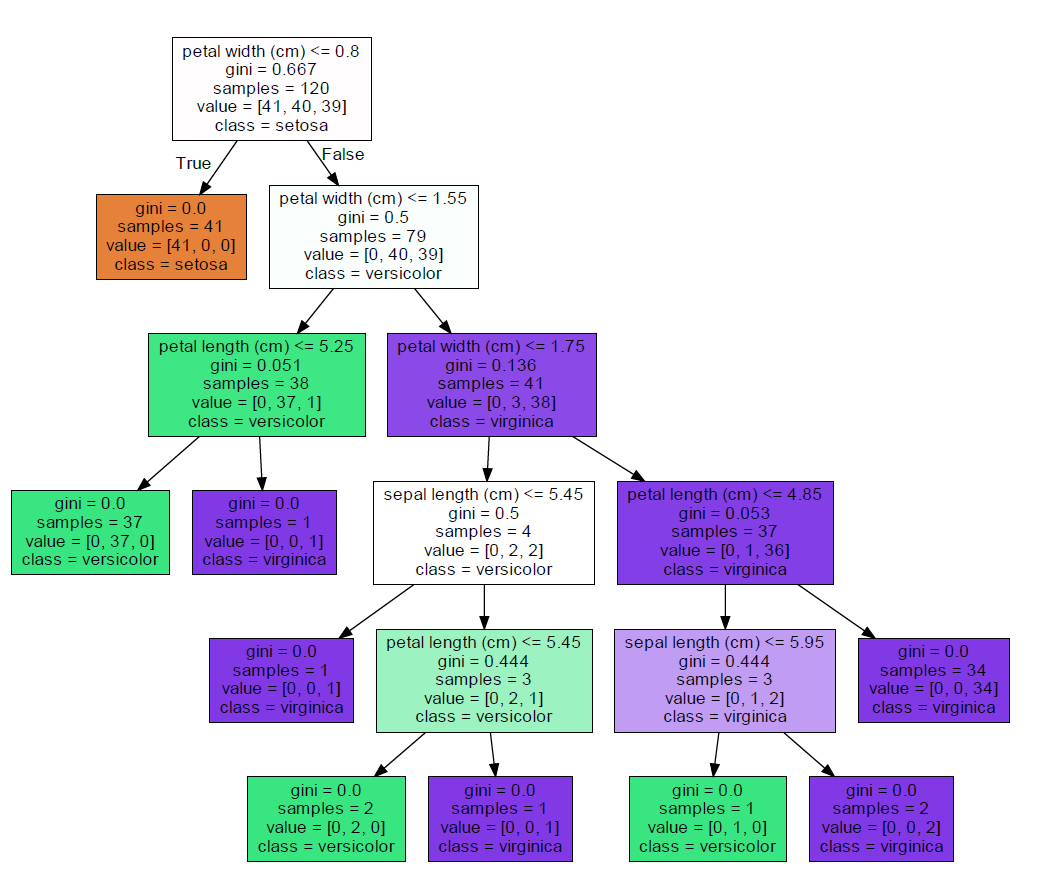
시각화 결과를 하나하나 살펴보자.
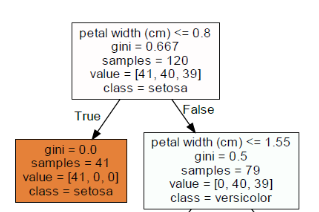 규칙 노드를 먼저 살펴보면, 정보는 아래와 같다.
규칙 노드를 먼저 살펴보면, 정보는 아래와 같다.
- 이번 depth의 규칙은 'petal width(cm) <= 0.8)
- 지니 계수는 0.667
- 해당 노드의 데이터 개수는 120개
- 120개는 0번 클래스 41개, 1번 클래스 40개, 2번 클래스 39개로 구성되어있음
- 클래스별 개수가 가장 많은 클래스 이름은 setosa
위 규칙에 따라 자식노드는 두 개로 나눠진다. 왼쪽 자식노드를 먼저 살펴보자.
- 지니 계수는 0.0으로 해당 노드는 리프노드
- 데이터 개수는 41개
- 41개 모두 setosa 클래스임
오른쪽 자식노드의 해석은 처음에 리뷰했던 규칙 노드와 동일하게 해석하면 된다.
min_samples_split과 min_samples_leaf를 각각 설정하여 트리가 어떻게 변하는지 살펴보자.
< min_sample_split = 4>
가장 아래 있는 노드들을 보면, 데이터 개수가 4개 이하이기 때문에 지니계수가 0이 아니여도 더이상 분할을 하지 않는다.
< min_samples_leaf = 4 >
가장 아래 있는 노드를 보면, 클래스 1과 2로 나눌 수 있음에도 min_samples_leaf에 의해 분할이 되지 않은 것을 확인할 수 있다. (분할 시 데이터 개수는 각각 1개, 3개가 될 텐데 그러면 min_samples_leaf 조건 만족 x)
모델의 깊이를 제한하는 것은 overfitting에 대응하는 중요한 수단이다. 그런데 그에 못지않게 학습에 참여할 변수를 지정하는 것도 중요하다. 다행히 결정트리 계열의 모델들은 feature의 중요도를 파악할 수 있는 feature_importances_ 속성을 제공한다.
data = {'feature' : iris_data.feature_names,
'importance' : dt.feature_importances_}
feature_importance_df = pd.DataFrame(data)
plt.figure(figsize=(10,7))
sns.barplot(x='feature', y='importance', data=feature_importance_df)
plt.show()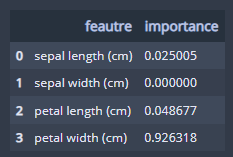
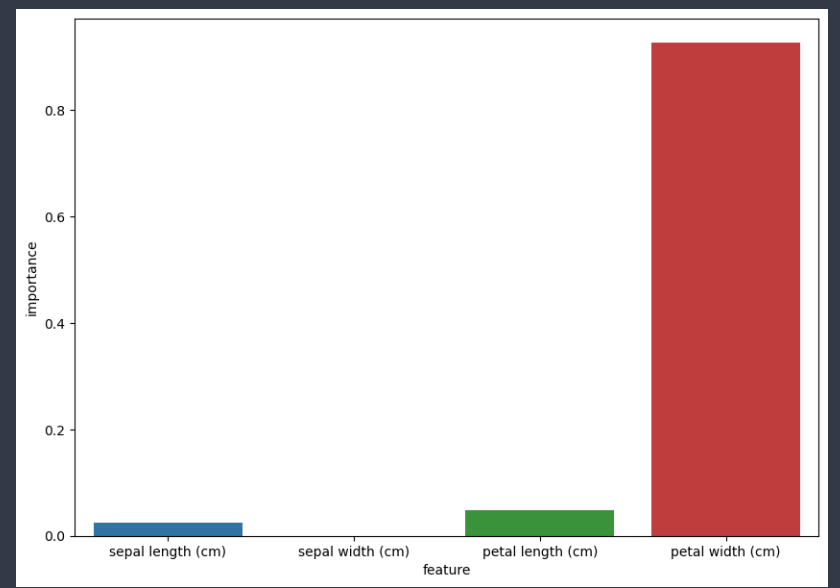
확인 결과 'petal width'가 가장 중요한 feature인 것으로 판단된다.
