22.07.05 selenium을 이용해서 사이트 자동화 진행
selenium을 이용해서 사이트 자동화 진행해보기.
- d(관리자권한실행) - pip install selenium 입력 후 설치
- chrome webdriver - chrome 버전에 맞게 다운로드
selenium_baisc
<script>
'''
* 셀레늄: 웹 자동화 및 웹의 소스코드를 수집하는 모듈
- cmd -> pip install selenium (셀레늄 라이브러리 다운로드)
- 셀레늄 임포트
'''
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 다운로드 받은 크롬 물리드라이버 가동 명령.
driver = webdriver.Chrome('C:/Users/jwons/OneDrive/바탕 화면/java_web_JJW/python/chromedriver_win32/chromedriver.exe')
# 물리 드라이버로 사이트 이동 명령
driver.get('https://www.naver.com') # 실행하면 네이버가 열린다.호아아
time.sleep(1.5)
# 자동으로 버튼이나 링크 클릭 제어하기
# xpath : XML Path Language
# -> 문서의 특정 요소나 속성에 접근하기 위한 경로를 지정하는 언어.
# -> 요소를 중복없이 정확하게 표현하기 쉬운 언어.
login_btn = driver.find_element(By.XPATH, '//*[@id="account"]/a') # 로그인 버튼 자동 클릭
login_btn.click()
time.sleep(1)
# 자동으로 텍스트를 입력하기
id_input = driver.find_element(By.XPATH, '//*[@id="id"]')
id_input.send_keys('jjw6566')
time.sleep(1)
pw_input = driver.find_element(By.XPATH, '//*[@id="pw"]')
pw_input.send_keys('Alsxm1022!')
time.sleep(1)
driver.find_element(By.XPATH, '//*[@id="log.login"]').click() # 로그인버튼 클릭
# 다만 네이버에서 이렇게 로그인을 하는 방법을 보안상으로 막아 놨당!
# 연습
# 네이버 접속 -> 검색창에 '오늘날씨' 입력 -> 첫번째로 뜨는 네이버 뉴스
driver.find_element(By.XPATH, '//*[@id="query"]').send_keys('오늘 날씨')
time.sleep(1)
driver.find_element(By.XPATH, '//*[@id="search_btn"]').click()
time.sleep(1)
driver.find_element(By.XPATH, '//*[@id="sp_nws_all1"]/div[1]/div/a').click()
</script>selenium_practice
<script>
'''
네이버로 접속하셔서 뉴스스탠드 위쪽에 있는 파란색 '뉴스홈' 링크를
클릭하세요.
상단에 있는 메뉴 중 정치, 경제, 사회, 생활/문화, 세계, IT/과학
탭을 돌아다니면서 헤드라인 뉴스 4개씩 클릭해 주시면 됩니다.
뒤로가기는 driver.back() 메서드로 뒤로가기 가능합니다.
XPATH를 따다 보면 규칙을 발견하실 수 있을 겁니다.
반복문 이용해서 클릭 명령을 내려 주시면 됩니다.
24개의 명령을 일일히 쓰라는 게 아니에요. 규칙을 꼭 발견 하세요.
상단의 탭에도 규칙이 존재 하고요
뉴스도, 사진이 있는 뉴스와 그렇지 않은 뉴스가 XPATH가 조금씩 다른것을 유념하세요.
'''
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome('C:/Users/jwons/OneDrive/바탕 화면/java_web_JJW/python/chromedriver_win32/chromedriver.exe')
driver.get('https://www.naver.com')
time.sleep(1)
# 뉴스 홈 클릭
driver.find_element(By.XPATH, '//*[@id="NM_NEWSSTAND_HEADER"]/div[2]/a[1]').click()
time.sleep(1)
# 정치탭 클릭
driver.find_element(By.XPATH, '/html/body/section/header/div[2]/div/div/div[1]/div/div/ul/li[2]/a/span').click()
time.sleep(2)
for x in range(3, 9): # 9까지줘야지 세계탭이동후 뉴스반복문을 실행한다.
