[ 사용된 기술 및 패키지 ]
- pyhon
- pandas/numpy
- keras
- konlpy
- selenium
[ 담당 업무 ]
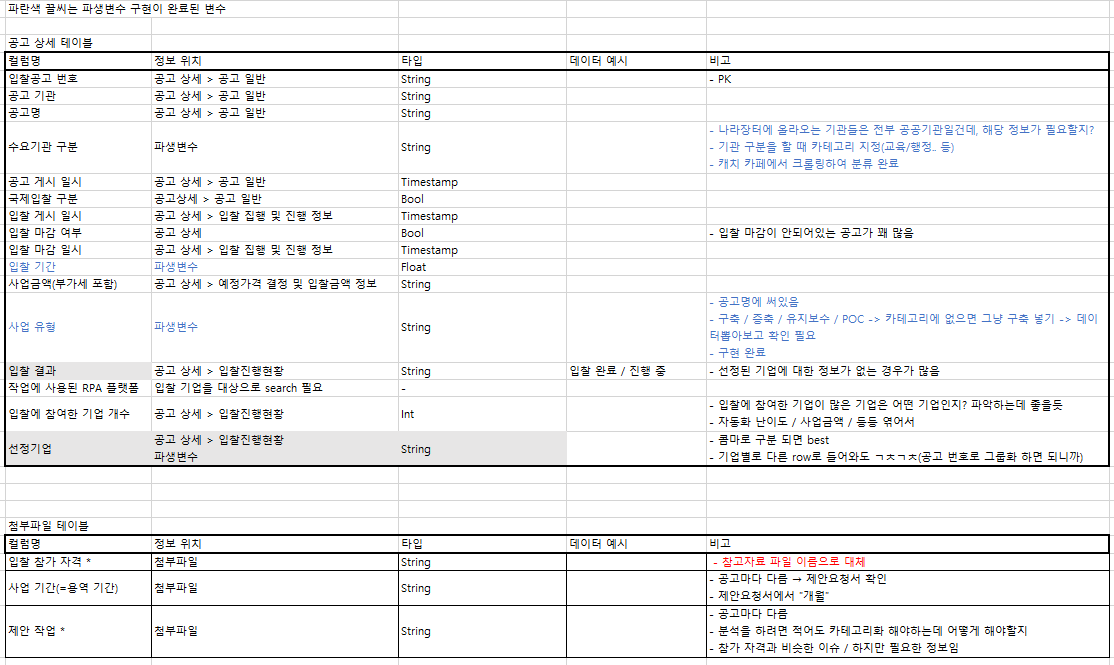
- 데이터 정의 및 스키마 설계
- 딥러닝 모델 제작
- 파생변수 제작
1. 프로젝트 개요
이번 해커톤은 명지대학교, 영남대학교, 성신여자대학교가 공동으로 주최한 AI•RPA 해커톤었다. 공공기관은 RPA 보급 확대를 위해 외부에 프로젝트를 맡기는데, 그 정보는 '나라장터'에 과업지시서와 함께 올라온다. 우리가 해결해야할 세부 과제는 아래와 같다.
- 나라장터에 올라온 공공기관의 RPA 공고를 종합해 RPA 도입 현황 보고서 만들기
해커톤 대회는 3일간 열렸으며 데이터에 대한 이해를 바탕으로 AI와 RPA를 접목하여 결과물을 내야하는 대회였다. 우리 팀은 나와 RPA 개발자 두 명이 함께 대회에 참여했으며, 나는 데이터 부분과 AI 개발을 담당했다.
2. 진행한 업무
2-1. 데이터 정의
프로젝트의 첫 단계로 데이터를 정의했다. 보고서를 만들기 위해서는 많은 데이터가 필요하고, 그 데이터는 어디에서 얻을 수 있는지, 어떤 형태로 얻어져야 하는지 결정이 필요하다. 따라서 우리 팀은 필요한 데이터를 리스트업하고 획득 방법과 데이터 타입 등을 정리했다.
2-2. 파생변수 생성
1) 딥러닝 모델
RPA 공고라고 하더라도 공고마다 요구되는 작업의 성격이 다르다. 따라서 보고서에는 요구되는 카테고리별 현황 정보를 제공해야 한다. 우리는 공고 제목을 활용하여 카테고리를 분류하고자 했다.
최초에는 여러 개의 공고 제목을 직접 확인하며 임의로 카테고리와 분류에 기준이 될 단어를 선정했다. 그런데 팀원 중 한 명이 데이터 신뢰도 관련된 이슈가 발생할 수 있음을 시사해주었다. 여러 개의 공고 제목을 읽고 임의로 카테고리와 분류 기준을 제시하는 것은 내 주관이 개입될 수 있다는 것이었다. 데이터에 기반하여 믿을 수 있는 카테고리 분류 방법이 필요했다.
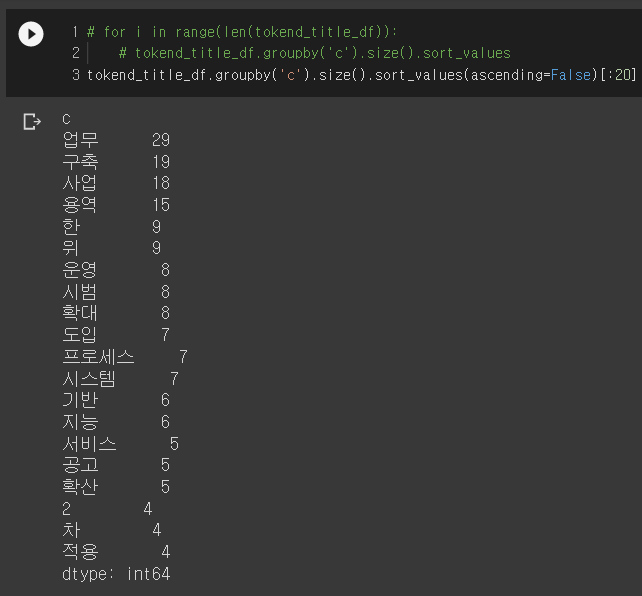
우선 우리는 공고 제목의 일부를 가져와 토큰화 하고 공고의 성격을 나타낼 수 있으면서 빈출된 단어를 추려보았다. 이렇게 선택된 카테고리는 [구축, 시범, 운영, 확대] 이렇게 4가지였다.
