1. 제네릭
1.1 제네릭이란?
제네릭은 JDK 1.5 버전부터 도입된 개념이다. 자바의 제네릭은 c++의 템플릿과 동일한데, generics은 일반적인 이라는 의미가, template은 형판, 틀이라는 의미가 담겨있다. 제네릭을 한 줄로 정의하자면 모든 종류의 참조자료형을 사용할 수 있도록 일반화시키는 도구라고 할 수 있다.
글만 보면 감이 오지 않을 수도 있지만, 사실 제네릭은 지금까지 계속 사용해왔던 개념이다. 바로 ArratList 가 대표적인 제네릭 자료형이기 때문이다. ArratList 의 원형은 다음과 같다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.SerializableArrayList<E> 에서 <E> 은 '타입 매개변수', 또는 '자료형 매개변수'라고 불리며, ArrayList 의 배열요소로 어떤 자료형이라도 사용할 수 있도록 일반화 시켜놓은 것이다. 일반적으로 하나의 대문자를 사용하며, E는 보편적으로 Element를 의미한다. ArrayList 의 요소임을 나타내고 있는 것이다. E 말고도 관례적으로 사용되는 타입 매개변수가 몇개 더 있다.
T : Type을 의미
V : Value를 의미
K : Key를 의미다만 타입 매개변수 자체는 가변적이지만, 구체적인 자료형을 지정하고 난 후에는 정해진 자료형으로만 사용해야한다. ArrayList<E> 를 예로 들자면 E 자체에는 Integer, String 등 다양한 자료형이 들어갈 수 있지만, ArrayList<Integer> 로 선언이 되고 나면 배열 요소는 오직 Integer 자료형만 있어야한다. 이렇게 제네릭 자료형에 구체적인 타입을 넣어 구체적인 객체를 생성하는 것을 구체화라고 부르며, 이 과정은 자바 컴파일러에 의해 이루어진다.
그리고 제네릭 타입은 객체 자료형으로만 가능하므로 만약 int 와 같은 기본 자료형의 값이 삽입되면 오토 박싱에 의해 Wrapper 클래스 타입으로 변환된다.
1.2 제네릭의 필요성
Object 클래스의 사용대신 제네릭을 사용하는 이유와 제네릭 자료형의 제거 시기
자바에는 모든 클래스의 최상위 클래스 Object 클래스가 존재하므로, 제네릭을 사용하는 것처럼 객체 타입을 Object 로 선언해둔다면, 어떤 자료형이 와도 무방하다. 그런데 왜 Object 클래스가 아니라 제네릭 자료형 사용하는 걸까?
제네릭은 동적으로 타입이 결정되는 게 아니라 컴파일 시에 어떤 타입으로 사용될지 결정되기 때문에, 비교적 안전한 프로그래밍을 할 수 있다. 그리고 만약 Object 클래스를 사용할 경우, 형변환을 해주어야하는 절차가 불가피하게 되는데, 제네릭은 이런 과정이 필요없다.
1.3 제네릭 클래스 정의 및 사용하기
package generic;
public class Generic3DPrinter<T> {
private T material;
public void setMaterial(T material) {
this.material = material;
}
public T getMaterial(T material) {
return material;
}
}제네릭 클래스가 아닌 클래스들과 다른 점은 클래스 명 뒤에 <T>, 자료형 매개변수(Type parmeter)가 붙는다는 것 뿐이다. 그리고 이 자료형(T)을 사용할 곳에 모두 명시해준다. 제네릭 클래스의 선언과 사용은 다음과 같다.
package generic;
public class Main {
public static void main(String[] args) {
Generic3DPrinter<Powder> powder3D = new Generic3DPrinter<Powder>();
Generic3DPrinter<Plastic> plastic3D = new Generic3DPrinter<>();
powderPrinter.setMaterial(new Powder());
plasticPrinter.setMaterial(new Plastic());
System.out.println(powder3D.getMaterial());
System.out.println(plastic3D.getMaterial());
}
}generic.Powder@7d417077
generic.Plastic@7dc36524자료형 매개변수를 감싸고 있는 <> 이 연산자를 다이아몬드 연산자라고 부르는데, plasticPrinter 을 선언할 때처럼 생성자 부분의 자료형을 명시적으로 적지 않아도 오류없이 컴파일이 가능하다. 선언된 부분을 보고 어떤 자료형인지 컴파일러가 유추할 수 있기 때문이다.
그리고 자료형 매개변수는 다음과 같이 여러개를 받을 수 있다.
package generic;
public class Point<T, V> {
T x;
V y;
Point(T x, V y) {
this.x = x;
this.y = y;
}
public T getX() {
return x;
}
public V getY() {
return y;
}
}package generic;
public class Main {
public static void main(String[] args) {
Point<Integer, Double> point1 = new Point<>(1, 3.14);
Point<Integer, Double> point2 = new Point<>(5, 0.5);
System.out.println(point1.getX());
System.out.println(point1.getY());
System.out.println(point2.getX());
System.out.println(point2.getY());
}
}1
3.14
5
0.51.4 <T extends 클래스>
현재까지 다룬 제네릭 클래스는 모든 자료형을 담을 수 있었다. 하지만 때에 따라 이 자료형의 범위를 제한하고 싶을 때가 있을 것이다. 예를 들어 방금 연습했던 Generic Printer 에 파우더나 플라스틱과 같은 객체 자료형이 아니라, 자동차, 카페 와 같은 객체로 구체화된다고 상상해보자. 뭔가 어색하지 않은가? Generic Printer 에 들어갈 수 있는 자료형을 파우더나 플라스틱과 같은 재료로 한정시키고 싶다면 어떻게 해야할까?
