1. 디지털 혁신
1-1. 3A
1) 구성
디지털 혁신을 이끌고 있는 세 가지 기술을 줄여서 3A라고 부른다. 3A는 RPA, AI, Smart Anlaytics이다.
2) RPA(Robotic Process Automation)
RPA는 사람이 하는 반복 단순 업무를 컴퓨터가 알아서 수행할 수 있도록 하는 규칙기반 프로그램이다. 매일 각 부서의 업무 보고 내용을 하나의 보고서로 만든다고 할 때 RPA가 대신하는 것과 같이 사용할 수 있다.
3) AI(Artificial Intelligence)
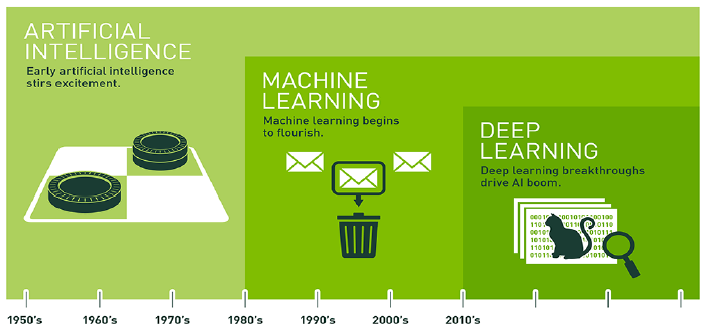
AI는 인간이 지능으로 할 수 있는 사고와 학습을 컴퓨터가 할 수 있도록 하는 방법 연구 분야이다.
 출처 : http://www.it-b.co.kr/news/articleView.html?idxno=12442
출처 : http://www.it-b.co.kr/news/articleView.html?idxno=12442
인공지능은 데이터를 다루는 대상에 따라 아래와 같이 구분된다.
- 인공지능 : 사람이 데이터의 패턴을 파악하여 규칙을 만들어주면 컴퓨터는 그 규칙에 따라 데이터를 처리하는 방식
- 머신러닝 : 데이터의 패턴과 특징을 컴퓨터가 직접 파악하여 규칙을 스스로 만드는 방식
- 딥러닝 : 인공신경망을 이용하여 데이터를 더 자세하게 파악하는 방식
인공신경망 : 인간의 뉴런을 수학적으로 모델링한 퍼셉트론으로 입력층, 은닉층, 출력층으로 구성되어있다. 각 퍼셉트론은 각각의 가중치를 가지고 있고 최적의 가중치를 찾아 데이터를 정확하게 처리하는 것이 목표이다.
AI는 1950년대부터 연구된 분야이다. 그런데 왜 이제와서 빛을 발했을까? 아래와 같은 이유가 있다.
- 늘어난 데이터
- 강력해진 컴퓨팅 파워
- 효율적인 알고리즘의 개발
4) Smart Analytics
- Smart Analytics는 데이터를 분석하여 의사결정 지원하는 분야이다.
- 사용 가능한 데이터가 더 많아져서 빛을 발한 분야이다.
1-2. 빅데이터
1) 빅데이터의 개념과 특징
빅데이터란 무엇일까? 디지털화로 인해 실시간으로 수집되는 대량의 데이터이다. 전통적인 고객의 카드 결제 데이터, 통신 데이터 등도 빅데이터에 포함되고 사용자 행동 데이터, 이동 동선, 음성, 텍스트 등 수집 가능한 모든 데이터가 빅데이터이다.
빅데이터의 특징은 5V로 나타낼 수 있다.
- velocity : 빅데이터는 실시간으로 수집되는 데이터이기 때문에 생성, 수집되는 속도가 매우 빠르다.
- variety : 빅데이터는 텍스트, 이미지, 음성 등 그 형태가 다양하다.
- value : 빅데이터는 효과적인 경영, 강력한 고객관리 등 비지니스 이점이 크다.
