[FSRCNN] Accelerating the Super-Resolution Convolutional Neural Network 논문 리뷰 & 코드 구현
Acceleration
이번에 대학교 종합설계프로젝트 주제로 FPGA에 AI 가속기를 구현하는 것을 하게 되었습니다. 더 구체적으로는 Super-Resolution, 즉 이미지의 화질을 개선시키는 AI 모델을 가속시키기로 결정했기 때문에 관련 모델들을 찾아보고 있었는데요, FPGA의 성능이 넉넉하지 않기 때문에 경량화된 모델들로 찾아보던 중 ECCV 2016에 발표된 FSRCNN이라는 논문을 찾게되어 해당 논문을 공부해볼겸 리뷰해보도록 하겠습니다.
최근 Super-Resolution 논문들은 Diffusion Model 같은 생성형 모델을 사용하여 훨씬 강력한 성능을 뽐내지만, FPGA에는 무거운 최근 모델들은 올리기 어렵기 때문에 가벼운 CNN 네트워크 위주의 모델들을 올려주어야 합니다.
따라서 이 논문은 전통적인 CNN 구조를 사용한 논문이라 컴퓨터 비전 분야에 관심이 있으신 분이라면 어렵지 않게 따라오실 수 있을 것이라 생각합니다 :)
📌 Paper Reference : https://arxiv.org/abs/1608.00367
Introduction
 Image super-resolution task라고 한다면, 기본적으로 Low-Resolution(LR) 이미지를 High-Resolution(HR)으로 Recover 시켜주는 것을 말합니다. 예를 들면, 1900년대에 찍은 저화질 사진들을 고화질로 복원해주는 프로젝트 같은 것이지요.
Image super-resolution task라고 한다면, 기본적으로 Low-Resolution(LR) 이미지를 High-Resolution(HR)으로 Recover 시켜주는 것을 말합니다. 예를 들면, 1900년대에 찍은 저화질 사진들을 고화질로 복원해주는 프로젝트 같은 것이지요.
FSRCNN이 나오기 전, SRCNN이라는 SR 모델이 간단한 모델 아키텍처와 좋은 복원 성능을 앞세워서 주목 받고 있었는데요, 타 모델 대비 빠르긴 했지만 여전히 큰 이미지에 대해서는 만족스럽지 못한 processing speed를 가지고 있었습니다. 예를 들면 240 x 240 이미지를 3 factor에 대해 upsample을 시켜준다고 하면, 1.32fps의 속도가 나왔는데, 이 속도는 real-time 처리를 위해 기대되는 속도(24 fps)에 비하면 한참 떨어지는 속도입니다.
퍼포먼스를 유지시키면서 real-time 처리가 가능하게 하기 위해서는 무려 17배의 속도 개선을 해내야했죠. 단순히 파라미터의 수를 줄이면서 가속을 시도한다면 분명 퍼포먼스에 심각한 악영향을 끼칠 것인데, 이 것을 해결할 수 있는 방법이 있을까요?
저자들은 기본적인 SRCNN 아키텍처에 내재하는 두개의 limitation을 발견했다고 주장합니다.
Two inherent limitations of SRCNN Architecture
-
Pre-processing 단계에서, SRCNN은 original LR 이미지를 bicubic interpolation으로 원하는 사이즈만큼 Upsample을 해준 뒤, input으로서 모델에 입력해줌
- Computation complexity가 quadratically 하게 증가한다는 단점 존재❓ Bicubic Interpolation
픽셀 Interpolation 방법론 중 하나로, 주변의 16개 픽셀(4x4) 값을 이용하여 새로운 픽셀 값을 계산하는 방식입니다. 1차원에서의 cubic interpolation을 2차원으로 확장한 형태죠.아래의 수식을 통해 계산을 진행하며,최종적으로 보간하려는 픽셀의 위치를 나타내는 , 좌표에 이 계수를 이용해 값을 계산합니다

-
Input 이미지 patch가 고차원의 LR feature space로 project되고, 복잡한 mapping을 거쳐서 고차원의 HR feature space로 이동함.
- 넓은 mapping layer를 적용해줄수록 mapping 정확도가 향상되는데, 그만큼 비용이 증가함. 따라서 정확도를 유지시키면서 네트워크 스케일을 줄여주면 비용을 확실하게 절감시킬 수 있는데, 그런 방법은 없을까?
Solution(New Architecture)
-
Bicubic interpolation으로 인해 발생하는 계산량을 감소시키기 위해, Bicubic interpolation을 deconvolution layer로 대체.
- 오직 원본 LR 이미지의 spatial size에 비례하게 computational complexity를 조정해주기 위해, deconvolution layer를 네트워크의 끝단에 위치
-
Mapping을 저차원의 feature space에서 일어나도록 제한시키기 위해, shrinking layer와 expanding layer를 mapping layer의 시작과 끝에 각각 더해줌
- 추가적으로, 하나의 single wide mapping layer를 filter size 3 x 3을 가지는 몇 개의 layer들로 분해.
결국, 위의 방법들을 적용해서 새로운 Architecture을 구성하면, 최종적인 전체 Architecture 형태는 모래시계 모양이 됩니다. 시작할 때는 고차원에서 저차원으로 가다가, 중간을 지난 이후로부터는 다시 저차원에서 고차원으로 space가 커질 것이기 때문입니다.