우선, 3D 프린터의 재료가 될 수 있는 객체들을 일반화시킨 클래스를 구상하고, 파우더와 플라스틱과 같은 구체적인 객체들을 그 클래스에서 상속받아 구현한다.
package generic;
public class Powder extends Martial{
public String toString() {
return "Martial을 상속받은 Power";
}
}package generic;
public class Plastic extends Martial{
public String toString() {
return "Martial을 상속받은 Plastic";
}
}그리고 <T extends Material> 사용하여 제네릭 클래스를 정의한다. T extends Material 에서의 extends 는 상속을 할 때 사용했던 그 예약어가 맞다. 즉, 제네릭 자료형 T 는 Material 으로부터 확장되었다는 뜻이고, T 에 대입될 자료형은 Material 자료형 이어야 한다. Material을 상속 받은 자식 클래스도 부모 클래스인 Material 자료형을 내포하고 있으므로, 당연히 대입이 가능하다.
package generic;
public class Generic3DPrinter<T extends Martial> {
private T material;
public void setMaterial(T material) {
this.material = material;
}
public T getMaterial() {
return material;
}
public String toString() {
return material.toString();
}
}이 때, <T extends Material> 가 아니라 <Material> 로 적으면 안된다. 형태만 다를 뿐 <T> 와 의미가 동일하다. 테스트 코드는 아래와 같다.
package generic;
public class Main {
public static void main(String[] args) {
Generic3DPrinter<Powder> powder3D = new Generic3DPrinter<Powder>();
Generic3DPrinter<Plastic> plastic3D = new Generic3DPrinter<>();
powder3D.setMaterial(new Powder());
plastic3D.setMaterial(new Plastic());
System.out.println(powder3D);
System.out.println(plastic3D);
}
}Martial을 상속받은 Power
Martial을 상속받은 Plastic1.5 제네릭 메서드 활용하기
클래스를 정의할 때 제네릭 자료형이 필요했던 것과 마찬가지로 메서드를 정의할 때도 제네릭 자료형이 필요할 때가 있다. 클래스의 일부 메소드만 제네릭 메서드로 만들수도 있는데, 위에서 만들어보았던 Point 클래스 2개를 받아 두 점이 대각방향에 있는 직사각형의 넓이를 구하는 함수를 만든다고 가정해보자.
package generic;
public class GenericMethod {
public static <T, V> double getRectangleArea(Point<T, V> point1, Point<T, V> point2) {
double diff_x = ((Number)point1.getX()).doubleValue() - ((Number)point2.getX()).doubleValue();
double diff_y = ((Number)point1.getY()).doubleValue() - ((Number)point2.getY()).doubleValue();
double width = diff_x > 0 ? diff_x : -diff_x;
double height = diff_y > 0 ? diff_y : -diff_y;
return width * height;
}
}package generic;
public class Main {
public static void main(String[] args) {
Point<Integer, Double> point1 = new Point<>(1, 3.14);
Point<Integer, Double> point2 = new Point<>(5, 0.5);
System.out.println(GenericMethod.getRectangleArea(point1, point2));
}
}10.56위의 제네릭 클래스 안에 정의되었던 메소드의 형태와는 살짝 다르다. 선언부를 보면 제네릭 클래스에서 받은 타입 인자를 활용해서 메서드를 구현하는 경우, 다이아몬드 연산자를 쓰지 않지만, 독립적으로 제네릭 메서드를 만드는 경우 다이아몬드 연산자를 활용한다.
현재 getRetangleArea 함수가 구현되어있는 GenericMethod 클래스는 제네릭 클래스가 아니다. 하지만 제네릭 메서드는 지금과 마찬가지로 제네릭 클래스 안에서도 선언할 수도 있는데, 주의해야할 점이 있다.
public class GenericMethod<T> {
public static <T, V> double getRectangleArea(Point<T, V> point1, Point<T, V> point2) {만약 GenericMethod 가 제네릭 클래스였다면 다음과 같은 형태가 될 것이다. 하지만 클래스의 자료형 매개변수 T 와 제네릭 메소드의 자료형 매개변수 T 는 형태만 같을 뿐 전혀 다른 의미를 갖고 있다. 메서드의 자료형 매개변수는 오직 메서드 내에서만 유효하다.
2. 컬렉션 프레임워크
2.1 컬렉션 프레임워크란?
컬렉션 프레임워크(collection framework)는 java.utill 패키지에서 제공하는 자료구조 라이브러리다. (자료구조는 프로그램 실행 중 메모리에 자료를 유지관리하기 위해 사용된다.) 자바의 컬렉션 프레임워크에는 여러 인터페이스가 정의되어 있고, 그 인터페이스를 구현한 클래스 또한 포함되어 있다.
컬렉션은 배열이 가진 단점 때문에 만들어졌다. 여기서 이야기하는 배열은 ArrayList 클래스가 아니라 크기가 고정되어 있는 일반 배열을 의미한다.
배열 자료구조는 편리한 점이 있긴하지만, 선언할 때 반드시 크기를 고정해주어야 하고 그 크기를 변경시킬 수 없다. 그리고 삽입이나 삭제를 할 때 유연하게 할 수 없다는 단점 때문에, 가변적으로 사용해야하는 경우나 데이터의 크기를 알 수 없는 경우 불편하다. 컬렉션은 배열의 이러한 단점을 극복하기 위해 만들어진, 객체들을 쉽게 삽입, 삭제, 검색할 수 있는 가변 크기의 컨테이너이다.