- veracity : 빅데이터를 정확히 사용하기 위해서는 수집되는 데이터가 정확하고 신뢰성이 있어야 한다.
- volume : 빅데이터는 그 양이 매우 많다.
2. 데이터베이스 개념
2-1. 데이터베이스 시스템
1) 데이터베이스 개념과 특징
데이터베이스는 응용 시스템들이 공유하여 사용하는 운영 데이터들이 구조적으로 통합된 모임을 의미한다. 다시 말하면, 데이터베이스는 기업 운영에 필요한 데이터들을 하나의 통합된 구조로 적재한 것이다.
데이터베이스는 아래와 같은 특징이 있다.(중요한 단어만 기억하기)
- 데이터베이스는 특별한 경우를 제외하고 하나로 유지되며 여러 사용자에 의해 동시에 사용된다.
- 모든 데이터는 중복을 최소화 해야한다.
- 데이터베이스에는 실직적인 데이터 뿐만 아니라 데이터에 대한 설명도 포함되어야 한다. 데이터에 대한 설명이란 스키마 혹은 메타데이터이다.
- 응용 프로그램과 독립성을 갖는다.
2) 데이터베이스 관련 용어
데이터베이스에서 사용되는 용어는 처음에 볼 때 매우 헷갈린다. 용어 중 내포와 외연은 잘 사용하지 않는 용어이다.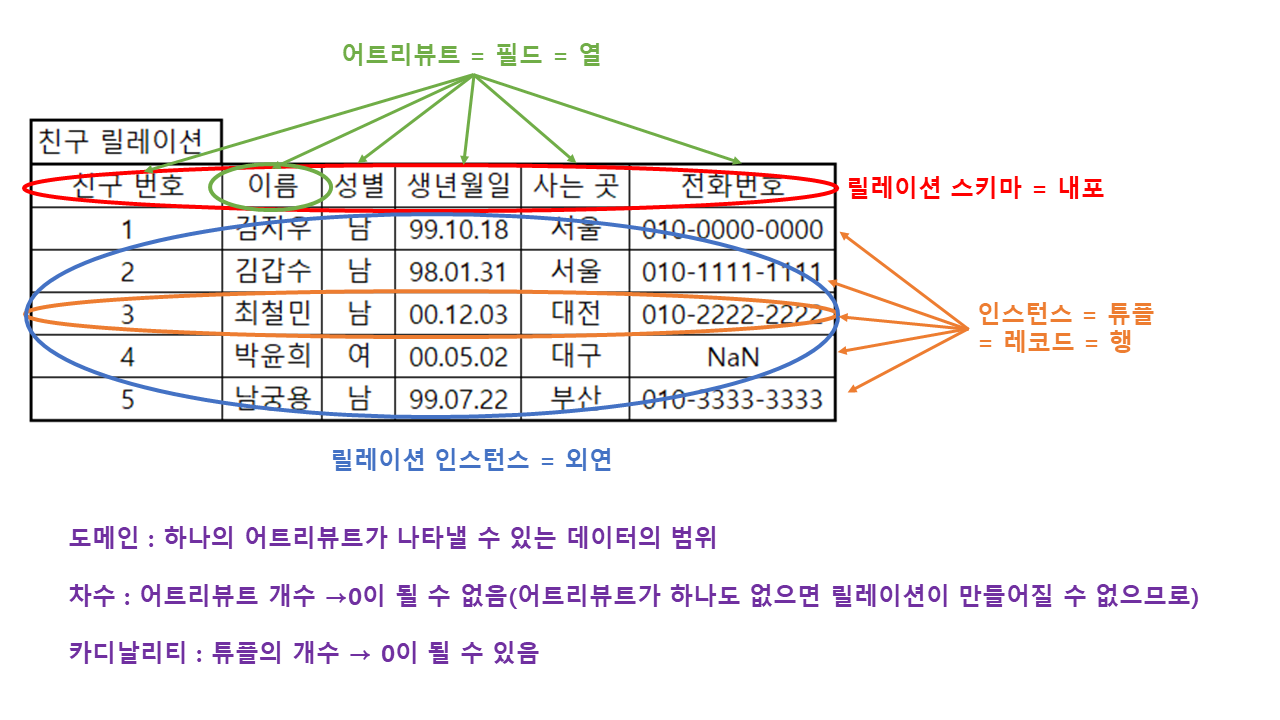
2-2. DBMS★★★
1) DBMS 란
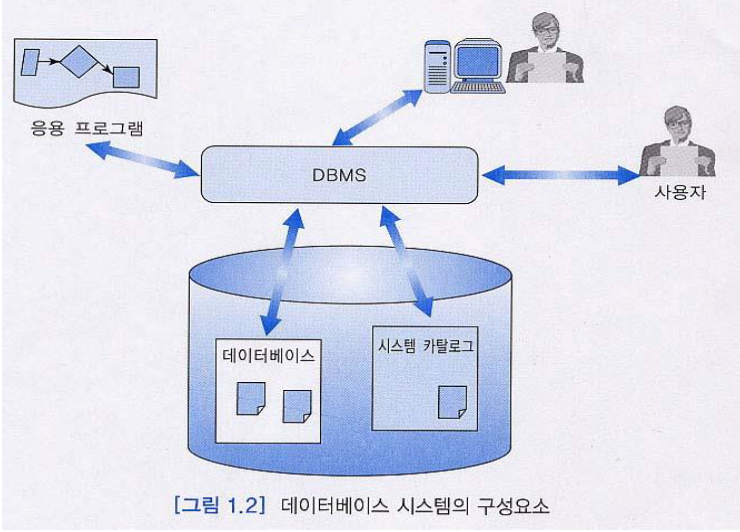
데이터베이스가 통합된 하나의 데이터 저장소라면, DBMS는 데이터베이스를 관리하고 운영하는 소프트웨어이다. 많은 DBMS가 있는데 오라클, 엑세스, MySQL 등이 있다.
DBMS는 사용자의 요청에 따라 데이터베이스에 접근하여 데이터를 처리(조회 및 변경)하는 역할을 한다. 아래 그림과 같이 사용자와 데이터베이스 중간에 놓여 사용자의 요청에 맞는 동작을 데이터베이스에 전달한다.
 출처 : 경영정보 과목 교재
출처 : 경영정보 과목 교재
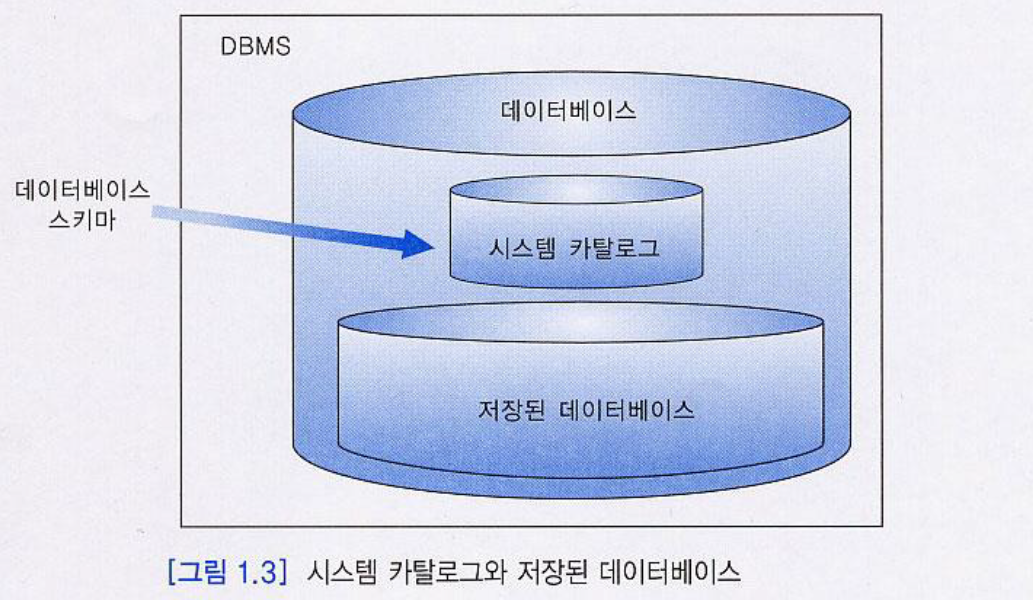
데이터베이스는 '시스템 카탈로그'와 '저장된 데이터베이스'가 결합된 형태이다.