#헤드라인 뉴스를 클릭하는 반복문.
for n in range(1, 5):
# 조건문을 사용해서 정치 탭인 경우와 아닌경우를 다르게 해줌.
if x > 3: # 현재 정치 탭이 아닌 경우
i = 2
else: # 현재 정치 탭인 경우
i = 1
try:
# 뉴스헤드라인의 기본값: 썸네일이 존재하는 뉴스 기사
news_head = f'//*[@id="main_content"]/div/div[2]/div[1]/div[{n}]/div[{i}]/ul/li[1]/div[2]/a'
driver.find_element(By.XPATH, news_head).click()
except: # 뉴스기사에 썸네일이 없음
news_head = f'//*[@id="main_content"]/div/div[2]/div[1]/div[{n}]/div[{i}]/ul/li[1]/div/a'
driver.find_element(By.XPATH, news_head).click()
time.sleep(0.7)
driver.back()
time.sleep(0.5)
if x == 8:
break
# 다른 분야 탭 누르는 동작.
news_tap = f'//*[@id="lnb"]/ul/li[{x}]/a/span'
driver.find_element(By.XPATH, news_tap).click()
time.sleep(0.5)
</script>크롤링(crawling)
crawler_aladin01
-
알리딘 홈페이지의 베스트셀러 부분에 책들에 대한 정보를 크롤링진행.
-
뷰티풀수프 라이브러리 다운 cmd - pip install bs4 설치
-
일단 1개의 책정보만 얻어보기.
<script>
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
# 뷰티풀수프 임포트
from bs4 import BeautifulSoup
# 웹 드라이버 활성화 및 알라딘 홈페이지 이동
driver = webdriver.Chrome('C:/Users/jwons/OneDrive/바탕 화면/java_web_JJW/python/chromedriver_win32/chromedriver.exe')
driver.get('https://www.aladin.co.kr')
t.sleep(1)
# 베스트 셀러 탭 클릭
driver.find_element(By.XPATH, '//*[@id="re_mallmenu"]/ul/li[3]/div/a/img').click()
t.sleep(1)
# selenium으로 현재 페이지의 html 소스 코드를 전부 불러오기.
src = driver.page_source
# 퓨티풀수프 객체 생성
# 뷰티풀수프 객체를 생성하면서, 셀레늄이 가지고 온 thml 소스코드를 제공하고,
# 해당 소스코드를 html 문법으로 변환하라는 주문.
soup = BeautifulSoup(src, 'html.parser')
'''
- 뷰티풀수프를 사용하여 수집하고 싶은 데이터가 들어있는
태그를 부분 추출할 수 있습니다.
- find_all() 메서드는 인수값으로 추출하고자 하는 태그의
이름을 적으면 해당 태그만 전부 추출하여 리스트에 담아 대입합니다.
'''
div_list = soup.find_all('div', class_='ss_book_box')
print('div_list에 들어있는 데이터 수:', len(div_list))
print(div_list[0]) # 1위 책만 가져와 보자.
first_book = div_list[0].find_all('li')
# li안에 필요한 텍스트가 다 있더라. 2, 3, 4번째 li의 텍스트를 가져와야 하겠더라.
# text는 태그를 제외한 사용자가 실제로 브라우저에서 확인 가능한
# 텍스트만을 추출하여 문자열 형태로 반환.
book_title = first_book[1].text
book_author = first_book[2].text
book_price = first_book[3].text
auth_info = book_author.split('|')
print('# 제목:', book_title) # [국내도서] 방과 후 소년 하나코 군
print('# 저자:', auth_info[0]) # Aidairo (지은이), 장혜영 (옮긴이)
print('# 출판사:', auth_info[1]) # 서울미디어코믹스(서울문화사)
print('# 출판일:', auth_info[2]) # 2022년 7월
print('# 가격:', book_price.split(', ')[0]) # 6,000원 → 5,400원 (10%할인)
</script>datetime
<script>
'''
* 표준 모듈 dateime
- 운영체제의 현재 시간과 날짜 정보를 파이썬 내부로 읽어오는 기능을 제공하는 모듈.
'''
from datetime import datetime
# 오늘 날짜와 현재 시간 정보를 가지고 있는 객체 리턴
d = datetime.today()
print(d) # 2022-07-06 12:11:42.578655
print(f'지금은 {d.year}년 {d.month}월 {d.day}일 {d.hour}시 {d.minute}분 {d.second}초 입니다.')
</script>crawler_aladin02
- 1~400위 까지 책 정보 끌고오기
<script>
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
from bs4 import BeautifulSoup
from datetime import datetime
import codecs
d = datetime.today()
file_path = f'C:/Users/jwons/OneDrive/바탕 화면/java_web_JJW/python/crawling/알라딘 베스트셀러 1~400위_{d.year}_{d.month}_{d.day}.txt'
'''
- with문을 사용하면 with 블록을 벗어나는 순간
객체가 자동으로 해제됩니다. (자바의 try with resource과 비슷)
- with 작성 시 사용할 객체의 이름을 as 뒤에 작성해 줍니다.