컬렉션 프레임워크의 구조는 크게 Collection 인터페이스와 Map 인터페이스로 나눌수 있고, 각 인터페이스를 구현한 클래스는 종류가 다양하다. 컬렉션은 제네릭 기법으로 구현되어있기 때문에 제네릭을 제대로 이해하는 것이 컬렉션 프레임워크를 이용하는데 도움이 될 것이다.
2.2 Collection 인터페이스
Collection 인터페이스는 하나의 자료를 모아서 관리하는 데 필요한 기능을 제공한다. Collection 인터페이스 하위에는 순차적인 자료를 관리하는 List 인터페이스와 집합과 같이 순서가 없고 중복을 허용하지 않는 자료를 관리하는 Set 인터페이스가 있다.
Collection 인터페이스에서 자주 사용하는 메서드는 아래와 같다. Collection의 메소드는 모두 static 타입 이므로 인터페이스명으로 참조하여 사용할 수 있다.
| 메서드 | 설명 |
|---|---|
boolean add(E e) | Collection에 객체를 추가 |
void clear() | Collection에 모든 객체를 제거 |
Iterator<E> iterator | Collection을 순환할 Iterator를 반환 |
boolean remove(Object o) | Collection에 매개변수에 해당하는 인스턴스가 존재하면 제거 |
void clear() | Collection에 있는 요소의 개수를 반환 |
sort(), reverse() | 컬렉션에 포함된 요소들의 정렬 or 반대로 정렬 |
max(), max() | 요소들의 최댓값 or 최소값 찾아내기 |
binarySearch() | 이진 검색 |
다른 메서드들은 ArrayList 클래스를 사용하며 몇번 다뤄봤지만 Iterator <E> iterator 은 조금 낯선편이다. iterator 에 대한 부분과 사용법은 List 인터페이스에서 더 다뤄볼 예정이다.
[TCP School] Iterator와 ListIterator
Collection 클래스의 binarySearch()
2.3 Map 인터페이스
Map 인터페이스는 하나가 아닌 쌍(Pair)으로 되어 있는 자료를 관리할 때 사용한다. key-value 쌍이라고 표현하는데, key 값은 중복을 허용하지 않는다. 학번-이름, 주민번호-이름과 같이 중복이 없는 key 값과 그에 대응되는 value 값을 다루는데 편리한 인터페이스이다. Map 인터페이스는 기본적으로 검색용 자료구조로, 유일한 key 값을 통해 value 값을 찾는 식이다.
Map 인터페이스의 주요한 메서드는 아래와 같다.
| 메서드 | 설명 |
|---|---|
V put(K key, V value) | key에 해당하는 value 값을 map에 넣음 |
V get(K key) | key에 해당하는 value 값을 반환 |
boolean isEmpty() | Map이 비었는지 여부를 반환 |
boolean containsKey(Object key) | Map에 해당 key가 있는지 여부를 반환 |
boolean containsValue() | Map에 해당 value가 있는지 여부를 반환 |
Set keyset() | key 집합을 Set로 반환(중복 안되므로 Set) |
Collection values() | value를 Collection으로 반환(중복 무관) |
V remove(Object key) | key가 있는 경우 삭제 |
boolean remove(Object key, Object value) | key가 있는 경우 key에 해당하는 value가 매개변수와 일치할 때 삭제 |
3. List 인터페이스
3.1 ArratList 클래스
자바 세미나 4회에서 다루었던 ArrayList (2.1의 링크와 동일!)
배열 용량에 대하여
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;ArrayList 의 원형을 살펴보면 다음과 같은 디폴트 용량이 정해져 있다. ArrayList 디폴트 생성자를 호출하여 배열 크기를 따로 지정하지 않으면 10개짜리 배열이 만들어지는 것이다. 만약 ArrayList 의 인자로 정수를 넘겨주면 그 숫자만큼 초기 용량을 설정할 수 있다. (ArrayList(30) 이면 30개 짜리 배열이 초기에 생성)
이 때 배열의 크기를 알기 위해 size() 메서드를 사용하면 10을 반환할까? 결론부터 말하자면 아니다. size() 메서드는 배열의 크기가 아니라 배열에 몇개의 요소가 들었는지 반환한다. 배열 자체의 크기와는 상관없이 생성하고 어떠한 요소도 넣지 않았다면 0을 반환할 것이고, 만약 5개를 넣었다면 5를 반환할 것이다.
만약 요소를 계속 추가하여 이 디폴트 용량을 벗어나게 된다면, ArrayList 는 더 큰 용량의 배열을 새로 만들고 기존 배열에 있던 요소들을 복사해넣는다.
3.2 ArrayList와 Vector클래스
ArrayList 와 Vector 는 모두 가변 크기의 배열을 구현한 컬렉션 클래스로 기능은 거의 동일하다. 다만 ArrayList 는 스레드 간에 동기화(synchronization)를 지원하지 않기 때문에, 다수의 스레드가 동시에 요소를 삽입하거나 삭제하면 데이터가 훼손될 수도 있다.