Fast Super-Resolution by CNN
저자들이 제안한 새로운 네트워크인 FSRCNN에 대해 더 자세히 알아보기 전에, 기본적인 구조였던 SRCNN부터 간략하게 살펴보고 FSRCNN에 대해 deep dive 해보도록 하겠습니다.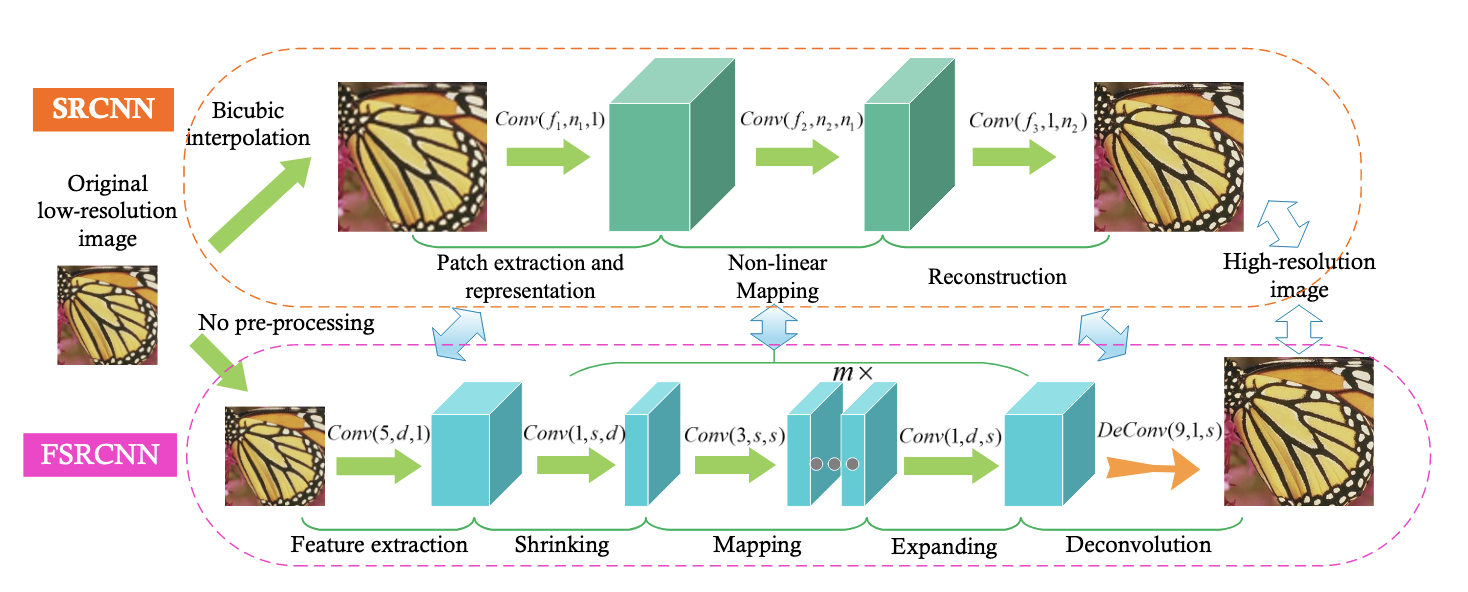
SRCNN
SRCNN은 bicubic-interpolated LR image 와 HR image 간의 end-to-end mapping function 를 학습시키는 모델입니다.
전체적인 모델은 세가지 파트로 구성되는데요,
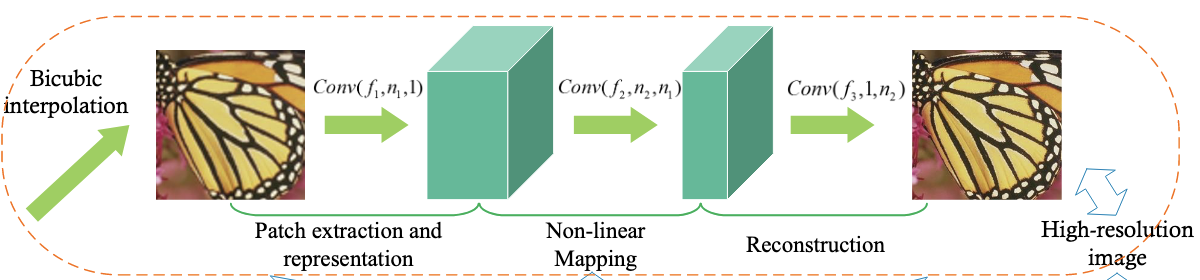
- Patch extraction and representation part
- Input으로부터 patch를 추출하고 각 patch를 고차원의 feature vector로 나타내는 첫번째 layer - Non-linear mapping part
- Feature vector를 HR feature vector space로 non-linearly하게 mapping 해주는 중간 layer - Reconstruction part
- 최종적인 output image를 형성하기 위해 HR feature들 합치는 최종 layer
그리고 네트워크의 computation complexity는 다음과 같이 계산할 수 있습니다
여기서 각 는 세 layer의 filter size를 의미하고, 각 는 세 layer의 filter number을 의미합니다. 그리고 은 HR 이미지의 사이즈구요.
저자들은 middle layer, 즉 Non-linear mapping part가 전체 네트워크 파라미터 중 가장 큰 영향을 끼친다고 말합니다. 또한 complexity가 HR image의 사이즈에 비례하는 것을 관찰했다고 하죠.
따라서 FSRCNN은 위 두개의 factor에 집중해서 네트워크를 개선시켰습니다. 이제 FSRCNN에 대해서 자세히 알아보도록 하죠!
FSRCNN
FSRCNN은 3가지 파트로 나뉘는 SRCNN과 달리, 5가지 part로 분해됩니다.
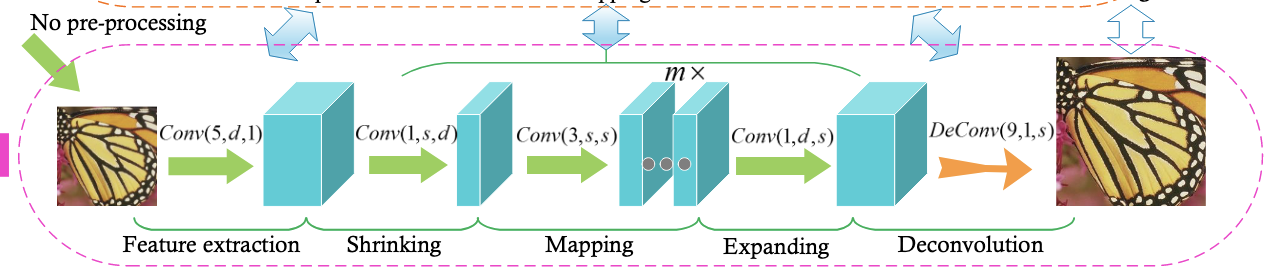
- Feature extraction
- Shrinking
- Mapping
- Expanding
- Deconvolution
이 때, 첫번째 4개의 part는 convolution layer고, 마지막 layer만 deconvolution layer입니다. 여기서는 convolution layer을 로, deconvolution layer를 로 표기하고, 각 는 filter size, number of filters, 그리고 number of channels를 표기해줄 것입니다.
Feature Extraction
SRCNN의 첫번째 파트와 비슷하지만, FSRCNN에서는 interpolation(bicubic) 없이 original LR image에서 바로 feature extraction을 수행해줍니다.
기존의 SRCNN은 upscale된 이미지에 대해 filter을 적용해줬는데, 이때 filter size는 9였습니다. 그러나 FSRCNN은 upscale이 안된 이미지에 대해 filter을 적용하므로 더 작은 filter size를 사용해도 충분히 모든 정보를 커버할 수 있습니다. 따라서 5 x 5짜리 filter을 사용해줍니다.
그리고 channel size는 SRCNN은 따라 1을 사용하며, filter 개수는 미지수 d로 둔 뒤, 최종적으로 을 Feature Extraction 파트에서 사용합니다.
이 때, 는 LR feature dimension의 개수로 여겨질 수 있는데요, 이 factor는 조금만 변경되어도 전체적인 performance에 큰 영향을 주는 sensitive variable입니다. 따라서 여기서는 아직 assign을 안해주고, 차후에 assign해줄 수 있도록 로 남겨준 것입니다.
Shrinking
원래라면 feature extraction이 된 후, 바로 HR feature dimension으로 mapping을 적용해주는데요, LR feature dimension 가 매우 크다는 단점이 있습니다.