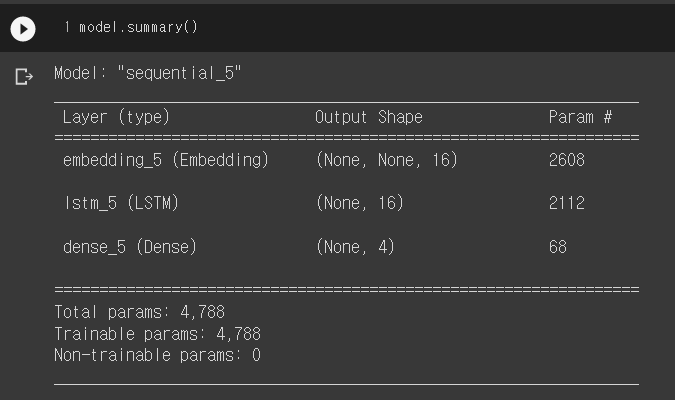
이후 공고 제목을 넣으면 위에서 제시한 4가지 카테고리 중 어느 것에 해당되는지 판단하는 LSTM 모델을 개발했다. 개발에 사용한 프레임워크는 keras이다. 아래 이미지는 개발한 AI 모델의 요약 정보이다.
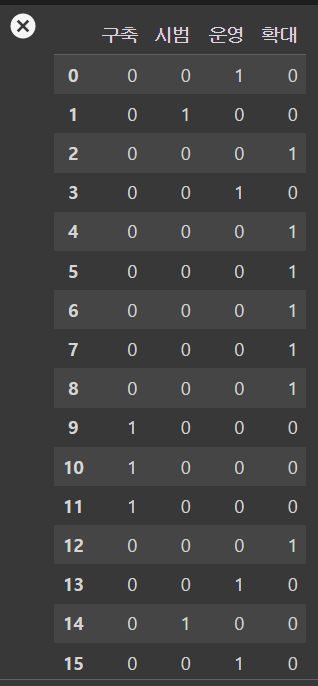
이렇게 만든 모델에 공고 제목을 넣으면, 아래와 같이 어떤 카테고리에 해당되는지 분류해준다.
2) 기타 파생변수
RPA 현황을 파악하는 데에는 공고를 낸 기업에 대한 카테고리화도 필요하다고 판단되었다. 공공기관이 나라장터를 사용한다고 하지만 한국 산업은행, 대학 기관, 지자체 등에서도 공고를 올리기 때문이다. 기관을 카테고리화 하기 위해 기업 정보를 제공하는 '캐치 카페'를 이용했으며 selenium을 활용해 자동화 했다.
공고 개시 및 입찰 완료 날짜를 기반으로 공고 기간을 파악했다.
3. 느낀점
3-1. 성취감
지금까지 데이터 분석 공부를 하면서 항상 이미 만들어진 데이터를 사용했다. 데이터를 수집할 때 항상 느끼는 것이지만, 프로젝트에 딱 맞고 내 마음에 쏙 드는 데이터를 찾기란 쉽지 않다. 그리고 딱 맞는 데이터를 찾는다 하더라도 내 손을 거치지 않은 데이터이기 때문에 큰 애정이 가지 않는다. 그런데 이번 해커톤에서는 내가 필요한 데이터를 가져올 수 있게 설계하고 스키마를 정했다는 것, 그리고 많이 부족하지만 대략적인 테이블 지시서를 만들어 봤다는 것에 큰 성취감과 만족감을 느꼈다.
머신러닝과 딥러닝을 꾸준히 공부 해왔는데, 항상 이론적인 공부만 해왔다. 실습도 책에 있는 것이나 수업에 다루는 것이 전부였으므로 배운 내용을 잘 적용하고 있는지 의문이었다. 그런데 이번 해커톤을 통해 교과서에서 벗어나 직접 모델을 만들었다는 것 자체가 뿌듯했다.(물론 주변에 도움을 많이 받긴 했지만)
3-2. 아쉬운 점
아쉬운 점도 존재한다. RPA 개발 프로그램의 라이센스 이슈가 발생했고 시간이 약간 지체되었다. AI 모델이 제대로 작동하기 위해서는 많은 데이터가 필요한데, 충분한 데이터를 확보하지 못해 모델을 제대로 학습시키지 못했다.
내 부족한 점도 여실히 드러났는데, 기존에 한 AI 공부는(특히 딥러닝 부분) 너무 이론에 갇혀있지 않았나 싶다. 이론은 아는데 사용하지 못하면 소용이 없다는 것을 깊이 깨달았다. 공고명 카테고리 분류 모델을 만드는 데에 시간을 너무 많이 할애해서 정작 파생변수를 많이 만들지 못한 점 역시 아쉽다.
그래도 AI와 RPA 두 파트로 나누고 서로를 보완하며 끊임없이 의사소통을 한 경험은 매우 값지다고 생각한다. AI와 RPA 두 축이 모두 자신의 일에 최선을 다 했기에 좋은 결과가 있었지 않았나 싶다.
3-3. 입상 결과
여러 우여곡절 끝에 우리 팀은 우수상을 수상했다. 기분이 많이 좋았다.