- 시스템 카탈로그 : 릴레이션 스키마 정보 저장
- 저장된 데이터베이스 : 릴레이션 인스턴스 정보 저장
 출처 : 경영정보 과목 교재
출처 : 경영정보 과목 교재
사용자가 DBMS에 어떤 동작을 요청할 때 SQL을 사용한다.
2) DBMS의 발전
데이터베이스에 저장하는 데이터는 데이터 모델로써 실제 세계의 일부분을 추상화하여 저장한 것들이다.
[ 실제 세계의 일부분 추상화?]
예를 들어 김지우라는 사람은 실제 세계에 존재하는 사람이다. 이 사람을 그대로 데이터베이스에 넣을 수는 없으므로 이 사람을 나타낼 수 있는 요소들을 뽑아 데이터로 저장한다. 저장되는 요소는 이름, 나이, 성별, 생년월일, 직업 등이 있으며 이 정보는 김지우의 일부분이다.
데이터 모델은 개념적 데이터 모델, 표현 데이터 모델로 분류될 수 있다.
- 개념적 데이터 모델 : 사람의 인식과 유사하게 데이터베이스 전체 데이터베이스의 논리적 구조 명시 / 엔티티-관계(ER) 모델
- 표현 데이터 모델 : 사용자가 이해하는 개념이면서 동시에 데이터가 조직되는 방식을 나타냄 / 관계 데이터 모델
이 중 가장 많이 사용되는 DBMS는 관계형DBMS(=RDBMS) 이다.
3) RDBMS
관계형 DBMS는 아래 이미지와 같이 여러 릴레이션이 서로 관계를 가지고 있는 구조를 말한다. 한 릴레이션에 모든 정보를 다 넣으면 좋지 않을까 싶지만 그럴 경우 데이터 처리 속도, 데이터 무결성 측면에서 이슈가 발생할 수 있기 때문에 관계형 DBMS를 사용한다.
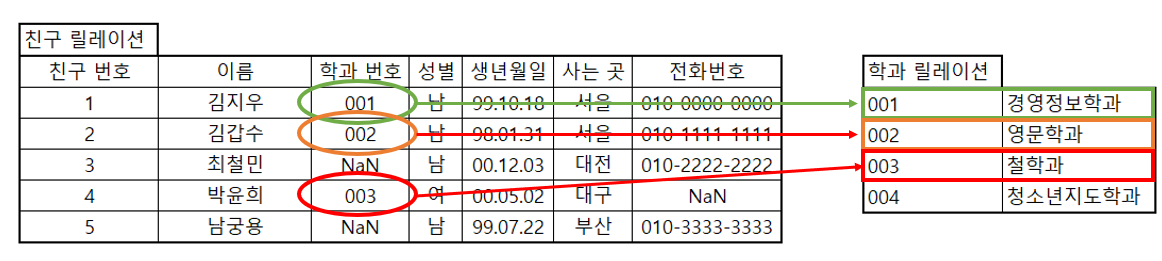
4) DBMS 언어 - SQL
DBMS는 사용자와 데이터베이스 사이에서 사용자의 요청을 데이터베이스에 전달하여 업무를 지원하는 소프트웨어이다. 따라서 사용자가 DBMS에게 어떤 동작을 요청할 때 사용되는 언어가 SQL이고, SQL에는 세 가지로 나뉜다.
