1. 윈도우 함수
1-1. 윈도우 함수 개요
SQL에는 집계함수가 있다. 집계함수는 데이터를 그룹화하여 하나의 대표 값을 반환하는 아주 유용한 함수이다. 그런데 집계함수는 컬럼 간의 연산은 잘 수행하지만, 레코드 간의 연산은 처리하지 못하는 문제가 있다. 따라서 레코드 간의 연산을 처리하기 위한 함수인 윈도우 함수(Window Function)이 만들어졌다.
윈도우 함수는 아래와 같은 몇 가지 특징이 있다.
- 서브쿼리는 사용 가능하지만, 중첩쿼리는 사용이 불가능하다.
- OVER 키워드가 필수로 사용된다.
- 두 가지 종류가 있다. BETWEEN을 사용하는 타입과 사용하지 않는 타입이다.
윈도우 함수는 기본적으로 아래 형태로 사용한다. 대괄호([ ])에 쓰인 부분은 생략이 가능하다.
SELECT
WINDOW_FUNCTION (ARGUMENTS)
OVER( [PARTITION BY 컬럼] [ORDER BY] [ROWS BETWEEN ~ AND] )
FROM
TABLE
;윈도우 함수는 행을 하나씩 선택하며 연산을 수행한다. 그래서 경우에 따라서 BETWEEN을 사용해 연산할 행을 프레임으로 지정할 필요가 있다.
1-2. 윈도우함수 옵션
윈도우 함수는 OVER 절이 필수로 사용되어야 한다. OVER 절 안에는 다양한 옵션을 제공할 수 있다.
-
PARTITION BY 컬럼
SQL에서 그룹화하는 것처럼 윈도우 함수를 적용할 데이터를 나눈다. 예를 들어 PARTITION BY 부서로 옵션을 주면, 부서별로 윈도우를 나누어 계산한다. -
ORDER BY 컬럼
데이터 정렬 기능과 같이 윈도우 안에서 함수 적용 전에 데이터를 정렬한다. PARTITION을 지정하면 그 안에서 데이터를 정렬한다. -
ROWS BETWEEN ~ AND ~
윈도우의 프레임을 지정한다. '~'에 조건으로 제시될 수 있는 키워드는 아래와 같다.
- CURRENT ROW : 현재 행
- n PRECEDING : n행 앞
- n FOLLOWING : n행 뒤
- UNBOUNDED PRECEDING : 앞 행 전부
- UNBOUNDED FOLLOWING : 뒷 행 전부
1-3. 예제에 사용할 데이터 소개
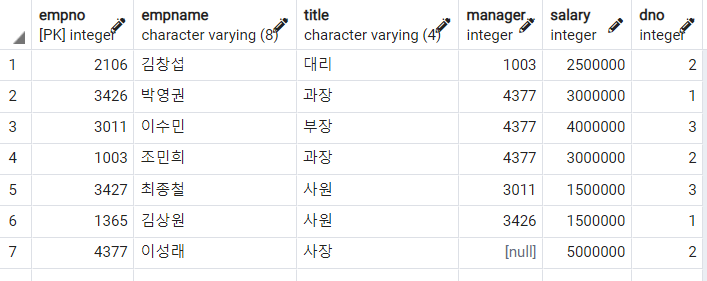
eployee라는 테이블을 만들어 사용해보자. 이 데이터는 경영정보 튜터링 5주차 - SQL 기초에서 사용한 데이터이다.
DROP TABLE IF EXISTS Employee;
CREATE TABLE Employee(
EMPNO INT PRIMARY KEY,
EMPNAME VARCHAR(8),
TITLE VARCHAR(4),
MANAGER INT,
SALARY INT,
DNO INT
);
INSERT INTO employee
VALUES
(2106, '김창섭', '대리', 1003, 2500000, 2),
(3426, '박영권', '과장', 4377, 3000000, 1),
(3011, '이수민', '부장', 4377, 4000000, 3),
(1003, '조민희', '과장', 4377, 3000000, 2),
(3427, '최종철', '사원', 3011, 1500000, 3),
(1365, '김상원', '사원', 3426, 1500000, 1),
(4377, '이성래', '사장', NULL, 5000000, 2)
;
2. 윈도우함수 종류
2-1. 순위 함수
순위 함수에는 RANK, DENSE_RANK, ROW_NUMBER이 있다.
1) RANK 함수
RANK는 각 행의 순위를 반환한다.