이렇게 되면 computation complexity가 매우 높아지게 되죠(위의 SRCNN의 computation complexity 식에서 두번이나 사용되는 것만 봐도 알 수 있습니다) 따라서 이렇게 큰 dimension을 줄여주기 위해, mapping 전에 shrinking을 적용해줍니다.
필터 사이즈()를 1로 고정하여 filter를 LR Feature에 대해 선형 변환(linear combination)을 수행하도록 하고, 의 작은 filter number를 적용해서 LR feature dimension을 로부터 로 줄여줍니다.
❓ 1x1 convolution
channel 수를 일반적인 convolution 대비 아주 효율적으로 조절(적은 파라미터 수)하고, 계산량을 줄이고, 비선형성을 추가시킬 때 사용하는 convolution 방법론입니다. Linear combination과의 관계를 생각해보면,
- 1x1 convolution 연산은 공간 차원(너비, 높이)에서의 필터 크기가 1x1이므로, 공간적 정보는 전혀 섞지 않고 오직 채널 차원(channel dimension)에서만 선형 결합(linear combination)을 수행합니다.
- 입력 채널이 여러 개 있을 때, 각 픽셀마다 입력 채널 값들을 가중치(weight)와 곱하여 합산(sum)한 뒤, bias를 더하는 과정이 이루어집니다. 이것이 수학적으로는 정확히 linear combination과 같죠.
- 따라서, 1x1 convolution은 채널 축에서의 차원 축소(dimension reduction), Feature 채널 간의 선형적인 결합을 통해 새로운 특징(feature)을 생성하거나 채널 수를 조정하는 데 주로 활용됩니다.
Reference : 대학원생이 쉽게 설명해보기 님 블로그
결국 최종적으로 Shrinking Layer에서는 를 사용하게 됩니다. 이 전략은 전체적인 parameter의 수를 정말 많이 줄여주죠!
Non-linear Mapping
이 Mapping 단계는 SR performance에 가장 큰 영향을 미치는, 제일 중요한 파트로 여겨집니다. 특히 가장 중요한 factor는, mapping layer의 width(layer 안의 filter 개수)와 depth(layer 개수)죠.
SRCNN에서는 5x5 layer가 1x1 layer보다 더 좋은 결과를 낸다고 보고된 바 있지만, 저자들은 성능과 네트워크 scale 간의 trade-off를 조절하기 위해 중간 사이즈인 3x3 필터를 FSRCNN에 적용합니다(). 그리고 성능을 유지시키기 위해, 여러 개의 3x3 layer를 사용해줍니다
layer의 개수(depth)는 정확도와 복잡도를 결정짓는 아주 민감한 factor기 때문에, m이라는 미지수로 두고, 일관성을 위해 모든 mapping layer가 같은 filter 개수를 가지도록 해줍니다()
결국, 최종적으로 Non-linear mapping에서는 를 사용하게 됩니다.
Expanding
Expanding layer는 Shrinking layer의 inverse process로 보면 편합니다. feature dimension을 저차원으로 줄였으니, 더 나은 복원 퀄리티를 위해 고차원으로 키워주는 작업이 필요한 것이죠.
Shrinking layer와 마찬가지로 1 x 1 filter를 적용해주고, shrinking layer와 반대로 를 사용해줍니다. 만약 이 layer가 없다면, 성능 저하가 발생하는 것을 실험적으로 확인했다고 저자들은 말합니다.
Deconvolution
전체 Network의 마지막 파트입니다! deconvolution filter의 집합을 이용해서 feature들을 모으고 upsample을 진행하죠.