스레드라는 것은 작업 단위라고 할 수 있는데, 하나의 작업만 수행되면 단일 스레드(single thread), 두개 이상의 작업이 동시에 실행되면 멀티 스레드(multi-thread)라고 한다. 멀티스레드의 경우 같은 메모리 공간에 동시에 접근하게 되는데, 자칫하면 이 과정에서 오류가 생길 수 있다. 이 때 동시에 메모리에 접근하지 않도록 순서를 맞추는 것이 동기화이다.
Vector 이러한 동기화를 지원하기 때문에 다중스레드 환경에서 안전하게 사용할 수 있다는 장점이 있다. 그러나 ArrayList가 안전성을 보장하지 않는만큼 멀티스레드 동기화를 위한 시간 소모도 없기 때문에 Vector 보다 비교적 속도가 빠른 편이다. 그러므로 단일 스레드의 경우 ArrayList 를 사용하는 편이 효과적이다.
만약 ArrayList로 구현했는데 동기화가 필요해졌다면, Vector 클래스로 변경할 필요없이 synchronizedList() 함수를 사용하면 된다.
Collections.synchronizedList(new ArrayList<E>());3.3 LinkedList클래스
3.3.1 연결리스트
배열은 인덱스 연산을 통해 원하는 인덱스의 값을 얻기는 편했지만, 원하는 곳에 삽입하고 삭제하려면, 요소들을 전부 밀어 빈공간을 만들거나 없애는 과정이 불가피 했다. 연결리스트(LinkedList)는 인덱스를 통한 접근은 어렵지만 배열의 이러한 단점을 보완할 수 있는 자료구조이다.
요소를 새로 추가할 때마다 메모리를 생성하기 때문에 잉여 메모리가 없고, 중간에 요소를 추가하거나 삭제할 때 자료의 이동이 적은 편이기 때문에 삽입, 삭제가 빈번할 경우 배열보다 리스트를 사용하는 편이 좋다.
연결리스트 구조 (출처 : C언어 코딩도장)

일반적으로 연결리스트의 형태는 다음과 같다. 연결리스트의 각 요소에는 자료와 다음 요소의 주소값이 저장되어 있어, head 의 주소만 알아도 연결리스트의 끝까지 순회할 수 있다. 다음 주소를 연쇄적으로 탐색하면 되기 때문이다. (다음 요소가 없을 경우에는 다음 요소의 주소는 null로 저장되어 있음)
이 연결리스트의 마지막 부분에 특정 요소 A를 추가하고 싶다면, 다음 요소의 주소가 null인 곳으로 찾아가 다음 요소의 주소가 담기는 공간(next)에 A의 주소를 저장해주면 된다. 가장 첫 부분에 추가하고 싶다면 삽입할 요소의 next에 head 의 주소값을 담으면 된다. 그런데 만약 마지막 부분이 아니라 중간에 요소를 삽입하고 싶다면 어떻게 해야할까?
원래 node1에는 node2의 주소가, node2에는 node3의 주소가 (node3가 없다면 null 이) next 라는 공간에 담여 있었다. 만약 새로운 요소 nodeA 를 node1과 node2 사이에 삽입하고 싶다면, node1의 next 에는 nodeA 의 주소가, nodeA 의 next 에는 node2의 주소가 담겨야할 것이다. 이때 node1의 next 부터 변경해버리면 node2의 주소를 유실해버리므로 nodeA 에 먼저 node2의 주소값을 담아준 후, node1의 next 를 nodeA 의 주소값으로 바꿔주면 된다.
요소를 삭제하는 과정도 삽입하는 과정과 마찬가지로 next 의 주소값을 바꿔줌으로써 구현할 수 있다.
3.3.2 LinkedList의 사용
package collection;
import java.util.LinkedList;
public class LinkedListTest {
public static void main(String[] args) {
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("Hello");
linkedList.add("world");
System.out.println(linkedList);
linkedList.add(1, "my");
System.out.println(linkedList);
linkedList.addFirst("WOW");
linkedList.addLast("!");
System.out.println(linkedList);
linkedList.removeFirst();
linkedList.removeLast();
System.out.println(linkedList);
linkedList.remove(1);
System.out.println(linkedList);
linkedList.remove();
System.out.println(linkedList);
};
}[Hello, world]
[Hello, my, world]
[WOW, Hello, my, world, !]
[Hello, my, world]
[Hello, world]
[world]addFirst() 와 addLast() 메서드는 이름에서도 알 수 있듯이, 각각 처음 부분과 마지막 부분에 요소를 추가하는 메서드이다. removeFirst() 와 removeLast() 메서드도 마찬가지다.
add() 함수는 원하는 위치에 새로운 요소를 추가할 수 있게 해주는데, 만약 몇번째 요소임을 매개변수로 지정하지 않으면 디폴트로 가장 마지막 부분에 새로운 요소를 추가한다. 주의할 점은 가장 첫번째 요소로 넣고 싶다면 1이 아니라 0을 매개변수로 넣어주어야한다.
remove() 함수는 원하는 위치의 요소를 삭제할 수 있게 해준다. 만약 매개변수가 없다면 디폴트로 가장 첫번째 요소를 삭제한다. 이 부분은 add() 함수와 반대이므로 주의한다.
