1. 배경
1-1. 민원인 입장
구청에 민원을 넣어본 사람이라면, 답변을 받기까지 오랜시간이 걸리는 것을 한 번 쯤은 경험해 보았을 것이다. 실제로 우리 조의 한 조원은 민원 처리에만 50일이 걸렸고, 정확한 처리 기관을 미리 알 수 없어 하염없이 기다려야 했다. 물론 민원을 처리하는 구청 입장에서는 민원인에게 정확한 답변을 주기 위해 시간이 오래 걸리는 것일 수도 있지만, 민원인 입장에서는 소위 "민원 뺑뺑이"라는 느낌을 받는다.
1-2. 민원 처리인 입장
민원을 처리하는 공무원들은 어떨까? 공무원들은 아래 자료처럼 업무 과중을 겪는 사람들이 많고, 그 중 민원을 분류하는 과정에서 소모되는 인력이 많고 민원 분류 관련된 지원도 적다고 한다.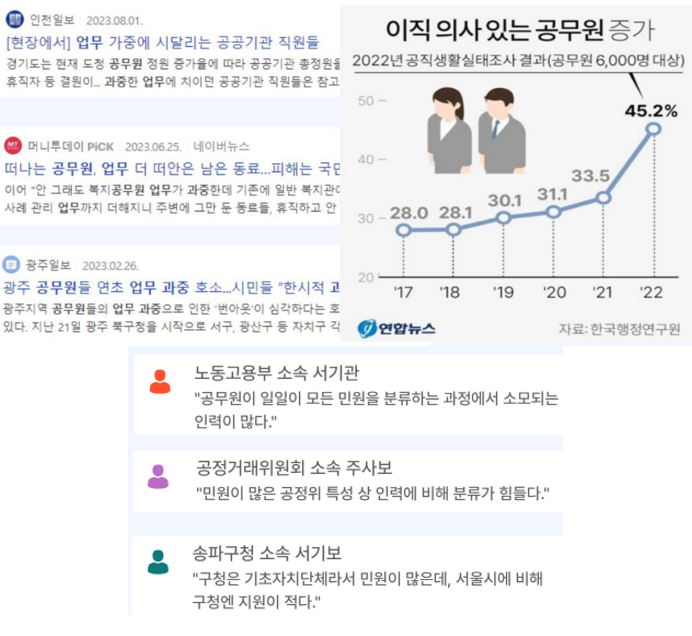
아래 자료를 보면 확실히 기초자치단체의 민원 업무 강도가 높다.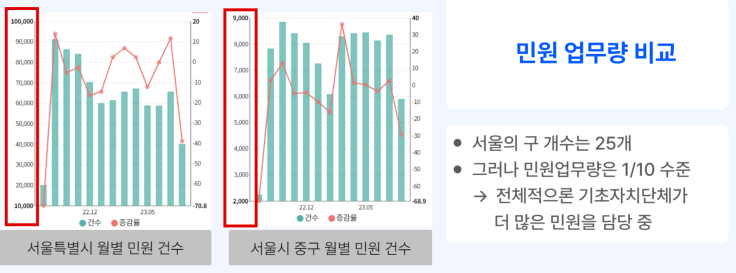
2. 데이터
민원 자동 분류기를 만들기 위해 필요한 데이터는 크게 두 가지이다. 민원 데이터와 그 민원을 처리한 처리 부서 데이터가 그것이다.
2-1. raw 데이터
민원 데이터는 각 지자체에 접수되는 민원을 통합적으로 관리하는 시스템인 '새올 전자민원창구'(이하 새올)를 이용한다. 새올의 특징은 아래와 같다.