deconvolution은 이름에서 나타나는 바와 같이 convolution의 역연산이라고 여길 수 있습니다.
⚒️ 2D convolution formula
위의 식은 2D convolution을 적용했을 때 Output의 shape를 나타낸 공식입니다. 보면 output의 shape가 stride 값에 대해 정확히 반비례하는 관계인 것을 알 수 있죠. 다시 말해, stride가 2면, output은 input에 대해 1/2의 크기를 지니게 됩니다.여기서 input과 output의 관계를 뒤바꾼 연산이 deconvolution 입니다. 이 경우에는 stride가 2라면, output은 input에 대해 2배의 크기를 가지게 되죠.
Reference : Pytorch 공식 문서(Conv2d)

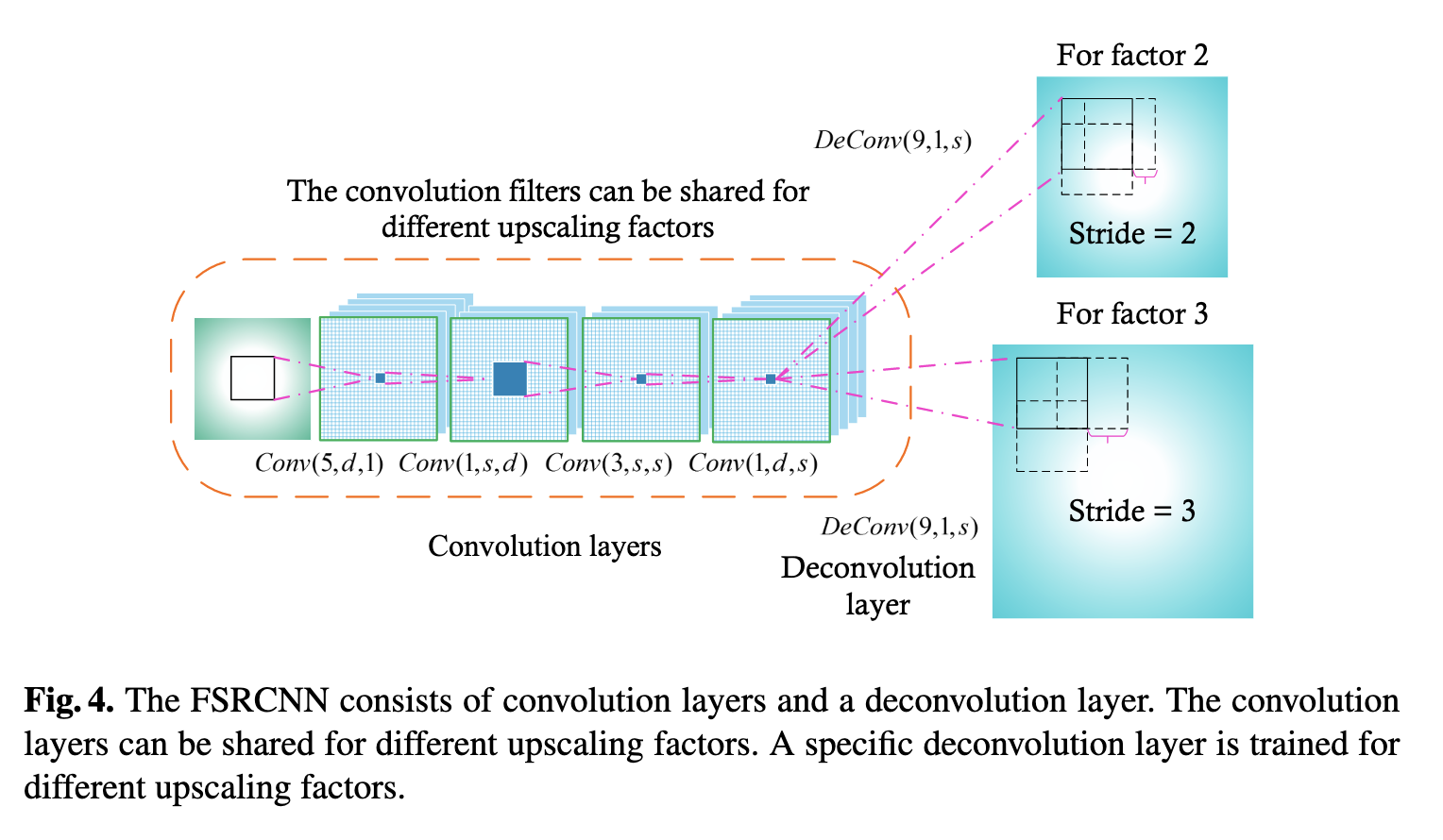 위에서 언급한 바와 같이, stride의 크기만큼 output의 크기를 키우는 deconvolution 연산 공식에 따라, 여기서는 desired upscaling factor()을 stride()와 같은 값으로 설정해줍니다. 이렇게 되면 원하는 upscaling 정도를 조절할 수 있게 되겠죠! ()
위에서 언급한 바와 같이, stride의 크기만큼 output의 크기를 키우는 deconvolution 연산 공식에 따라, 여기서는 desired upscaling factor()을 stride()와 같은 값으로 설정해줍니다. 이렇게 되면 원하는 upscaling 정도를 조절할 수 있게 되겠죠! ()
Fig.4 에서 설명하는 것처럼 upscaling factor를 2로 설정하고 싶다면 stride를 2로 주고, upscaling factor를 3으로 설정하고 싶다면 stride를 3으로 설정해주는 것을 확인해줄 수 있습니다. 결국 deconvolution layer는 각기 다른 upscaling factor에 대해 학습될 수 있죠!
최종적으로 사용되는 Deconvolution layer는, stride 과 함께, filter size 9를 사용하여, 를 사용합니다.
지금까지 FSRCNN 네트워크의 가장 큰 부분들을 차지하는 5개의 파트를 자세히 알아보았는데요. 실제 네트워크에는 학습과 동작을 위해 activation function과 loss function과 같은 요소들을 설정해주는 것이 꼭 필요합니다. 따라서 어떤 function을 썼는지 알아보고, 최종적으로 전체 network의 구조를 정리해보도록 하겠습니다.
Activation function - PReLU
각 convolution layer에 대해, FSRCNN은 일반적인 ReLU를 activation function으로 쓰는 대신, Parametric Rectified Linear Unit(PReLU)를 사용하는 것을 제안합니다.
두 function 간의 차이는 음수 부분의 계수에 있죠. 일반적으로 두 function은 다음의 식으로 쓸 수 있습니다.
이때 는 -th channel의 input signal이고, 가 음수 부분의 계수입니다.
- ReLU : 고정
- PReLU : 가 학습 가능한 변수
📌 Visualization of ReLU & PReLU
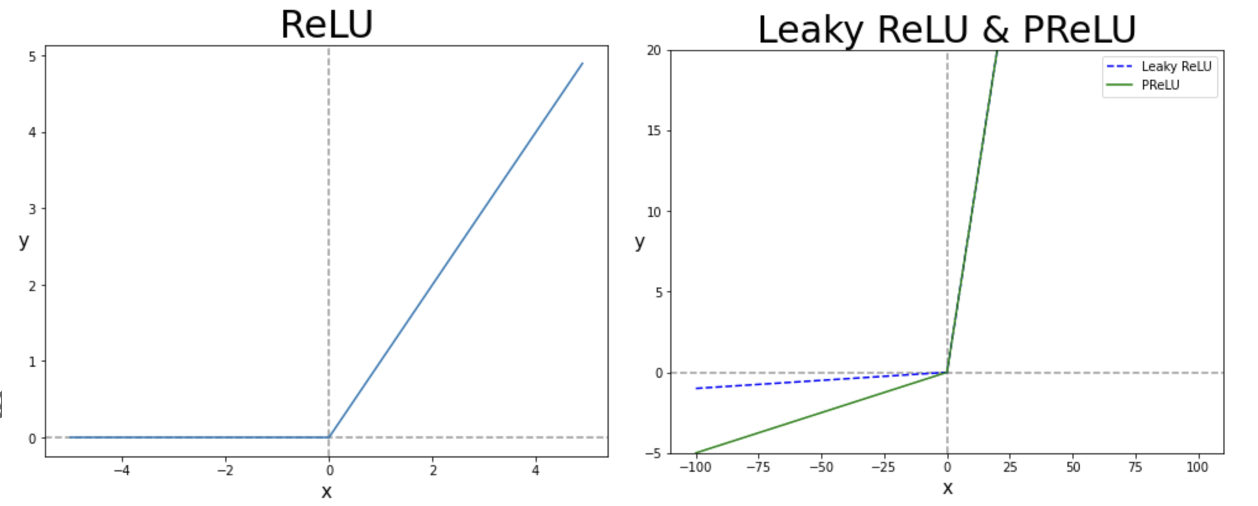
Reference : 만년필잉크님 블로그
PReLU를 사용하면, ReLU의 zero gradient로 인해 발생하는 "dead features" 회피할 수 있기 때문에 저자들은 PReLU를 선택했다고 말합니다. 실제로 실험을 해보니 PReLU를 사용하는 것이 훨씬 안정적인 것을 확인할 수 있었죠.
Loss Function(Cost Function)
SRCNN과 마찬가지로 MSE(Mean Square Error)을 loss function으로서 FSRCNN에 사용해줍니다.