LinkedList의 toString
LinkedList 객체를 System.out.println() 으로 출력하면, 연결리스트의 모든 요소를 대괄호 안에 출력해준다. 신기해서 LinkedList의 toString 메서드를 찾아보았더니 다음과 같았다. 정확히는 LinkedList가 아니라 LinkedList의 상위 클래스인 AbstractCollection<E> 의 toString 메서드이다.
public abstract class AbstractCollection<E> implements Collection<E> {
public String toString() {
Iterator<E> it = iterator();
if (! it.hasNext())
return "[]";
StringBuilder sb = new StringBuilder();
sb.append('[');
for (;;) {
E e = it.next();
sb.append(e == this ? "(this Collection)" : e);
if (! it.hasNext())
return sb.append(']').toString();
sb.append(',').append(' ');
}
}
}3.4 Collection요소를 순회하는 Iterator
ArrayList에서 각각의 요소를 조회할 때를 상기시켜보면, 반복문 안에서 배열의 각 요소에 get(i) 메서드를 통해 접근하였다. 그러나 순서가 없는 Set 인터페이스의 경우 get(i) 메서드를 사용할 수가 없다. 그래서 이럴 때 사용하는 것이 Iterator 이다. (순서가 있는 곳에서는 쓸 수 없는 것이 아니다. ArrayList 나 Vector 등 순서가 있는 클래스에서도 사용할 수 있다.)
Iterator는 Collection 인터페이스를 구현한 클래스에서 정의되어 있는 iterator() 메서드를 호출하여 참조하는 방식으로 사용한다. iterator() 메서드를 호출하면 Iterator 객체를 반환받는데, Iterator 객체를 반복자라고 한다.
Vector<Integer> vector = new Vector<>();
Iterator<Integer> ir = vector.iterator();예를 들어 이런식으로 썼다면, iterator() 메서드를 통해 Vector의 객체 vector 의 요소를 순차검색할 Iterator<E> 객체를 반환받아 Iterator<E> 자료형 변수 ir 에 담는 것이다. 다이아몬드 연산자 안에는 검색할 요소의 자료형이 담겨있어야 한다. 현재, Vector의 배열요소가 Integer 자료형이기 때문에 Iterator 자료형 매개변수도 Integer로 설정한 것이다. 그리고 ir 변수를 통해 Iterator<E> 메서드를 호출하여 사용한다.
Iterator를 사용하여 요소를 순회할 때 사용하는 메서드
| 메서드 | 설명 |
|---|---|
boolean hasNext() | 방문할 요소가 남아있으면 true 리턴 |
E next() | 다음 요소 리턴 |
void remove() | 마지막으로 리턴된 요소 제거 |
메서드 사용 예제
package collection;
import java.util.Iterator;
import java.util.Vector;
public class IteratorTest {
public static void main(String[] args) {
Vector<Integer> vector = new Vector<>();
vector.add(33);
vector.add(4);
vector.add(1, 100);
vector.add(1, 87);
System.out.println(vector);
Iterator<Integer> ir = vector.iterator();
while (ir.hasNext()) {
int n = ir.next();
System.out.println(n);
}
};
[33, 87, 100, 4]
33
87
100
4먼저 hasNext() 를 통해 순회할 요소가 남았는지 확인하고, 남아있다면 next() 다음에 있는 요소를 반환받아 변수 n 에 저장한다. n 을 출력해보면 벡터의 요소들이 잘 담겨있음을 알 수 있다.
다만 주의해야할 점은 iterator 은 단방향으로 이동하기 때문에 마지막 요소에 도달하면 재사용이 불가능하다는 것이다. 첫번째 요소를 알 길이 없기 때문이다. 만약 다시 순회하고 싶다면 interator() 메서드로 Iterator 클래스를 재반환 받아야한다.
package collection;
import java.util.Iterator;
import java.util.Vector;
public class IteratorTest {
public static void main(String[] args) {
Vector<Integer> vector = new Vector<>();
vector.add(33);
vector.add(4);
vector.add(1, 100);
vector.add(1, 87);
System.out.println(vector);
Iterator<Integer> ir = vector.iterator();
while (ir.hasNext()) {
int n = ir.next();
System.out.println(n);
}
Iterator<Integer> ir2 = vector.iterator();
while (ir2.hasNext()) {
int n = ir2.next();
System.out.println(n);
}
};
}[33, 87, 100, 4]
33
87
100
4
33
87
100
4처음부터 next() 를 사용하는 이유
왜 처음부터 next() 로 다음 요소를 출력하는지 궁금해서 next() 하기 전에 출력해봤다.
Iterator<Integer> ir2 = vector.iterator();
System.out.println(ir2);
while (ir2.hasNext()) {
int n = ir2.next();
System.out.println(n);
}java.util.Vector$Itr@3f0ee7cb
33
87
100
4Iterator 객체의 주소가 나오는 것을 확인할 수 있었다.
4. Set 인터페이스
4.1 set인터페이스의 특징.
수학의 '집합'과 유사한 자료 저장 형태이다. 즉, 저장되는 객체의 순서가 유지되지 않고, 중복이 불가능한 저장 형태이다. set인터페이스를 구현한 클래스들로는 HashSet, LinkedHashset, TreeSet등이 있다. 아래 메소드들은 set인터페이스에 정의된 메소드 중 자주사용하는 것 들이다.
