- Elasticsearch 관련 이전 포스팅
1) AWS EC2에 Elasticsearch 설치하기
2) Elasticsearch CRUD 해보기
Elasticsearch를 로컬 환경에서 학습을 목적으로 데이터의 CRUD 과정을 진행해보면 Index, Type, Document, Field, Mapping, QueryDSL와 같은 데이터 처리에 대해서 알게 됩니다.
하지만, 실제 Elasticsearch가 실서비스되는 환경(On-premise or Cloud etc..)에서는 데이터의 유실방지나 고가용성을 위해서 시스템 구조를 이해해야 합니다.
그래서, 이번 포스팅은 Elasticsearch의 시스템 구조를 간단히 포스팅해보려 합니다.
설정에 관련된 상세 옵션이나, 설명들은 공식문서를 찾아보는게 가장 좋으니까요.
Elasticsearch의 시스템 구조는 크게 Cluster, Node, Index, Shard로 구성됩니다.
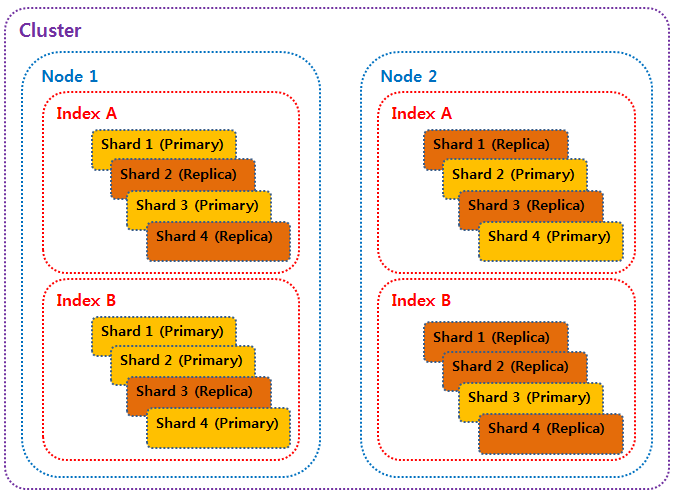 서비스가 동작하고 있는 가장 기본적인 단위인
서비스가 동작하고 있는 가장 기본적인 단위인 Node부터 알아보겠습니다.
1. Node
(1) Node Role
Node는 Elasticsearch가 동작하고 있는 하나의 서버라고 볼 수 있습니다.
이때, Node는 역할(Role)을 지정함으로써 특별한 기능을 하는 Node가 될 수 있습니다.
- master
Master Node
A node that has the master role, which makes it eligible to be elected as the master node, which controls the cluster.
마스터 역할을 하는 노드로, 클러스터를 제어하는 마스터 노드로 선출 될 수 있다. - data
Data Node
A node that has the data role. Data nodes hold data and perform data related operations such as CRUD, search, and aggregations. A node with the data role can fill any of the specialised data node roles.
데이터 역할을 하는 노드로, 데이터를 보유하고 CRUD와 집계를 수행한다. 데이터 역할을 하는 노드는 특수한 데이터 노드 역할을 수행할 수 있다. - data_content
- data_warm
- data_cold
- data_frozen
- ingest
Ingest Node
A node that has the ingest role. Ingest nodes are able to apply an ingest pipeline to a document in order to transform and enrich the document before indexing.
인제스트(삼키는) 역할을 하는 노드로, Indexing(데이터 적재) 전에 Document를 변환하고 보강하기 위해 Document에 수집 파이프라인을 적용할 수 있다. - ml
- remote_cluster_client
- transform
이런 역할(Role)들을 설정하는 방식은 Elasticsearch 버전에 따라 조금씩 다를 수 있습니다.
예를 들어, Master Node를 지정하기 위해 /etc/elasticsearch/config/elasticsearch.yml를 버전별로 아래와 같이 설정할 수 있습니다.
-- Elasticserach 6.8
node.master: true
node.data: false
node.ingest: false
node.ml: false
xpack.ml.enabled: true
cluster.remote.connect: false
-- Elasticsearch 7.12
node.roles: [ master ](역할을 부여하는 버전별 설정 방식은 공식문서에서 확인 하실 수 있습니다.)
2. Cluster
Cluster는 위의 Node들을 묶어서 하나의 Elasticsearch 서비스로 제공하는 것입니다.
예를 들자면, 하나의 Node가 Master Node가 되고, 두 개 이상의 Node가 Data Node로 설정하고 이 Node들을 하나의 서비스로 제공하는 것입니다.
Cluster를 직접 구성해보고 싶으신 경우에는 'Cluster 구성하기'이 포스팅을 참고하시면 될 것 같습니다.
3. Index & Shard
Index는 RDB에서의 DATABASE와 유사한 개념으로 Elasticsearch에서는 논리적인 개념입니다.
Cluster를 이루는 것은 Node이고,
Node를 이루는 것은 Index가 아니라 Shard라는 것입니다.
Index는 Shard(Primary Shard와 Replica Shard)를 가질 수 있는 논리적인 개념일 뿐입니다.
또한, Cluster 구조 내의 Index에서는 최소 하나 이상의 Primary Shard를 가지는 것을 권장합니다.
여기서 Primary Shard란 처음 생성된 Shard이며,
Replica Shard는 Primary Shard의 데이터를 복제한 Shard입니다.
Cluster 구조 안에서 일반적으로 Index를 생성할 때 별다른 설정을 해주지 않는다면
Elasticsearch 7.0 ↑에서는 1개의 Shard,
Elasticsearch 6.x ↓에서는 5개의 Shard로 구성됩니다.
이때, Node가 하나만 있는 경우에는 Replica Shard를 둘 Node가 없기 때문에, 하나의 Node에는 Primary Shard만 존재하게 됩니다.
즉, Elasticsearch 7.0 ↑에서는 1개의 Primary Shard,
Elasticsearch 6.x ↓에서는 5개의 Primary Shard로 구성됩니다.
그래서, Elasticsearch는 각 Node에 Primary Shard와 Replica Shard가 골고루 분산될 수 있게 Cluster에서는 최소 3개 이상의 Node로 구성하는 것을 권장합니다.
4. RDB와의 비교
| RDB | Elasticsearch | Comment |
|---|---|---|
| DATABASE | INDEX | - |
| TABLE | TYPE | Elasticsearch 6.0 버전부터는 Multi Type이 제거되었다. |
| ROW(DATA) | DOCUMENT | - |
| COLUMN | FIELD | - |
| SCHEMA | MAPPING | - |
| INDEX | - | - |
| SQL | QUERY DSL | - |
이번 포스팅에서는 Elasticsearch를 이루는 시스템 구조에 대해 아주 간단히 알아보았습니다.
데이터의 CRUD만 진행해보았는데, 다음 포스팅에서는 1 Cluster(1 Master Node, 3 Data Node)등의 기본적인 구조를 만들어 볼 수 있으면 좋을것 같네요.
해당 글 작성에 참고한 링크
https://www.elastic.co/guide/index.html
https://esbook.kimjmin.net/