- : -th LR, HR sub-image pair in the training data
- : network output for with parameters
Overall Structure of FSRCNN
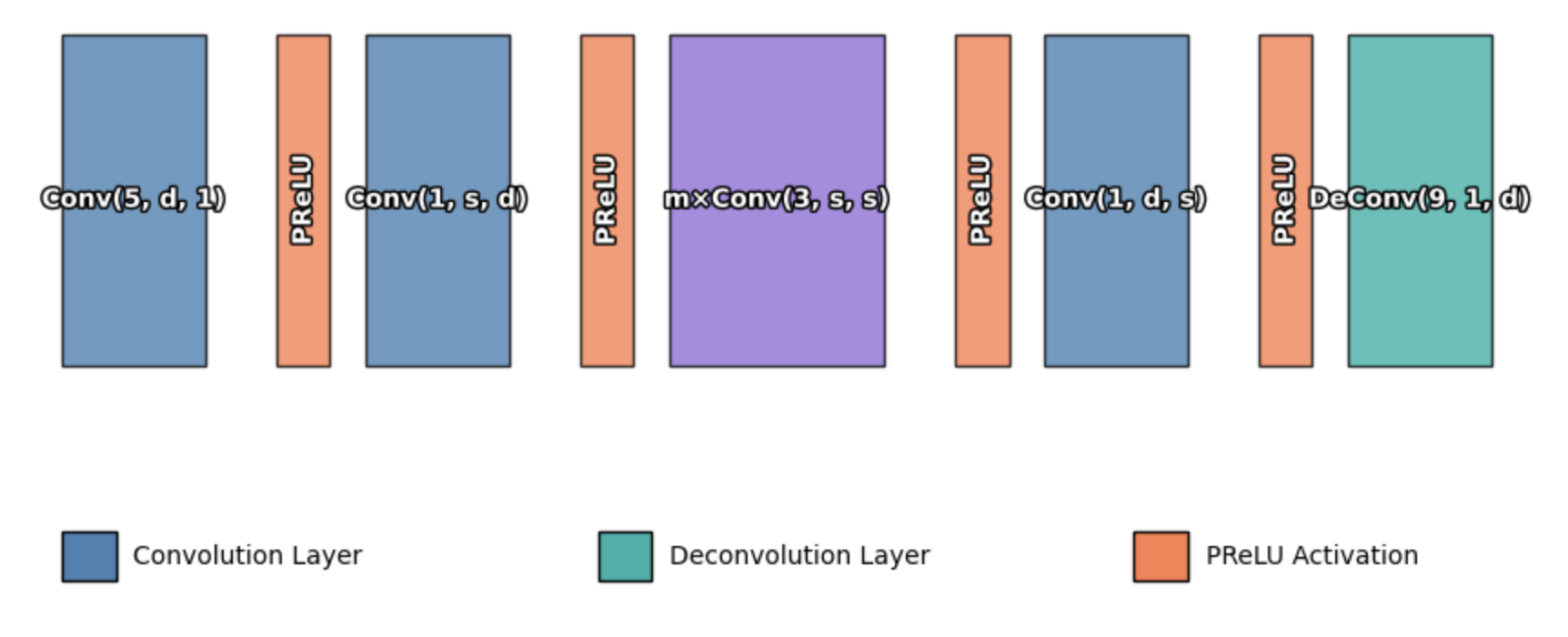
위에서 설명한 5개의 파트와 activation function(PReLU)를 적용하여, 완전한 FSRCNN 구조를 완성해보았습니다. 실제로 네트워크를 동작시킬 때는, 3개의 sensitive variables만 잘 결정해주면 되죠()
따라서 보다 간단하게 이 network를 일컫기 위해, 으로 네트워크를 나타낸다고 저자들은 말합니다.
그리고 최종적으로 computational complexity는 다음과 같이 계산될 수 있죠.
참고로 PReLU 파라미터들은 전체 계산량에서 무시해도 되는 수준이기 때문에 위의 식에서 생략되었습니다.
Differences against SRCNN : From SRCNN to FSRCNN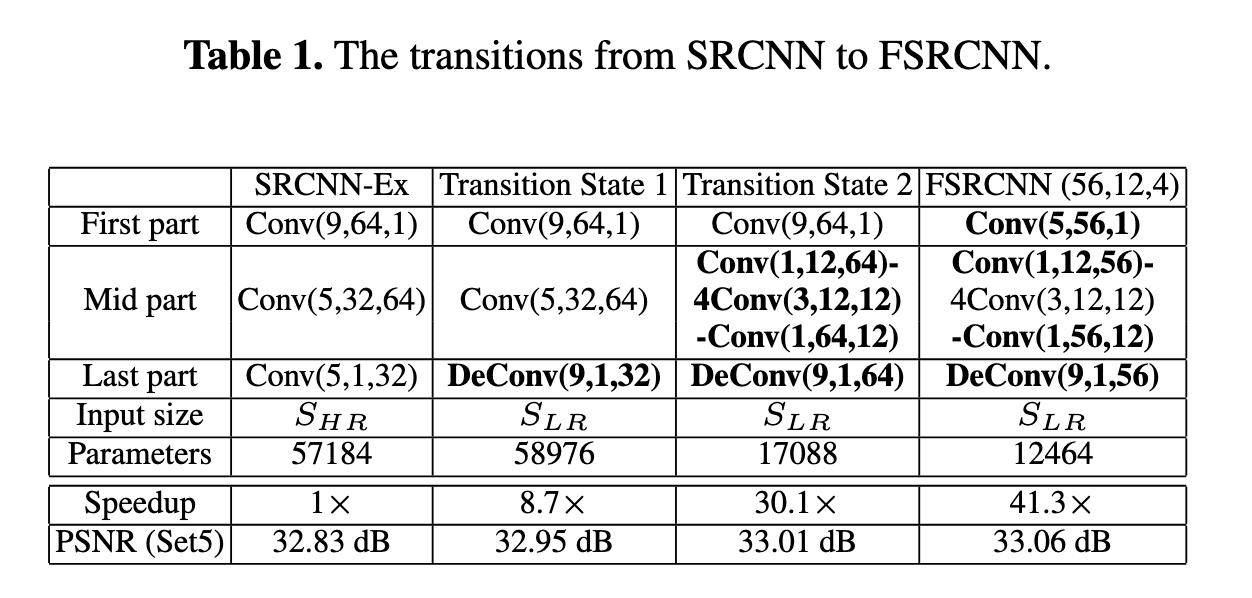
실제로 SRCNN에 비해 FSRCNN은 속도와 성능 면에서 어떻게 변화되었을까요?
위의 표는 기본적인 SRCNN으로부터 차례차례 한 부분씩 바꿔가며, 최종적으로 FSRCNN의 구조에 도달했을 때까지의 각 구성요소와 성능 및 속도를 알려줍니다.
- Transition State 1 : Last part를 Deconvolution 연산으로 변경
✔️ 네트워크의 크기는 소량 키우지만, 8.7배의 속도 개선
- Transition State 2 : Mid part를 하나의 wide layer 대신 여러 개의 narrow layer들로 변경(shrink - 4 mapping layer - expanding)
✔️ 전체적으로 레이어 개수는 늘었지만, 파라미터 수는 약 3.4배 감소
✔️ 가속이 무려 30.1배나 됨!
✔️ 여러 개의 "narrow" layer가 하나의 "wide" layer 보다 더 적은 파라미터 사용 및 좋은 성능을 달성 - Last transition : 더 작은 filter size와 더 적은 filter 개수 사용( ->
✔️ 41.3배의 가속 달성
중요한 것은, 전체 네트워크의 파라미터 수는 줄고, 속도는 41.3배 빨라졌는데, 성능 또한 개선이 되었다는 것 입니다.