-
데이터 정의어(DDL : Data Definition Language)
데이터 정의어는 스키마를 정의할 때 사용되는 명령어다. 스키마를 조작하기 때문에 결과는 시스템 카탈로그에 저장된다.
데이터 정의어에는 CREATE, ALTER, DROP이 있다. -
데이터 조작어(DML : Data Manipulation Language)
데이터 조작어는 스키마가 아닌 개별 인스턴스에 대한 동작을 할 때 사용되는 명령어다. 개별 인스턴스에 접근하기 때문에 저장된 데이터베이스에서 동작한다. 데이터 조작어는 SQL로 직접 작성하거나 C, Java와 같은 고급 프로그래밍 언어에 임베디드 시켜 사용이 가능하다.
데이터 조작어에는 SELECT, INSERT, UPDATE, DELETE가 있다. -
데이터 제어어(DCL : Data Cintrol Language)
데이터 제어어는 사용자의 권한을 설정할 때 사용되는 명령어다.
데이터 제어어는 GRANT, REVOKE이 있다.
세 분류 중 데이터 조작어(DML)을 가장 많이 사용할 것이다.(데이터베이스를 조작하는 직무가 아닌 이상 DDL, DCL을 사용할 일은 거의 없다.)
2-3. 데이터 독립성★★★
1) 3단계 데이터베이스 구조(ANSI/SPARC 아키텍처)
DB는 3단계 구조를 가지고 있다. 내부스키마, 개념스키마, 외부스키마가 그것이다.
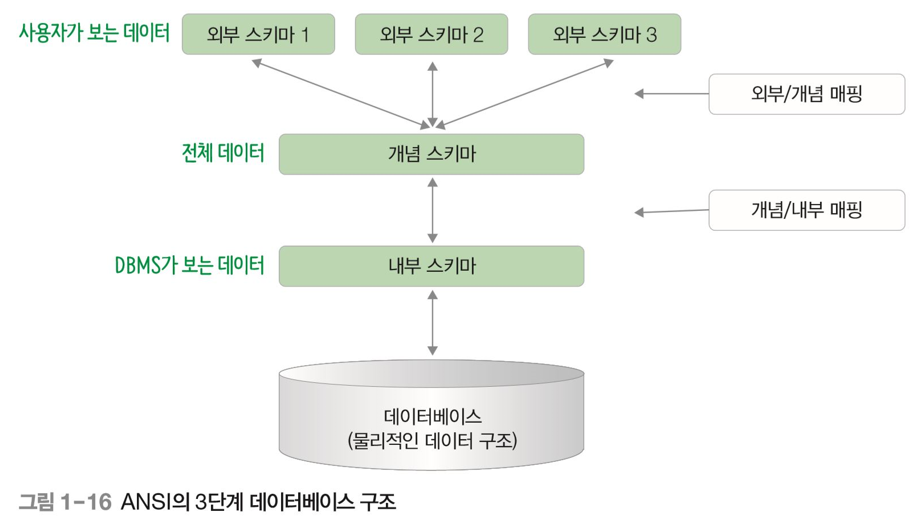 출처 : 오라클로 배우는 데이터베이스 개론과 실습
출처 : 오라클로 배우는 데이터베이스 개론과 실습
-
내부 스키마
물리적 저장 장치에 DB가 실제로 저장되는 방법을 정의한 단계이다. 인덱스, 데이터 레코드 배치 방법 등에 대한 사함 포함되어있다. -
개념 스키마
DB 전체를 정의한 단계이다. DB별로 하나만 존재한다. 전체 데이터를 다루긴 하지만, 데이터가 물리적으로 어떻게 저장되어있는지는 관여하지 않는다. -
외부 스키마
사용자가 접근하는 단계이다. 전체 데이터가 아닌 사용자 권한과 업무에 따라 제한된 데이터만 조회할 수 있다. 뷰(view)의 개념으로 여러 개의 외부 스키마가 동시에 존재할 수 있다.