-- 월급을 기준으로 순위 매기기
SELECT
empname
, title
, salary
, RANK()
OVER(ORDER BY salary DESC) AS "월급 순위"
FROM
employee
;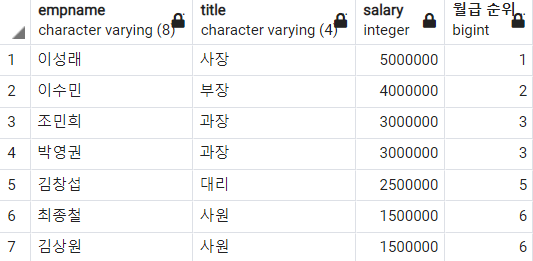
주의깊게 볼 것은 '조민희 과장'과 '박영권 과장'은 월급 순위가 공동 3위이다. 다음 순위를 보면 4가 아닌 5인 것을 확인할 수 있다. RANK 함수는 공동 순위 개수 만큼 건너뛰고 다음 순위를 반환한다.
2) DENSE_RANK 함수
DENSE_RANK 함수도 순위를 매기는 방식이 조금 다르다. 쿼리를 통해 RANK 함수와의 차이점을 살펴보자.
-- 월급을 기준으로 순위 매기기 : RANK와 DENSE_RANK 비교
SELECT
empname
, title
, salary
, RANK()
OVER(ORDER BY salary DESC) AS RANK
, DENSE_RANK()
OVER(ORDER BY salary DESC) AS DENSE_RANK
FROM
employee
;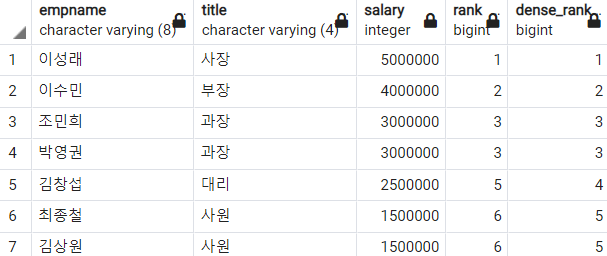
RANK함수는 공동 순위가 있을 때 그 개수만큼 건너뛰었던 것에 반해 DENSE_RANK는 건너뛰는 것 없이 순위를 구하는 것을 볼 수 있다.
3) ROW_NUMBER 함수
ROW_NUMBER 함수는 행의 출력되는 위치를 순위로써 제공하는 함수이다. 마찬가지로 위에서 사용한 RANK함수, DENSE_RANK 함수와 비교해보자.
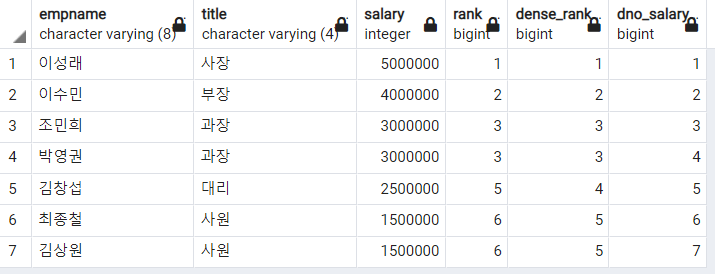
-- 행 위치로 순위 매기기
SELECT
empname
, title
, salary
, RANK()
OVER(ORDER BY salary DESC) AS RANK
, DENSE_RANK()
OVER(ORDER BY salary DESC) AS DENSE_RANK
, ROW_NUMBER()
OVER(ORDER BY salary DESC) AS dno_salary
FROM
employee
;
OVER 절에 PARTITION을 넣어주면 어떻게 바뀔까? ROW_NUMBER 함수를 대표로 PARTITION BY의 동작을 확인해보자.
-- 부서별 월급 순위 매기기
SELECT
empname
, title
, salary
, RANK()
OVER(ORDER BY salary DESC) AS RANK
, DENSE_RANK()
OVER(ORDER BY salary DESC) AS DENSE_RANK
, dno -- 부서별 월급 순위 반환
, ROW_NUMBER()
OVER(PARTITION BY dno ORDER BY salary DESC) AS dno_salary
FROM
employee
ORDER BY
dno
;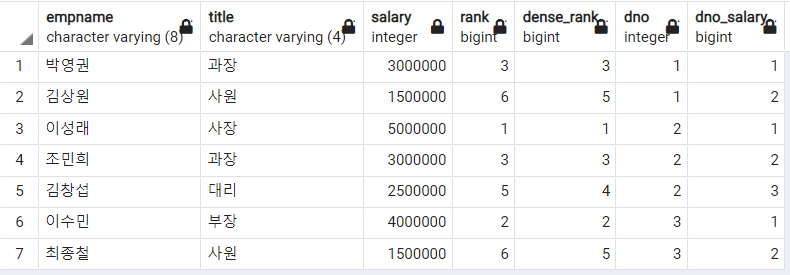
dno를 기준으로 그룹화 한 것처럼 결과가 나왔다. PARTITION BY는 모든 윈도우 함수에서 사용 가능한 옵션임을 기억하자.