Experiments
- Training Data : SR task에 자주 사용되는 91-image dataset과 자체적으로 구축한 General-100 image를 이용
- Scaling, Rotation 등 Augmentation 진행 - Test Data : Set5, Set14, BSD200 사용
Training samples
- 원하는 scaling factor 으로 original training image를 downsample
- 위에서 얻은 LR 이미지를 크기의 서브 이미지 집합으로 crop
- HR 이미지 또한 crop 해주고, LR/HR sub-image pair을 획득
Training Strategy
- 먼저 91-image dataset으로 network training
- Learning Rate(lr) : convolution - 0.001 / deconvolution - 0.0001 - training이 saturation되면, general-100 dataset으로 fine-tuning
- Learning Rate(lr) fine-tuning : 모든 layer에 대해 half
Sensitive Variables Setting
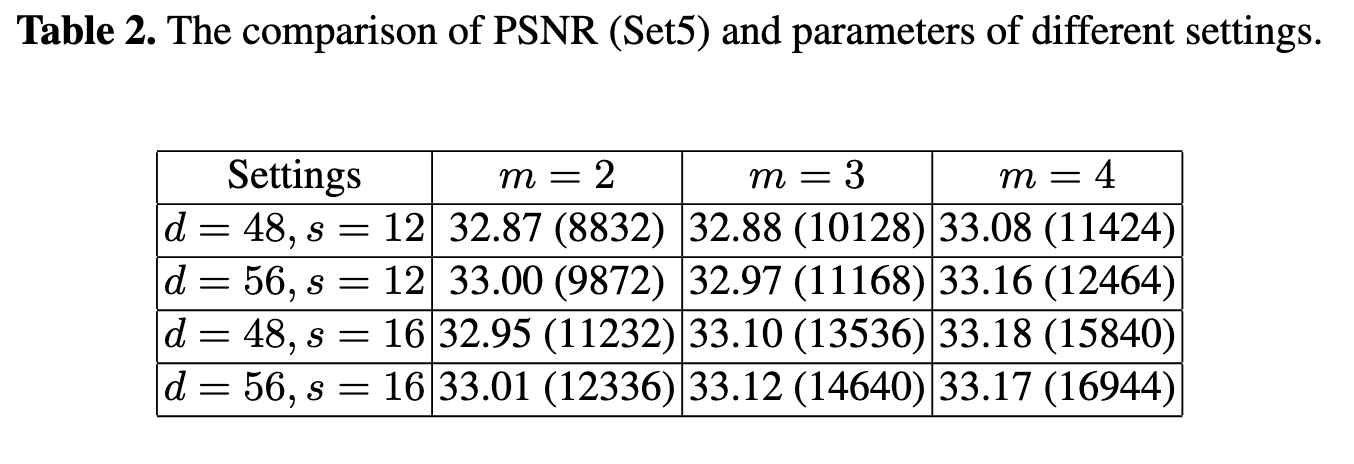
위의 표는 Sensitive Variables인 을 조절했을 때 결과값으로 나타난 PSNR 값입니다. 저자들은 performance와 parameter 간의 trade-off를 다 따져보았을 때, 일 때가 최적이라고 주장하죠.
즉, FSRCNN(56,12,4) 입니다. 다만 가장 작은 네트워크인 FSRCNN(48,12,2) 또한 SRCNN보다 훨씬 빠르고(약 58배), 적은 파라미터로 좋은 결과를 냈기 때문에, 이 네트워크 자체가 굉장히 유의미하다고 볼 수 있습니다.
Different Upscaling Factors
FSRCNN은 유연하게 Upscaling을 조절할 수 있는 네트워크입니다. 기본적으로 Upscaling factor 3으로 학습을 시키고, 다른 upscaling factor에 대해서는 fine-tuning으로만 학습을 진행합니다.
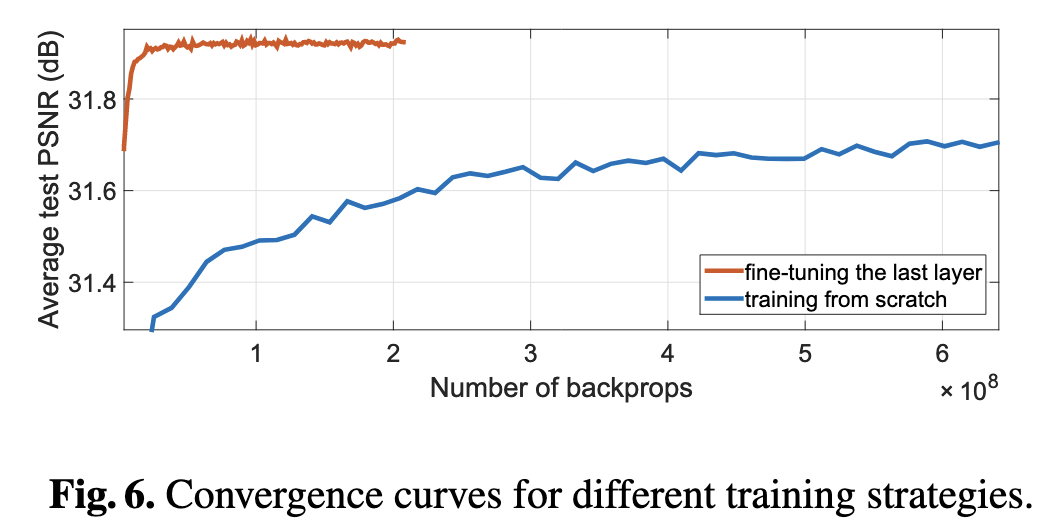
그것도, 오직 deconvolution layer에 대해서만 fine-tuning을 진행하면 되죠! 위의 그래프에서 보이는 것처럼, scratch부터 다시 학습을 시키는 것보다, last-layer만 fine-tuning 시키는 것이 훨씬 효율적으로 학습이 잘 됩니다.
따라서 x3 factor로 기본 학습을 시켜주고, x2와 x4에 대해서는 last layer만 fine-tuning 시켜줍니다!