3단계 구조를 아파트에 빗대어 설명하면 이해가 쉽다.
내부 스키마는 건설 회사다. 수도관은 어떻게 배치되어 있는지, 각 가정에 전기는 어떻게 공급 되어야 하는지 등을 다룬다.(데이터가 저장되는 방법을 현실적으로 제시)
개념 스키마는 관리사무소다. 아파트 단지를 깨끗하게 관리하고 각 가정에 문제가 생기면(사용자가 작업을 요청하면) 대신 처리를 해준다.
외부 스키마는 입주민이다. 입주민은 아파트가 어떻게 지어졌는지, 어떻게 관리되는지는 크게 관심 없고 오로지 자신의 집만 보거나 사용할 수 있다.
위와 같이 하나의 아파트(=데이터베이스)에도 세 부류의 관계자가 있고(=3단계 구조) 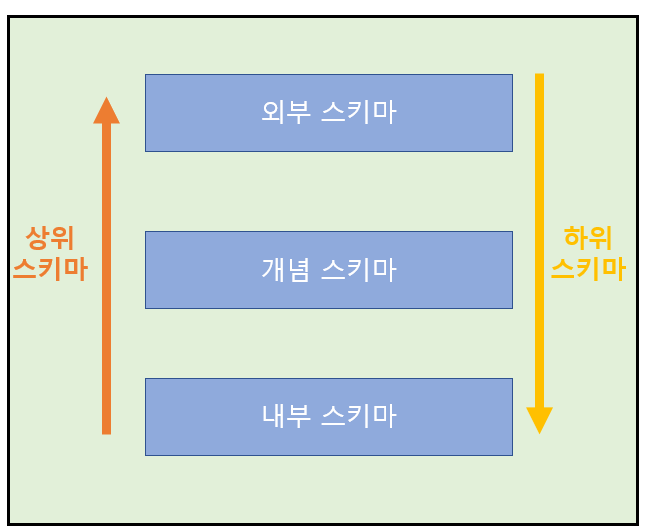
2) 데이터 독립성
DB는 3단계 구조를 가지고 있고 각 단계마다 관여하는 정보가 다르며 서로 관여하지 않는다. DBMS는 세 단계 간의 사상(=매핑)을 진행한다.
- 외부/개념 사상 : 외부 스키마에서 사용자가 어떤 동작을 요청하면(주로 데이터 조회) 개념 스키마에서 어떤 부분이 해당되는지 대응시킨다.
- 개념/내부 사상 : 개념 스키마의 데이터를 물리적으로 어디어 어떻게 저장할지 대응시킨다.
데이터 독립성이란 하위 스키마의 변경이 상위 스키마에 영향을 주지 않게 처리하는 것을 의미한다.(다만, 상위 스키마의 변경은 하위 스키마에 영향을 줄 수도 있다.) 데이터 독립성은 두 가지로 나뉜다.
-
논리적 데이터 독립성
개념 스키마의 변경이 외부 스키마에 영향을 미치지 않도록 하는 조건이다. 예를 들어 새로운 릴레이션이 개념 스키마에 생성된 경우, 기존 외부 스키마들은 변동이 없어야 한다.
다만, 반대는 성립 될 수 있는데, 하나의 외부 스키마에서 어트리뷰트를 추가한 경우 그 어트리뷰트는 개념 스키마에도 추가 되어야 하기 때문이다. -
물리적 데이터 독립성
내부 스키마의 변경이 개념 스키마에 영향을 미치지 않도록 하는 조건이다. 예를 들어 한 릴레이션에 인덱스를 변경한 경우, 데이터 구조 자체에는 변동이 없어야 한다.
다만, 반대는 성립 될 수 있는데, 개념 스키마에서 새로운 릴레이션이 추가된 경우 물리적 저장장치에도 저장이 되어야 하기 떄문이다.