2-2. 행순서 함수
1) FIRST_VALUE 함수
FIRST_VALUE 함수는 윈도우 별 처음 나온 값을 반환한다.
-- 부서별 월급이 가장 높은 사람 반환
SELECT
empname
, title
, salary
, dno
, FIRST_VALUE(empname)
OVER(PARTITION BY dno ORDER BY salary DESC) AS "부서별 최고 월급"
FROM
employee
ORDER BY
dno
;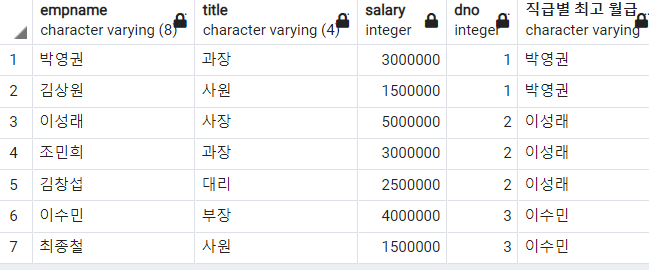
1번 부서에서는 박영권이, 2번 부서에서는 이성래가, 3번 부서에서는 이수민이 제일 높은 연봉을 받는다. 이 경우에는 부서별로 월급을 내림차순 정렬하기 때문에 연봉이 최고인 사람이 첫 행에 오게된다. 따라서 프레임을 지정하지 않아도 된다.(아래 예제와 차이점 생각해보기)
2) LAST_VALUE 함수
LAST_VALUE는 윈도우 별 가장 마지막에 나오는 값을 반환한다.
-- 부서별 월급이 가장 낮은 사람 반환
SELECT
empname
, title
, salary
, dno
, LAST_VALUE(empname)
OVER(PARTITION BY dno ORDER BY salary DESC
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS "부서별 최저 월급"
FROM
employee
ORDER BY
dno
;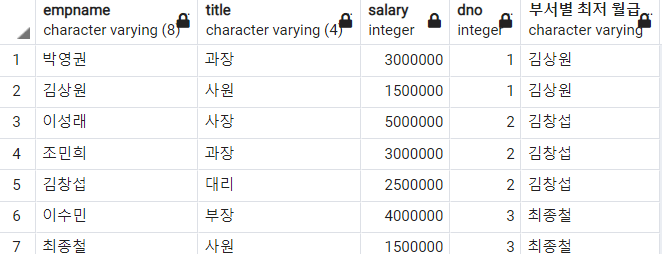
이번 예제에서는 프레임을 지정했다. 왜냐하면 첫 번째 행부터('박영권'부터) 도는데, 연산할 범위를 지정하지 않았기 때문에 윈도우 함수는 자기 자신이 나오게 된다. 아래는 프레임을 지정하지 않았을 때의 결과이다.
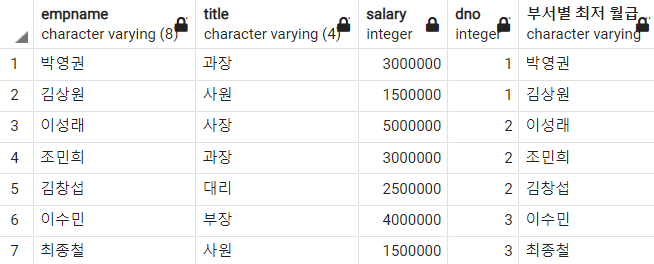
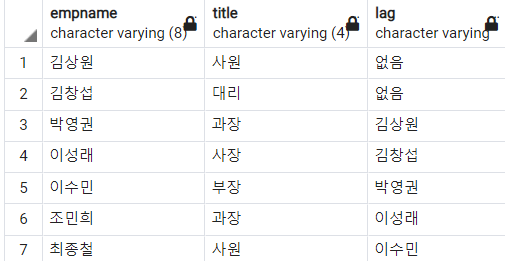
3) LAG 함수
LAG 함수는 파티션 별로 지정한 수 만큼 앞에 있는 행을 가져올 수 있다. LAG함수는 인자를 세 개 갖는데, 0LAG(출력할 행, 앞 행 개수, null일 경우 반환값) 순서이다.
