GBM(Gradient Boosting Machine)
01) GBM 개요
03-01. 앙상블 학습 개요에서 잠깐 이야기한 것처럼 부스팅 알고리즘은 여러개의 약한 학습기(weak leaner)를 순차적으로 학습시키면서 예측이 틀린 부분에 가중치를 부여하여 학습이 약한 부분을 강화해 가능 방식이다.
GBM은 가중치의 업데이트에 경사하강법(Gradient Descent)을 사용한다.
오차는 (실제 값 - 예측 값)으로 계산하며, 모든 모델은 오차를 줄이는 방향으로 학습을 한다. 그리고 오차를 줄이는 방향을 나타내는 방법이 경사하강법인 것이다. 아래에 경사하강법에 대한 간략한 설명을 써놓겠다.
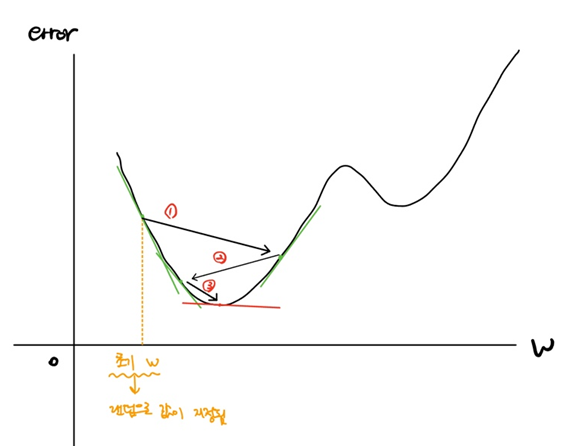
< 경사하강법 >
경사하강법은 오차가 최소가 되는 지점의 weight를 찾는 방법이다. wheight는 결과값에 대하여 각 feature가 갖는 가중치이다. w를 바꿔가며 모델의 오차를 측정하면 위와 같은 그림이 나온다.(실제로는 더욱 복잡한 그래프가 나오겠지만, 설명을 위해 간략히 3차 함수로 그렸다.) x축은 weight의 변화를 나타내고, y축은 weight에 따른 모델의 오차이다. 경사하강법은 다음과 같은 단계를 거치며 진행된다.
- 초기 weight로 임의의 값이 지정된다.
- 초기 weight 지점에서 미분을 한다. 미분을 하게되면 그 시점의 기울기가 나오는데, 기울기가 음수라면 양의 방향으로, 기울기가 양수라면 음의 방향으로 학습률(learning rate)만큼 이동한다.(이동한다는 의미는 weight를 업데이트 한다는 의미)
- 업데이트한 weight에서 2번 작업을 반복해서 수행한다. 수행이 완료되는 시점은 기울기가 0이 되는 시점이다. 왜냐하면 기울기가 0이라는 것은 모델이 가질 수 있는 최소한의 오차를 뜻하기 때문이다.(모든 ML 모델은 오차가 0일 수 없음)
※ 물론 오차 그래프가 꺽이는 부분은 모두 기울기가 0이므로 기울기가 0이라는 것이 항상 최소 오차를 의미하는 것은 아니다. 이 부분과 기타 이 부분에서 자세히 다루지 않은 내용은 다음에 기회가 될 때 포스팅 하겠다.
GBM은 sklearn.ensemble 모듈 안에 GradientBoostingClassifier() 클래스로 구현되어 있다. 물론 GBM도 회귀 모델을 지원하며 회귀 모델은 동일한 모듈 안에 GradientBoostingRegressor() 클래스로 구현되어 있다. 모델 사용 방법은 다른 sklearn 모델들과 동일하다.
GBM은 일반적으로 랜덤포레스트보다 좋은 예측성능을 가진다. 하지만 수행시간이 오래 걸리고 하이퍼파리미터 튜닝에도 조금 더 공을 들여야한다. (GBM은 랜덤포레스트와 달리 CPU 병렬처리를 지원하지 않음)
02) GBM의 하이퍼파라미터
GBM도 랜덤포레스트에서 사용하는 하이퍼파라미터를 다수 사용하고 있다. 대표적으로 n_estimator, max_depth, max_features가 있는데, 해당 하이퍼파라미터들은 위에서 이미 설명했으므로 생략하고 GBM만의 하이퍼파라미터를 알아보도록 하겠다.
- loss : 경사하강법에서 사용할 비용함수를 지정한다.(오차를 측정하는 방법)
- learning_rate : 약한 학습기가 경사하강법을 통해 한 번 weight를 업데이트 하는 크기를 뜻한다. 0 ~ 1 사이의 값을 지정하는데, 너무 작은 값을 지정하면 학습 시간이 너무 오래 걸리고, 너무 큰 값을 지정하면 오차 값이 최소가 되는 지점을 지나칠 수도 있다.
n_eistomators를 높이고learning_rate를 줄이면 많은 약한 학습기가 촘촘히 학습하므로 성능은 향상되지만, 그만큼 속도가 많이 걸린다.
- subsample : 약한 학습기가 사용할 데이터 샘플링 비율이다. 0 ~ 1 사이의 값을 지정한다.(0.5는 전체의 50%를 사용한다는 의미)

라벨 값이 0과 1 밖에 없는 데이터들을 GBM을 이용하여 분류 할수 있나요?