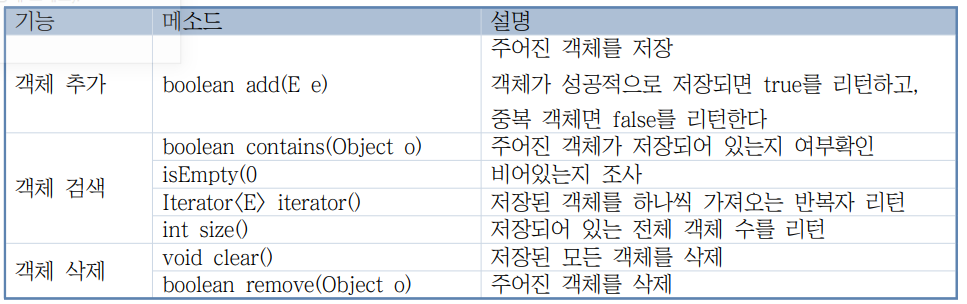
이미지 출처 : https://velog.io/@cyhse7/Set
정확한 정보 및 모든 메소드를 확인하고 싶다면 Oracle Docs확인.
언급한대로 set인터페이스는 순서를 신경쓰지 않기 때문에, 인덱스를 통해 검색할 수 없다. 저장된 객체 전체를 대상으로 한 번씩 반복해서 가져오는 반복자를 통해 저장된 객체에 접근할 수 있다.
반복자(Iterator) : Iterator인터페이스를 구현한 객체. 사용하고자하는 컬렉션의 .iterator()메소드를 호출하는 방식으로 얻을 수 있다.
Iterator<T> iterator = set.iterator();set에서 iterator에는 hasNext(), next(), remove()메소드가 있다.
boolean hasNext() : 다음으로 가져올 객체가 있으면 true, 없으면 false반환.
E next() : set컬렉션에서 다음 객체를 가져온다. 기본적으로 hasNext()로 가져올 객체가 있는지 확인한 후 가져오는 방식을 사용한다.
void remove() : set컬렉션에서 객체를 제거한다. 이때 제거되는 객체는 next()를 통해 가지고 온 객체이다.
4.2 HashSet클래스
set을 구현할 때 HashMap을 통해 set을 구현한 클래스. hashcode를 기준으로 중복 여부를 확인하며, 저장순서를 유지하지않는 일반적이고 빠른 set이다.
- 아래의 예제는 Member클래스를 만들고, 프로퍼티인 이름과 나이가 같다면 같은 hashcode값을 반환하게 equals()와 hashcode()메소드를 오버라이딩하여 Hashset에 저장해본 예제이다.
package setexample;
import java.util.Objects;
public class Member {
private String name;
private int age;
Member(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
// 인텔리제이가 자동완성해준 equals, hashCode오버라이딩...ㄷㄷㄷㄷ
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Member)) return false;
Member member = (Member) o;
return age == member.age && Objects.equals(name, member.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
} package setexample;
import java.util.*;
public class setTest {
public static void main (String[] args) {
Set<Member> setMember = new HashSet<Member>();
Iterator<Member> iterator;
setMember.add(new Member("홍길동", 28));
setMember.add(new Member("김선달", 31));
setMember.add(new Member("홍길동", 28));
setMember.add(new Member("김선달", 32));
iterator = setMember.iterator();
while (iterator.hasNext()) {
Member temp;
temp = iterator.next();
System.out.println(temp.getAge() + "살 " + temp.getName());
}
}
}28살 홍길동
31살 김선달
32살 김선달이름과 나이가 같으면 같은 hashcode반환하므로, 28살 홍길동은 하나의 객체만 저장되었다.
4.3 TreeSet클래스
set을 구현할 때 TreeMap(이진탐색 트리)을 통해 set을 구현한 클래스. hashcode를 기준으로 중복 여부를 확인하며, 오름차순으로 데이터를 정렬하는 set이다. 데이터 추가 삭제에는 순서를 고려하므로 오래 걸리지만, 검색과 정렬에서 다른 set구현 클래스들 보다 빠르다.
이때, 객체간 정렬 기준을 정의하기 위해 TreeSet클래스 내부에 저장될 객체는 Comparable<T>인터페이스를 구현해야한다(해당 내용은 바로 아래에서).
- 예제코드
package setexample;
import java.util.Objects;
public class Member implements **Comparable<Member>** {
private String name;
private int age;
Member(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
// 인텔리제이가 자동완성해준 equals, hashCode오버라이딩...ㄷㄷㄷㄷ
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Member)) return false;
Member member = (Member) o;
return age == member.age && Objects.equals(name, member.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
// 비교대상인 o를 넣었을 때,
// this가 더 클때 양수를 반환하면 오름차순(this와 o가 자리가 바뀜)
// 음수를 반환하면 내림차순으로 정렬된다.
**public int compareTo(Member o)** {
return (this.getAge() - o.getAge());
}
} import java.util.*;
public class setTest {
public static void main (String[] args) {
Set<Member> setMember = new TreeSet<Member>();
Iterator<Member> iterator;
setMember.add(new Member("홍길동", 38));
setMember.add(new Member("김선달", 41));
setMember.add(new Member("홍길동", 38));
setMember.add(new Member("김선달", 42));
iterator = setMember.iterator();
while (iterator.hasNext()) {
Member temp;
temp = iterator.next();
System.out.println(temp.getAge() + "살 " + temp.getName());
}
}
}38살 홍길동
41살 김선달
42살 김선달나이순대로 오름차순으로 정렬된것을 확인할 수 있다.
참고 : 박범 블로그
4.4 Comparable 인터페이스와 Comparator 인터페이스
Comparable 및 Comparator인터페이스는 객체들을 정렬하고자 할 때, 정렬의 기준을 만들어주는 인터페이스이다(예 : Member 클래스의 경우 age프로퍼티 기준으로 정렬할지 or 이름 순으로 정렬할지 기준을 만들 수 있다).