-- 이름별로 오름차순 정렬하고 두 개 행 앞에 있는 사원 이름 가져오기
SELECT
empname
, title
, LAG(empname, 2, '없음') -- 2행 앞에 있는 사원 이름을 가져오고, null일 경우 '없음' 반환
OVER(ORDER BY empname )
FROM
employee
ORDER BY
empname
;
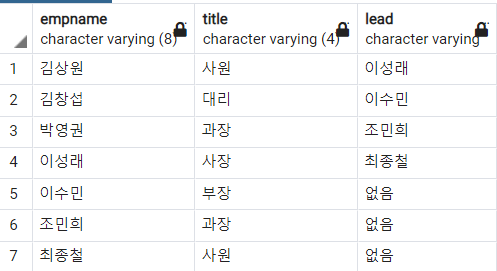
4) LEAD 함수
LEAD 함수는 LAG 함수와 반대이다. 파티션 별로 지정한 수 만큼 뒤에 있는 행을 가져온다.
-- 이름별로 오름차순 정렬하고 세 개 행 뒤에 있는 사원 이름 가져오기
SELECT
empname
, title
, LEAD(empname, 3, '없음')
OVER(ORDER BY empname )
FROM
employee
ORDER BY
empname
;
2-3. 비율함수 함수
1) PERCENT_RANK 함수
PERCENT_RANK함수는 파티션 별 윈도우에서 제일 먼저 나오는 것을 0, 제일 늦게 나오는 것을 1로 해서 행의 순서를 기준으로 하여 백분율을 구한다.
-- 부서별로 개인의 월급을 순서에 대한 비율로 구하기
SELECT
empname
, title
, dno
, PERCENT_RANK()
OVER(PARTITION BY dno ORDER BY salary DESC)
FROM
employee
ORDER BY
dno
;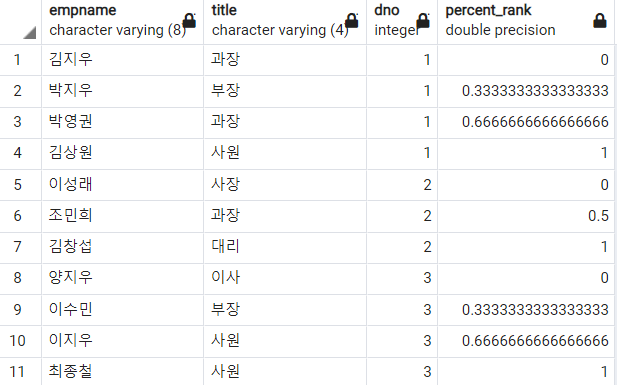
정확한 확인을 위해 데이터를 조금 추가해보았다. 0~1 사이의 수로 순위로써 백분율이 반환된 것을 볼 수 있다.
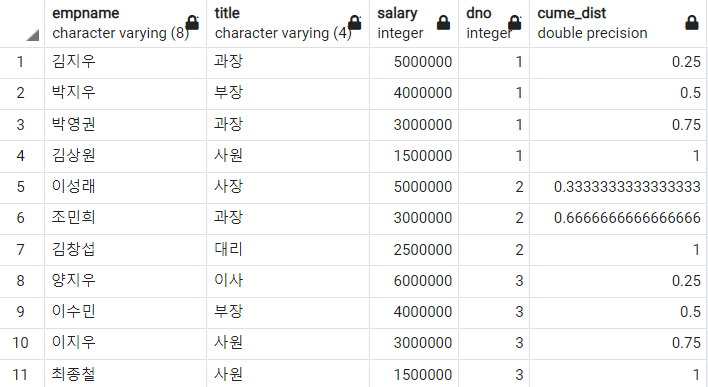
2) CUME_DIST 함수
CUME_DIST 함수는 현재 행보다 작거나 같은 데이터에 대해 누적 백분율을 구한다.
-- 부서별로 월급의 누적 백분율 구하기
SELECT
empname
, title
, salary
, dno
, CUME_DIST()
OVER(PARTITION BY dno ORDER BY salary DESC)
FROM
employee
ORDER BY
dno
;
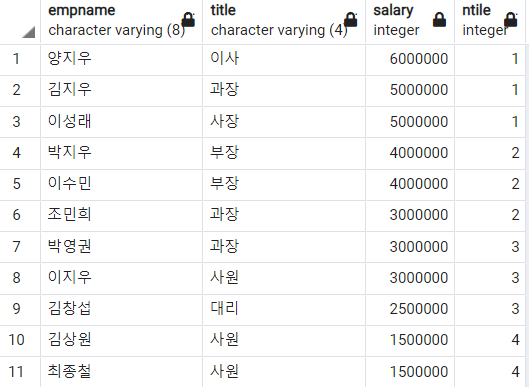
3) NTILE 함수
NTILE 함수는 인자로 전달된 개수 만큼 그룹으로 나눈다.
-- 전체 사원을 월급별로 4개의 그룹으로 분류
SELECT
empname
, title
, salary
, NTILE(4)
OVER(ORDER BY salary DESC)
FROM
employee
;
참고한 사이트 : https://velog.io/@zinu/SQLD-2과목-SQL-기본-및-활용-윈도우-함수