Results
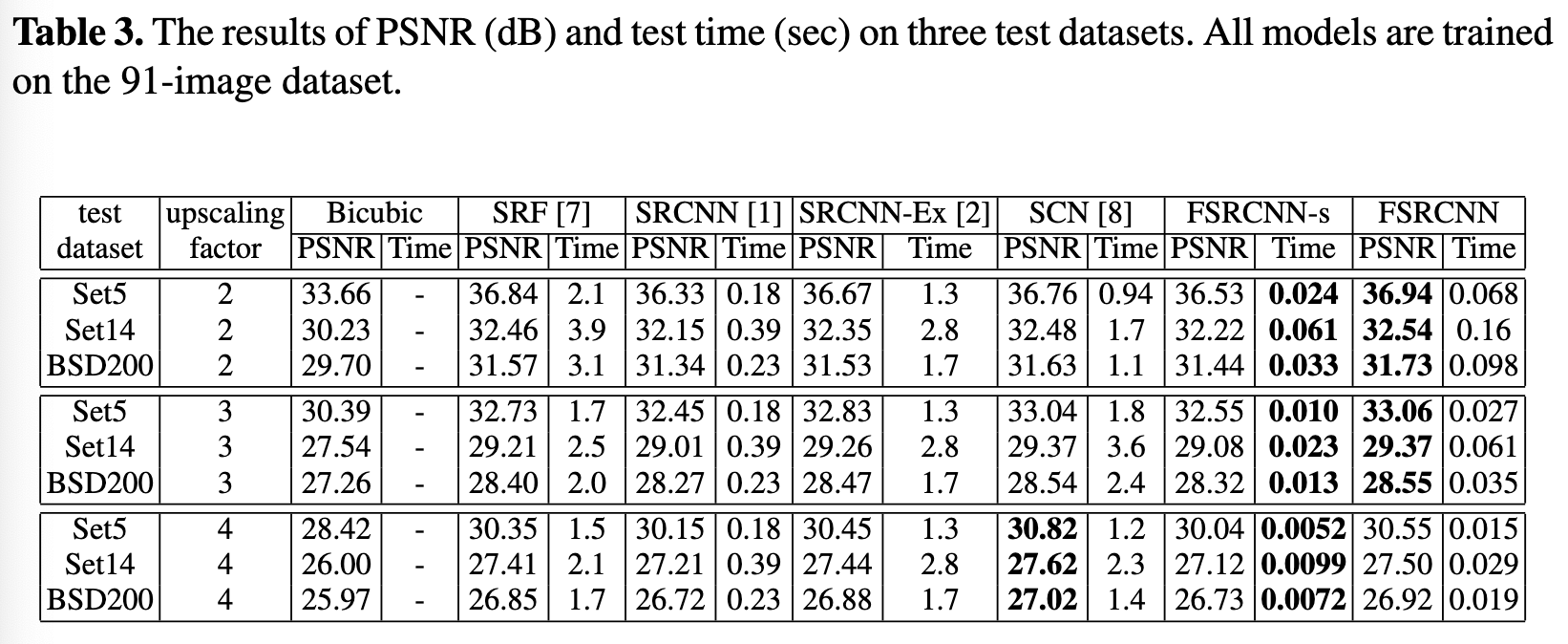
위의 표에서 보이는 것과 같이, FSRCNN이 다른 모델 대비, 성능(psnr)과 가속 면에서 압도적인 성과를 낸 것을 확인할 수가 있습니다.
Code
FSRCNN Architecture
import torch
import torch.nn as nn
class FSRCNN(nn.Module):
def __init__(self, scale_factor = 3, num_channels, d=56, s=12, m=4):
super(FSRCNN, self).__init__()
# Conv(5,d,1)
self.conv_first = nn.Sequential(
nn.Conv2d(num_channels, d, kernel_size=5, padding=5//2),
nn.PReLU(d)
)
# Conv(1,s,d)
self.conv_shrink = nn.Sequential(
nn.Conv2d(d, s, kernel_size=1),
nn.PReLU(s)
)
# Conv(3,s,s) * m
self.conv_mapping = nn.Sequential(
*[nn.Conv2d(s, s, kernel_size=3, padding=3//2) for _ in range(m)],
nn.PReLU(s)
)
# Conv(1,d,s)
self.conv_expanding = nn.Sequential(
nn.Conv2d(s, d, kernel_size=1),
nn.PReLU(d)
)
# DeConv(9,1,d)
self.deconv = nn.ConvTranspose2d(d, num_channels, kernel_size=9, stride=scale_factor, padding=9//2, output_padding=scale_factor-1)
def forward(self, x):
x = self.conv_first(x)
x = self.conv_shrink(x)
x = self.conv_mapping(x)
x = self.conv_expanding(x)
x = self.deconv(x)
return x
Dataset
- Training Dataset으로는 T91과 General-100 dataset 사용
- Scaling + Rotation 을 이용해서 Augumentation 진행
- 원본 포함 20개의 조합이 나올 수 있음(scaling 5개 / rotation 4개)
import os
import random
from PIL import Image
import torch
from torch.utils.data import Dataset
import torchvision.transforms as transforms
import torchvision.transforms.functional as TF
class SRDataset(Dataset):
def __init__(self, image_dir, patch_size, scale_factor, augment=True):
"""
augment=True인 경우, 각 이미지에 대해 원본 + 미리 정의된 증강 조합을 모두 적용.
스케일: [1.0, 0.9, 0.8, 0.7, 0.6], 회전: [0, 90, 180, 270] → 총 20 조합 중 (1.0,0°)는 원본이므로 추가 19개
"""
super(SRDataset, self).__init__()
# general-100 + T91 dataset image_path 모두 가져오기
self.image_paths = [
os.path.join(image_dir, x)
for x in os.listdir(image_dir)
if x.lower().endswith(('.png', '.jpg', '.jpeg'))
] # total size : 191
self.patch_size = patch_size # LR 패치 크기
self.scale_factor = scale_factor
self.hr_patch_size = patch_size * scale_factor # HR 패치 크기
self.augment = augment
# 증강 조합 정의: 원본 포함해서 총 20 조합, 단 (1.0, 0°)는 원본으로 처리
self.scale_aug_factors = [1.0, 0.9, 0.8, 0.7, 0.6]
self.rotation_angles = [0, 90, 180, 270]
self.aug_combinations = [] # (scale, rotation) 조합 (원본은 따로 처리)
if self.augment:
for s in self.scale_aug_factors:
for r in self.rotation_angles:
# (1.0, 0°)는 원본
if s == 1.0 and r == 0:
continue
self.aug_combinations.append((s, r))
self.to_tensor = transforms.ToTensor()
def __len__(self):
# 원본 이미지 + 증강 조합 개수 만큼 확장
if self.augment:
return len(self.image_paths) * (1 + len(self.aug_combinations)) # 191 * (1 + 19)
else:
return len(self.image_paths)
