01. SLECT 키워드
01-01. 개요
- 테이블에서 데이터를 조회하는 키워드
- 여러 절로 나눌 수 있어 유연한 사용이 가능하지만, 여러 절을 동시에 사용하면 복잡해짐
- ‘DISTINCT’를 사용하여 중복이 제거된 행 데이터 조회
- ‘ORDER BY’를 통해 데이터 정렬
- ‘WHERE’을 사용하여 조건에 맞는 행 조회
- ‘LIMIT’ 혹은 ‘FETCH’를 사용하여 행의 하위 집합 선택
- 'GROUT BY’를 사용하여 데이터 그룹화
- ‘HAVING’을 사용하여 조건에 맞는 그룹 조회
- 여러 JOIN 연산자를 사용하여 다른 테이블과 데이터 조인
- ‘UNION’, ‘INTERSECT’, ‘EXCEPT’를 사용하여 집합 간 연산 수행
01-02. SELECT절과 FROM절
SELECT 절에는 행 이름을 적용한다.(여러 행을 선택할 경우 콤모(,)로 구분) 모든 행을 선택할 경우 asterisk(*)를 사용한다.
FROM 절에는 추출할 데이터가 속한 테이블 이름을 기입한다.
-- 단일 컬럼 조회
SELECT firtst_name
FROM Customer;
-- 모든 컬럼 조회
SELECT *
FROM Customer;asterisk를 사용할 때에는 중의할 점이 있다.
- python이나 java 등 다른 언어로 옮길 때 문제가 될 수 있다.
- 불필요한 컬럼까지 조회되므로 불필요한 연산이 증가하고 속도가 떨어질 수있다.
⇒ 따라서 asterisk는 거의 사용하지 않는 것이 바람직함
01-03. 두 개의 행을 하나의 행으로 만들기
'||'를 사용하는 방법과 concat_ws() 함수를 사용하는 방법이 있다.
-- 방법 1
SELECT
name || '_' || lastname
, firt_name
, last_name
FROM
Customer;
-- 방법 2
SELECT
concat_wa('+++', first_name, last_name)
, first_name
, last_name
FROM
Customer;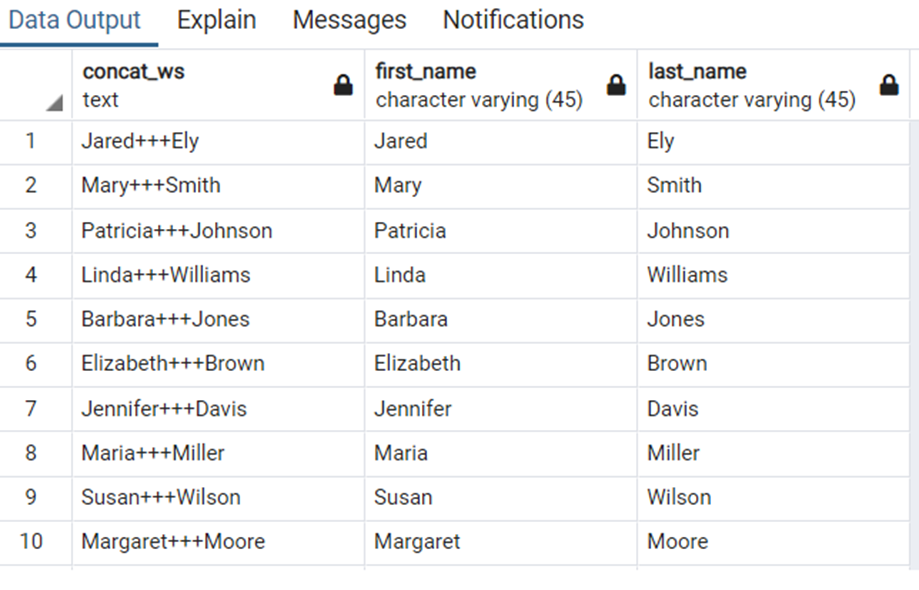
02. Alias
02-01. 개요
SELECT절에서 행의 이름을 임시로 부여할 수 있다. 컬럼 이름이 너무 긴 경우나 컬럼 이름이 명확하지 않은 경우에 쿼리에 좀 더 명확하고 많은 의미를 담기 위해 컬럼 이름을 임시로 지정한다. AS 키워드를 사용하고, 해당 키워드는 생략 가능하다.
-- 기본 사용
SELECT
first_name AS 이름
, last_name 성
FROM Customer;-- alias에 공백이 있는 경우는 큰따옴표(" ")로 묶는다.
SELECT
concat_wa('', first_name, last_name) AS "이 름 전 체 출 력"
FROM
Customer;03. ORDER BY
03-01. 개요
SELECT절에서 조회한 데이터를 정렬할 때 사용한다. 정렬하려는 기준이 여러 가지라면 콤마(,)로 구분한다. default는 오름차순(ASC)이며 내림차순을 원할 때에는 DESC로 설정한다. 두 개의 열로 정렬할 경우, 첫 번째 기준으로 정렬하고 같은 값은 두 번째 기준으로 정렬한다.
연산 순서를 보면 SELECT절이 ORDER BY 우선이다. 따라서 SELECT절에서 사용하지 않은 컬럼으로는 정렬할 수 없고, ORDER BY에는 SELECT절에서 사용한 alias를 사용할 수 있다.
-- 이름을 기준으로 내림차순 정렬
SELECT
first_name
, last_name
FROM
Customer
ORDER BY
first_name DESC;-- 두 개의 기준으로 정렬
SELECT
first_name
, last_name
FROM
Customer
ORDER BY
first_name ASC
, last_name DESC;
03-02. NULL이 있는 데이터 정렬
NULL이 있다면 정렬을 어떻게 할까? 오름차순(ASC) 적용 시 NULL 값이 가장 먼저 나오고, 내림차순(DESC) 적용 시 NULL이 가장 마지막에 나온다.(따로 옵션 지정하지 않았을 때)
NULLS FIRST/LAST 옵션으로 NULL이 나오는 위치는 변경할 수 있다.
-- NULLS FIRST/LAST 옵션 예제
SELECT
num
FROM
sort_demo
ORDER BY
num DESC NULLS FIRST;04. DISTINCT
SELECT 절에서 중복된 행 데이터를 제거한 후 데이터를 조회한다.
SELECT
DISTINCT bcolor
FROM
distinct_demo
ORDER BY bcolor;