- 통합 관리 시스템이긴 하지만, 각 지자체마다 민원을 접수하는 페이지는 모두 다르다.(서울시는 25개의 구이므로 25개의 페이지를 각각 크롤링 해야함)
- 민원인이 '공개민원'으로 지정한 민원만 확인 가능(새올에서 확인 가능한 것보다 더 많은 민원이 있을 것)
- 민원이 처리 되었다면, 민원 처리 부서(A국 B과 형태)와 답변 내용이 댓글처럼 달림
민원 처리 부서 데이터는 구청 홈페이지에서 조직도를 통해 과별 담당 업무를 가져왔다. 그런데 각 구청마다 홈페이지 구조, 표기 방식 등이 전부 다르기 때문에 일일이 손으로 가져올 수 밖에 없었다. 구청의 조직 구조는 다행이 같았는데, ~국 ~과 ~ 팀 형태였다. 예를 들면 '행정자치국 교육미래과 교육지원팀' 형식이다. 우리는 조직 구조 중 과에 집중하기로 결정했다.(국은 너무 단위가 커서 업무 분류가 거의 의미 없고, 팀은 너무 많아서 오히려 분류에 방해가 됨 / 민원 데이터에 답변한 과까지 나와있으므로 과를 기준으로 삼음)
이렇게 얻은 데이터는 민원 데이터 124,698건, 민원 처리 부서(과) 934건을 확보했다.
2-2. 데이터 전처리
민원 데이터에 거친 전처리 방법은 아래와 같다.
-
결측치 처리
민원 데이터 중 새올 자체의 문제로 제대로 처리되지 않은 데이터는 결측치로 나와 결측치는 제거했다.(답변 부서에 대한 정보가 없는 경우가 대다수였으므로 사용이 불가능한 데이터임) -
이송이첩 및 행정동에서 처리한 데이터 제거
이송이첩이나 행정동에 이관한 경우에도 구청에서 담당한 과가 있어야 한다. 그런데 새올에는 구청의 담당과가 아니라 이송이첩 받은 기관이나 행정동이 나와있었다. 따라서 구청의 과를 알아야 하는 우리로서는 사용할 수 없는 데이터이므로 제거했다. -
과거에 개편되거나 통합된 과 확인 및 최신화
민원 데이터 중 약 4만개의 데이터가 현재 존재하지 않는 부서이다. 그래서 각 구청에 문의하여 해당 업무를 담당하고 있는 현재 부서를 맵핑했다.
위와 같은 과정을 거쳐 민원 데이터는 88,093건이 남았다.
처리 부서와 관련된 데이터에서 가장 중요한 것은 이 과가 어떤 일을 하는지 나타내는 '과별 업무'이다. 과별 업무 데이터는 지울 것이 없으므로 텍스트 정제 과정만 거친다. 과별 업무에서 한글, 숫자만 남겼다.
3. 구현
3-1. 데이터 흐름
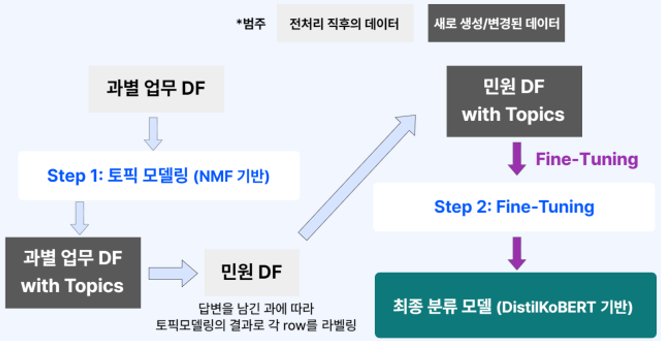
데이터는 위와 같이 흘러간다. 과별 업무 데이터는 토픽 모델링을 통해 군집화를 진행한다. 이렇게 나온 과 군집을 민원 데이터에 join하고 BERT 기반 모델에 넣어 fine tuning 한다.
3-2. 토픽 모델링
과별 업무에 토픽 모델링을 적용해 군집화한다. 토픽 모델링 필요한 이유는 아래와 같다.