Comparable 인터페이스의 경우 public int compareTo(T o)를,
Comparator 인터페이스의 경우 public int compare(T o1, T o2)가 추상 메소드로 정의되어있다.
public int compareTo(T o)의 경우 대입되는 객체 o와 자기자신 this를 비교한 결과를 반환한다. → 객체 자체에 비교 기준을 삽입
public int compare(T o1, T o2)의 경우 자기자신 this를 굳이 쓰지 않고 별도의 기준을 제시할 수 있다. → 다른 객체의 비교방식을 정의 가능
- Comparable 예제
정렬하고자하는 객체인 Member에 Comparable인터페이스를 구현한다(내장).
package comparable.example;
public class Member **implements Comparable<Member>**{
private int id;
private int age;
Member(int id, int age) {
this.id = id;
this.age = age;
}
public int getId() {
return id;
}
public int getAge() {
return age;
}
@Override
**public int compareTo(Member o)** {
// overflow, underflow 될 가능성이 있는 데이터라면, 조건문으로.
return (this.id - o.id);
}
} package comparable.example;
import java.util.*;
public class ComparabeTest {
public static void main(String[] args) {
List<Member> memberList = new ArrayList<Member>();
Iterator<Member> iterator;
memberList.add(new Member(103, 28));
memberList.add(new Member(101, 29));
memberList.add(new Member(105, 30));
memberList.add(new Member(102, 31));
memberList.add(new Member(104, 32));
iterator = memberList.iterator();
System.out.println("--[Before Sorting]--");
while (iterator.hasNext())
{
Member temp = iterator.next();
System.out.println(temp.getId() + " : " + temp.getAge());
}
**Collections.sort(memberList);
iterator = memberList.iterator();**
System.out.println("--[After Sorting]--");
while (iterator.hasNext())
{
Member temp = iterator.next();
System.out.println(temp.getId() + " : " + temp.getAge());
}
}
}--[Before Sorting]--
103 : 28
101 : 29
105 : 30
102 : 31
104 : 32
--[After Sorting]--
101 : 29
102 : 31
103 : 28
104 : 32
105 : 30- Comparator 예제
정렬하고자하는 객체인 Member를 정렬하는 객체인 MyComparator객체를 작성한다. MyComparator는 Comparator인터페이스를 구현한다(외장).
package comparator.example;
public class Member {
private int id;
private int age;
Member(int id, int age) {
this.id = id;
this.age = age;
}
public int getId() {
return id;
}
public int getAge() {
return age;
}
} package comparator.example;
import java.util.Comparator;
public class MyComparator **implements Comparator<Member>** {
@Override
public int compare(Member o1, Member o2) {
return o1.getId() - o2.getId();
}
} package comparator.example;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
public class ComparatorTest {
public static void main(String[] args) {
List<Member> memberList = new ArrayList<Member>();
Iterator<Member> iterator;
memberList.add(new Member(103, 28));
memberList.add(new Member(101, 29));
memberList.add(new Member(105, 30));
memberList.add(new Member(102, 31));
memberList.add(new Member(104, 32));
iterator = memberList.iterator();
System.out.println("--[Before Sorting]--");
while (iterator.hasNext())
{
Member temp = iterator.next();
System.out.println(temp.getId() + " : " + temp.getAge());
}
**MyComparator myComparator = new MyComparator();
Collections.sort(memberList, myComparator);**
iterator = memberList.iterator();
System.out.println("--[After Sorting]--");
while (iterator.hasNext())
{
Member temp = iterator.next();
System.out.println(temp.getId() + " : " + temp.getAge());
}
}
}--[Before Sorting]--
103 : 28
101 : 29
105 : 30
102 : 31
104 : 32
--[After Sorting]--
101 : 29
102 : 31
103 : 28
104 : 32
105 : 30참고 : Stranger's LAB, Heee's Developement
5. Map 인터페이스
5.1 HashMap클래스
HashMap<K, V> 컬렉션은 키(key)와 값(value)의 쌍으로 구성되는 요소를 다룬다. 해시맵 객체의 내부에는 키와 값을 저장하는 자료 구조를 가지고 put() 메서드와 get() 메서드를 이용하여 요소를 삽입하거나 검색한다.
- 예제 코드
package collection.hasmap;
import collection.Member;
import java.util.Iterator;
import java.util.HashMap;
public class MemberHashMap {
private HashMap<Integer, Member> hashMap;
public MemberHashMap() {
hashMap = new HashMap<Integer, Member>();
}
public void addMember(Member member) {
hashMap.put(member.getMemberId(), member);
}
public boolean removeMember(int memberID) {
if (hashMap.containsKey(memberID)) {
hashMap.remove(memberID);
System.out.println(memberID + ": 성공적으로 제거하였습니다.");
return true;
}
System.out.println(memberID + ": 존재하지 않는 아이디입니다.");
return false;
}
public void showAllMember() {
Iterator<Integer> ir = hashMap.keySet().iterator();
while (ir.hasNext()) {
Integer memberId = ir.next();
System.out.println(hashMap.get(memberId));
}
}
} package collection.hasmap;
import collection.Member;
public class HashMapTest {
public static void main(String[] args) {
MemberHashMap memberHashMap = new MemberHashMap();
Member memberLee = new Member(9001, "Lee");
Member memberSon = new Member(3002, "Son");
Member memberHong = new Member(1003, "Hong");
Member memberPark = new Member(1003, "Park");
Member memberLee2 = new Member(7004, "Lee");
memberHashMap.addMember(memberLee);
memberHashMap.addMember(memberSon);
memberHashMap.addMember(memberHong);
memberHashMap.showAllMember();
System.out.println();
memberHashMap.addMember(memberPark);
memberHashMap.addMember(memberLee2);
memberHashMap.showAllMember();
System.out.println();
memberHashMap.removeMember(1005);
memberHashMap.removeMember(3002);
System.out.println();
memberHashMap.showAllMember();
}
} 멤버 id: 9001, 멤버 이름: Lee
멤버 id: 3002, 멤버 이름: Son
멤버 id: 1003, 멤버 이름: Hong
멤버 id: 9001, 멤버 이름: Lee
멤버 id: 3002, 멤버 이름: Son
멤버 id: 1003, 멤버 이름: Park
멤버 id: 7004, 멤버 이름: Lee
1005: 존재하지 않는 아이디입니다.