def __getitem__(self, idx):
if self.augment:
# 각 이미지에 대해 (원본 + 증강) 순서대로 할당
base_idx = idx // (1 + len(self.aug_combinations)) # idx // 20
aug_idx = idx % (1 + len(self.aug_combinations)) # idx % 20
else:
base_idx = idx
aug_idx = 0
hr_image = Image.open(self.image_paths[base_idx]).convert('RGB')
# 증강 적용: aug_idx == 0이면 원본, 그 외는 해당 조합 적용
if self.augment and aug_idx != 0:
scale_aug, angle = self.aug_combinations[aug_idx - 1]
# 스케일 증강 (1.0이면 변경 없음)
if scale_aug != 1.0:
new_w = int(hr_image.width * scale_aug)
new_h = int(hr_image.height * scale_aug)
hr_image = hr_image.resize((new_w, new_h), Image.BICUBIC)
# 회전 증강 (0도이면 변경 없음)
if angle != 0:
hr_image = hr_image.rotate(angle, expand=True)
# HR 이미지로부터 LR 이미지 생성 (bicubic interpolation)
lr_w = hr_image.width // self.scale_factor
lr_h = hr_image.height // self.scale_factor
lr_image = hr_image.resize((lr_w, lr_h), Image.BICUBIC)
# 랜덤 crop (혹은 고정 crop)을 적용하여 LR/HR 패치 쌍 추출
if lr_w < self.patch_size or lr_h < self.patch_size:
hr_image = hr_image.resize((self.hr_patch_size, self.hr_patch_size), Image.BICUBIC)
lr_image = hr_image.resize((self.patch_size, self.patch_size), Image.BICUBIC)
else:
x = random.randint(0, lr_w - self.patch_size)
y = random.randint(0, lr_h - self.patch_size)
lr_patch = lr_image.crop((x, y, x + self.patch_size, y + self.patch_size))
hr_x = x * self.scale_factor
hr_y = y * self.scale_factor
hr_patch = hr_image.crop((hr_x, hr_y, hr_x + self.hr_patch_size, hr_y + self.hr_patch_size))
lr_image = lr_patch
hr_image = hr_patch
lr_tensor = self.to_tensor(lr_image)
hr_tensor = self.to_tensor(hr_image)
return lr_tensor, hr_tensor
Results
Loss
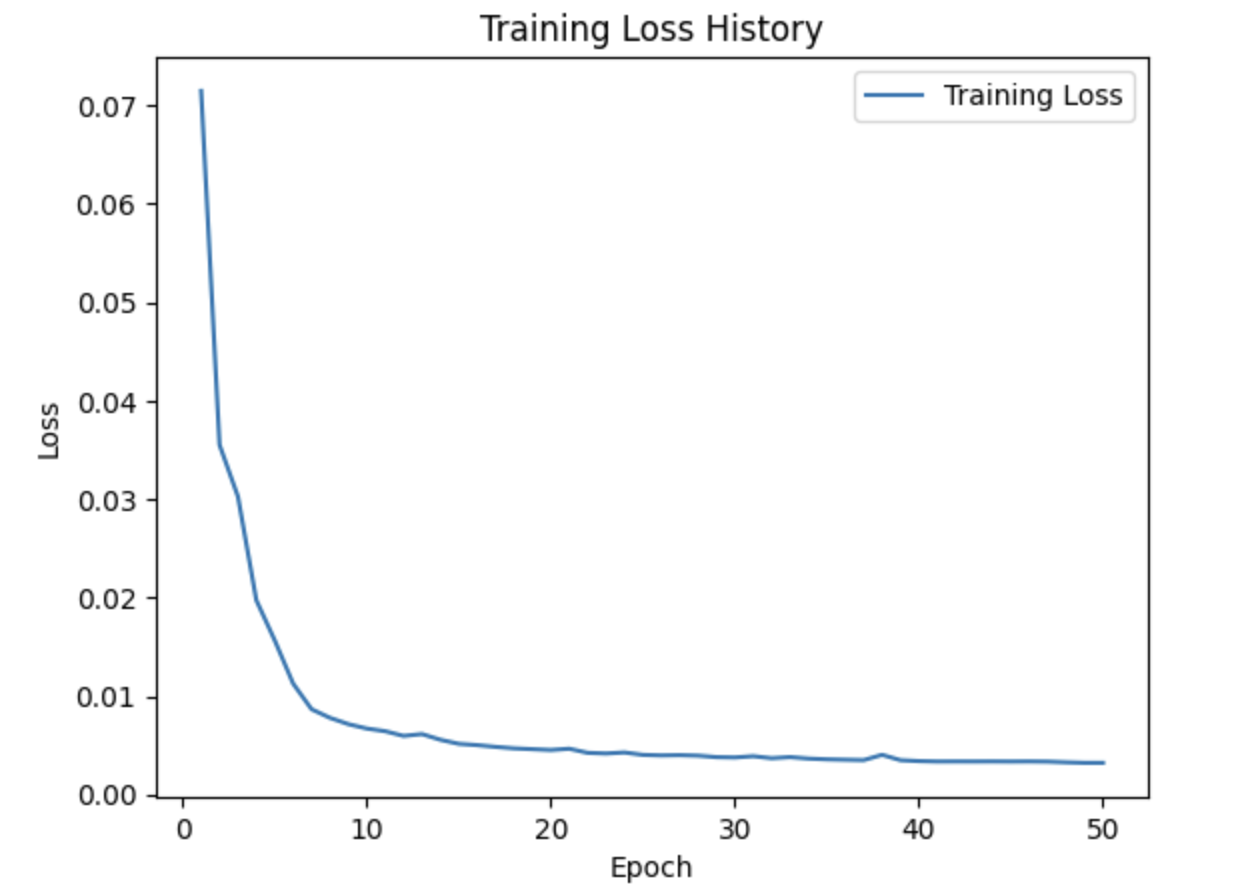 위의 그래프는 x3 upscaling factor에 대해 training을 실행했을 때 loss를 나타낸 그래프입니다. batch size 16으로 50번 epoch로 돌려주었습니다. 보다시피, loss가 잘 감소하여 수렴한 것을 확인할 수 있습니다.
위의 그래프는 x3 upscaling factor에 대해 training을 실행했을 때 loss를 나타낸 그래프입니다. batch size 16으로 50번 epoch로 돌려주었습니다. 보다시피, loss가 잘 감소하여 수렴한 것을 확인할 수 있습니다.
Example
 Test Dataset 중, Set5 dataset의 나비 사진을 입력으로, 위에서 학습한 모델(upscaling factor : x3)을 이용하여 super-resolution task를 진행해주었습니다.
Test Dataset 중, Set5 dataset의 나비 사진을 입력으로, 위에서 학습한 모델(upscaling factor : x3)을 이용하여 super-resolution task를 진행해주었습니다.
전반적으로 화질 개선이 잘 일어났으나 부분부분에 노이즈가 발생한 것을 확인할 수 있었습니다(초록색, 파란색의 점들). 아마도 epoch 수를 늘리거나, 다른 조절 가능한 부분들을 조절해본다면 노이즈 없이 super-resolution task를 기대했던대로 할 수 있을 것이라고 생각합니다.
Conclusion
이번에는 아주 기본적인 모델 구조지만 좋은 super-resolution 성능을 보여주는 FSRCNN에 대한 리뷰를 진행해보았습니다. CNN을 베이스로 한 모델이기 때문에, 오랜만에 CNN의 기본적인 부분들을 다시금 공부해볼 수 있어서 좋은 경험이었던 것 같습니다.
다음에도 좋은 논문들 가져와서 리뷰해보도록 하겠습니다. 아마도 AI 가속 관련된 논문에 대해서 리뷰를 계속 진행할 것 같네요. 감사합니다.
Reference
- Andreas128-mmsr 구현 github : 실험에 사용한 데이터셋 다운