- 기초자치단체의 업무는 어느 구청이던 대부분 공통된 업무가 대부분임
- 그런데 기초자치단체 별로 부서 명칭이 다르거나 조직 구성이 약간씩 다른 경우가 있음
전국 모든 기초자치단체에 적용할 수 있는 프로세스를 만들기 위해서는 위와 같은 이슈를 해결할 필요가 있다. 그래서 과별 업무를 기준으로 과들을 군집화 하는 것이다.
토픽 모델링 방법론은 다양하다. 머신러닝 기반, 통계 기반 등 기초를 둔 분야도 다양하다. 그 중 우리는 NMF 방식을 선택했다. 다른 방법들도 사용해보았는데, NMF 방식이 제일 성능이 좋았기에 해당 방법을 사용하기로 했다.

그런데 토픽 모델링 결과에는 문제가 있었다. 군집화 점수가 82%인 만큼 잘 되었는데 데이터 불균형 문제가 크다. 그래서 데이터 수가 적은 클래스에 대해서는 chat GPT에 데이터 증강을 요청해 데이터 불균형 문제를 해결하고자 했다.
3-3. 분류 모델
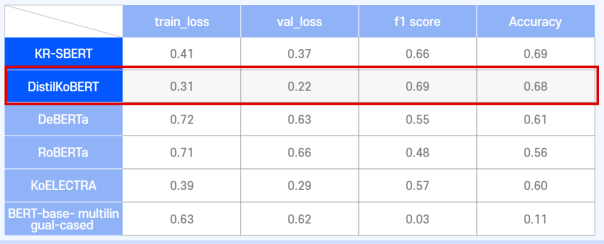 위와 같이 여러 pre-trained 모델들을 fine-tuning 했다. 그 결과 DistilKoBERT 모델이 가장 우수한 성능을 보여 해당 모델로 선택했다. 그런데 대체로 성능이 별로 좋지 않은 것을 볼 수 있는데, 시간이나 GPU 장비의 한계로 각 모델마다 5 epoch까지 밖에 학습하지 않았기에 성능이 그리 좋지 않은 것이다.
위와 같이 여러 pre-trained 모델들을 fine-tuning 했다. 그 결과 DistilKoBERT 모델이 가장 우수한 성능을 보여 해당 모델로 선택했다. 그런데 대체로 성능이 별로 좋지 않은 것을 볼 수 있는데, 시간이나 GPU 장비의 한계로 각 모델마다 5 epoch까지 밖에 학습하지 않았기에 성능이 그리 좋지 않은 것이다.
모델 학습에는 민원 데이터를 넣는다. 이 때 target은 민원 처리 부서, feature는 민원 제목과 민원 내용이다.
3-4. 최종 워크플로우
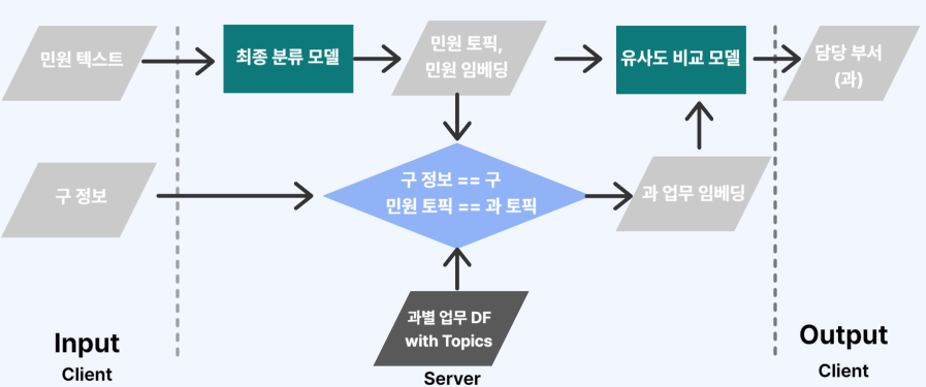
4. 시연
시연 영상은 아래 링크에서 확인할 수 있다.
https://youtu.be/uWeIt_C9EBI
5. 기대효과
5-1. 민원인 입장
민원이 접수 되었을 때 처리할 부서가 특정되므로 민원 뼁뺑이가 발생할 일이 적어질 것이다. 또한 다른 부서로 이송이첩 하는 경우도 많이 줄어들 것이므로 빠른 민원 처리를 경험할 수 있다.