3002: 성공적으로 제거하였습니다.
멤버 id: 9001, 멤버 이름: Lee
멤버 id: 1003, 멤버 이름: Park
멤버 id: 7004, 멤버 이름: Lee해시맵은 내부적으로 배열로 구현되어 있다. 이 배열의 인덱스, 즉 요소의 위치는 해시함수에 의해 만들어진다. (하지만 리스트나 배열처럼 get(인덱스 번호) 로 접근하는 것은 불가능하다. 요소에 접근하기 위해서는 key 를 사용하여 검색하는 과정을 거쳐야 한다.) 해시함수의 사용은 다음과 같다.
import static java.util.Objects.hash;
// 요소의 인덱스를 정해주는 해시 함수
int index = hash(key);
// hash 함수의 원형
public static int hash(Object... values) {
return Arrays.hashCode(values);
}해시맵은 해시함수가 index = hash(key) 와 같이 간편한 코드로 작성되어 있고, 요소를 삽입하고 삭제할 때 다른 요소들의 위치 이동이 필요 없기 때문에 List<E> 자료형에 비해 빠른편이다. 그리고 get(key) 메서드로 key가 저장된 위치를 바로 반환받을 수 있으므로, 요소의 검색은 더욱 빠른편이다.
해시코드화 된 인덱스로 바로 접근하는 방식을 쓰기 때문에 get(key) 메서드와 containsKey(key) 메서드의 시간복잡도는 O(1) 이라고 한다.
5.2 TreeMap클래스
TreeSet 과 마찬가지로 이진 검색 트리로 구현되어있으며, key 값으로 자료가 정렬된다. key 값으로 정렬하므로 key 값으로 사용하는 클래스에 Comparable 이나 Comparator 인터페이스를 구현해야한다. (정수형 같은 경우는 이미 오름차순으로 구현되어 있으므로 구현할 필요는 없지만 정렬 방법을 바꾸고 싶다면 구현해야한다.)
- 예제 코드
package collection.treemap;
import collection.Member;
import java.util.TreeMap;
import java.util.Iterator;
public class MemberTreeMap {
private TreeMap<Integer, Member> treeMap;
public MemberTreeMap () {
treeMap = new TreeMap<Integer, Member>();
}
public void addMember(Member member) {
treeMap.put(member.getMemberId(), member);
}
public boolean removeMember(int memberID) {
if (treeMap.containsKey(memberID)) {
treeMap.remove(memberID);
System.out.println(memberID + ": 성공적으로 제거하였습니다.");
return true;
}
System.out.println(memberID + ": 존재하지 않는 아이디입니다.");
return false;
}
public void showAllMember() {
Iterator<Integer> ir = treeMap.keySet().iterator();
while (ir.hasNext()) {
Integer memberId = ir.next();
System.out.println(treeMap.get(memberId));
}
}
} package collection.treemap;
import collection.Member;
public class TreeMapTest {
public static void main(String[] args){
MemberTreeMap memberTreeMap = new MemberTreeMap();
Member memberLee = new Member(9001, "Lee");
Member memberSon = new Member(3002, "Son");
Member memberHong = new Member(1003, "Hong");
Member memberPark = new Member(1003, "Park");
Member memberLee2 = new Member(7004, "Lee");
memberTreeMap.addMember(memberLee);
memberTreeMap.addMember(memberSon);
memberTreeMap.addMember(memberHong);
memberTreeMap.showAllMember();
System.out.println();
memberTreeMap.addMember(memberPark);
memberTreeMap.addMember(memberLee2);
memberTreeMap.showAllMember();
System.out.println();
memberTreeMap.removeMember(1005);
memberTreeMap.removeMember(3002);
System.out.println();
memberTreeMap.showAllMember();
}
} 멤버 id: 1003, 멤버 이름: Hong
멤버 id: 3002, 멤버 이름: Son
멤버 id: 9001, 멤버 이름: Lee
멤버 id: 1003, 멤버 이름: Park
멤버 id: 3002, 멤버 이름: Son
멤버 id: 7004, 멤버 이름: Lee
멤버 id: 9001, 멤버 이름: Lee
1005: 존재하지 않는 아이디입니다.
3002: 성공적으로 제거하였습니다.
멤버 id: 1003, 멤버 이름: Park
멤버 id: 7004, 멤버 이름: Lee
멤버 id: 9001, 멤버 이름: Lee트리맵은 배열이 아닌 이진 검색 트리로 구현되어 있기 때문에 해시맵과 달리, get(key) 메서드와 containsKey(key) 메서드의 시간복잡도가 O(log n) 이라고 한다.