'''
'''
* 표준 모듈 codecs
- 웹이나 다른 프로그램의 텍스트 데이터와
파이썬 내부의 텍스트 데이터의 인코딩 방식이 서로 다를 경우에
내장함수 open()이 제대로 인코딩을 적용할 수 없어서
에러가 발생합니다. (UnicodeEncodeError)
- 파일 입/출력 시 인코딩 코덱을 변경하고 싶다면
codecs 모듈을 사용합니다.
'''
with codecs.open(file_path, mode='w', encoding='utf-8') as f:
driver = webdriver.Chrome('C:/Users/jwons/OneDrive/바탕 화면/java_web_JJW/python/chromedriver_win32/chromedriver.exe')
driver.get('https://www.aladin.co.kr/shop/common/wbest.aspx?BranchType=1')
rank = 1 # 순위 표시
for n in range(3, 11):
src = driver.page_source # 소스코드 전부 끌고오자.
soup = BeautifulSoup(src, 'html.parser') # bs 객체 생성.
div_list = soup.find_all('div', class_='ss_book_box')
for div in div_list:
book_info = div.find_all('li')
if book_info[0].find('span', class_='ss_ht1') == None:
print(f'{rank}위 증정품 없음!')
book_title = book_info[0].text
book_author = book_info[1].text
book_price = book_info[2].text
else:
print(f'{rank}위 증정품 있음!')
book_title = book_info[1].text
book_author = book_info[2].text
book_price = book_info[3].text
auth_info = book_author.split(' | ')
f.write(f'# 순위: {rank}위 \n')
f.write(f'# 제목: {book_title} \n')
f.write(f'# 저자: {auth_info[0]} \n')
f.write(f'# 출판사: {auth_info[1]} \n')
f.write(f'# 출판일: {auth_info[2]} \n')
f.write('# 가격:' + book_price.split(', ')[0] + '\n')
f.write('-' * 40 + '\n')
rank += 1
# 한 페이지의 크롤링이 완료 된 후 탭 누르기 진행
if n == 10:
break
tap = f'//*[@id="newbg_body"]/div[3]/ul/li[{n}]/a'
driver.find_element(By.XPATH, tap).click()
t.sleep(0.5)
</script>robots.txt
ex) https://www.aladin.co.kr/robots.txt
<피할 url(불허용)>
User-agent: *
Disallow: /aaintraweb/
Disallow: /account/
Disallow: /api/
Disallow: /errormng/
Disallow: /intranet/
Disallow: /jiny/
Disallow: /login/
Disallow: /mail/
Disallow: /mng/
Disallow: /order/
Disallow: /scm/
Disallow: /search/
Disallow: /ttb/
Disallow: /webservice/
Disallow: /wservice/
Disallow: /*?EventId=201357