담당 부서를 예측하여 처리할 부서를 미리 제시함으로써 민원 처리를 하염없이 기다리는 것이 아니라 추가 정보를 얻는 측면에서 고객 경험을 강화하고, 민원인은 민원을 접수하기 전에 민원 처리 부서를 확인하므로써 필요한 자료 등을 문의할 수 있다.
5-2. 기초자치단체
대부분의 민원을 정확하게 분류할 수 있으므로 민원 분류 업무 강도를 획기적으로 줄일 수 있고, 민원 분류와 같은 단순 업무에서 벗어나 가치가 더 높은 업무에 집중할 수 있다.
민원 접수를 자동화 할 수 있는 기회를 제공할 수 있다. 민원 접수 자동화 시스템은 시스템 도입이 어려운 작은 기초자치단체에게 분류 모델 하나만 제공해도 큰 효과를 거둘 수 있기 때문에 경제적이며 민원인들에게 답변을 빠르게 제공해 신뢰성을 확보할 수 있다.
또한 과중한 업무에 퇴사를 고려하는 공무원 수가 많은 만큼 한 부분이라도 업무 강도를 줄여 장기적인 인력 손실을 방지할 수 있다.
6. 느낀점
6-1. 시간 관리의 중요성
이번 프로젝트에서는 시간 관리의 중요성을 절실히 느꼈다. 시간 관리 중에서도 특히 큰 틀에서의 계획과 업무 수행 중 계획 수정이 중요함을 느꼈다
이 프로젝트는 약 한 달 반 동안 진행되었는데, 프로젝트를 완성하기에 매우 짧은 시간이었기에 시간관리가 무척 중요했다. 그래서 우리 팀은 시작에 앞서 주차 단위로 주요 과업을 선정해 스케쥴을 작성했다. 프로젝트 주제는 우리 모두가 제대로 잘 알고 있는 분야도 아니었고 자연어 처리 기술도 제대로 몰랐기에 공부와 학습을 병행해야 하는 상황에서 그 둘의 균형을 맞추는 것이 관건이었다. 각 주차마다 어떤 일을 해야하는지 큰 틀이 정해지니 시간이 부족하다는 불안감이 덜하고 오히려 현재 상황에 집중할 수 있었다.
계획을 세우긴 했지만, 그대로 실천하기에는 어려운 점이 많았다. 우리의 체력을 과대평가 했던 점, 공부하는 분야를 명확히 알지 못해 제대로된 로드맵을 그리지 못했던 점 등이 계획대로 되지 않았던 주요한 원인이다. 그래도 우리는 앞서 세웠던 계획을 최대한 유지하면서 현재 상황에 맞춰 조금씩 계획을 수정했다. 이렇게 유연하게 업무 계획을 수정한 덕분에 한 명도 무리하지 않고 무사히 프로젝트를 마무리했다고 생각한다.
6-2. 몰입
그동안 진행한 프로젝트는 대부분 학교 수업과 병행한 것이기 때문에 온전히 시간과 노력을 쏟기 어려웠다. 하지만 이번 프로젝트는 여름방학 동안에 진행한 프로젝트이기에 온전히 집중할 수 있었다. 팀원들과 아침부터 밤까지 함께 고민하고 공부하며 프로젝트 준비를 했던 기억이 좋게 남아있다. 그리고 이러한 경험 덕분에 앞으로 프로젝트와 다른 일을 병행하더라도 프로젝트에 집중할 수 있을 것 같다.