Disallow: /*?EventId=199338
Disallow: /*?EventId=198631
Allow: /
User-Agent: QuerySeekerSpider ( http://queryseeker.com/bot.html )
Disallow: /
User-agent: AhrefsBot
Disallow: /
User-agent: MJ12bot
Disallow: /
User-agent: SemrushBot
Disallow: /
User-agent: Baiduspider
Disallow: /
User-agent: Ezooms
Disallow: /
User-agent: YandexBot
Disallow: /
User-agent: ltx71
Disallow: /ex) naver.com/robots.txt
User-agent: *
Disallow: /
Allow : /$ kyobo_url
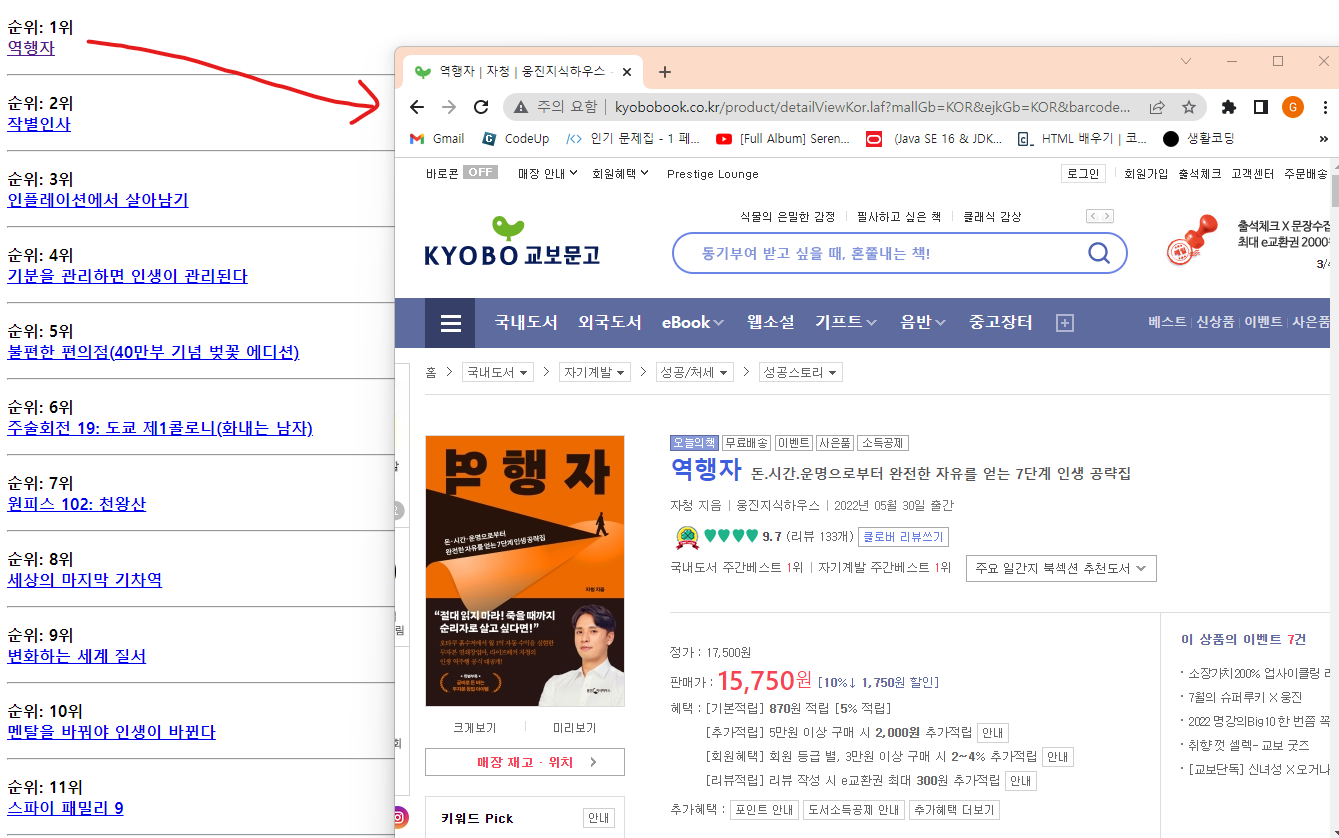
- 교보문고 베스트셀러 크롤링
- html형식으로 사용자에게 링크를 제공해서
사용자가 링크를 누르면 해당 책의 상세보기 페이지로 이동.
<script>
from selenium import webdriver
import time as t
from bs4 import BeautifulSoup
from datetime import datetime
import codecs
d = datetime.today()
file_path = f'C:/Users/jwons/OneDrive/바탕 화면/java_web_JJW/python/crawling/교보문고 베스트셀러 1~50위_{d.year}_{d.month}_{d.day}.html'
with codecs.open(file_path, mode='w', encoding='utf-8') as f:
driver = webdriver.Chrome('C:/Users/jwons/OneDrive/바탕 화면/java_web_JJW/python/chromedriver_win32/chromedriver.exe')
driver.get('http://www.kyobobook.co.kr/bestSellerNew/bestseller.laf?orderClick=d79')
t.sleep(1.5)
rank = 1
src = driver.page_source # 소스코드 전부 끌고오자.
soup = BeautifulSoup(src, 'html.parser') # bs 객체 생성.
title_list = soup.find_all('div', class_='title')
# print(len(title_list))
f.write('<!DOCTYPE HTML> \r\n')
f.write('<html> \r\n')
f.write('<head> \r\n')
f.write('<meta charset="UTF-8"> \r\n')
f.write('<title> 교보문고 베스트셀러 1~50</title> \r\n')
f.write('</head> \r\n')
f.write('<body> \r\n')
for idx in range(len(title_list)):
if idx > 31:
f.write('<p> \r\n')
f.write(f'<b>순위: {rank}위</b> <br> \r\n')
a_url = str(title_list[idx].find('a'))
href = a_url.get('href') # 속성얻어오는 방법
f.write(a_url + '\n <hr> \n')
rank += 1
f.write('</p> \r\n')
f.write('</body> \r\n')
f.write('</html> \r\n')
</script><script>
</script>