이번 포스팅에서는 카프카 스트림즈를 간단한 예제로 스트림즈 DSL과 프로세서 API를 구현해보려 합니다.
- Kafka 관련 이전 포스팅
1) AWS EC2에 Kafka 설치하기
2) Kafka 스트림즈 알아보기
이런 스토리로 예제를 구현해보겠습니다.
학생들의 시험 성적 데이터를 담고 있는 Topic인 user_score가 있다고 합니다.
하지만 이 시험은 10점을 초과해야만 통과하는 시험이라고 합니다.
그래서 저는 스트림즈를 사용해서 시험에 통과한 학생들의 성적 데이터를 담는 Topic인 pass_user_score에 10점을 넘은 학생들의 시험 성적 데이터만을 담도록 필터링 해보려 합니다.
0. 작업 환경 및 서버 정보
| Name | Main Info | 기타 |
|---|---|---|
| Local OS | macOS Big Sur | - |
| JDK | Ver: 1.8.0_282 | AWS EC2 인스턴스 A |
| Kafka | IP: 54.180.119.14 PORT: 9092 | AWS EC2 인스턴스 A |
| Zookeeper | IP: 54.180.119.14 PORT: 2181 | AWS EC2 인스턴스 A |
1. AWS EC2에 인스턴스 생성하고 접근하기
인스턴스를 생성하고, 카프카를 설치하는 단계를 해보지 않았다면 AWS EC2에 Kafka 설치하기를 참고하세요.
위 포스팅을 참고해서 진행하였다면
주키퍼와 카프카 실행 및 토픽의 생성부터 프로듀서, 컨슈머의 기본적인 명령을 사용하는 경험을 해보았을겁니다.
2. 로컬 환경에서 user_score 토픽 생성하기
로컬 환경에서 아래의 명령이 실행될 수 있는 경로에서 동일하게 명령을 실행합니다.
bin/kafka-topics.sh \
--create \
--bootstrap-server 54.180.119.14:9092 \
--partitions 3 \
--topic user_score1) 토픽 생성 중 time out 오류 발생
Oops... 에러가 발생했습니다.
당황하지 않고, 가장 처음 또는 가장 마지막에 늘 핵심 문구가 적혀있으니 찾아보도록 합시다.
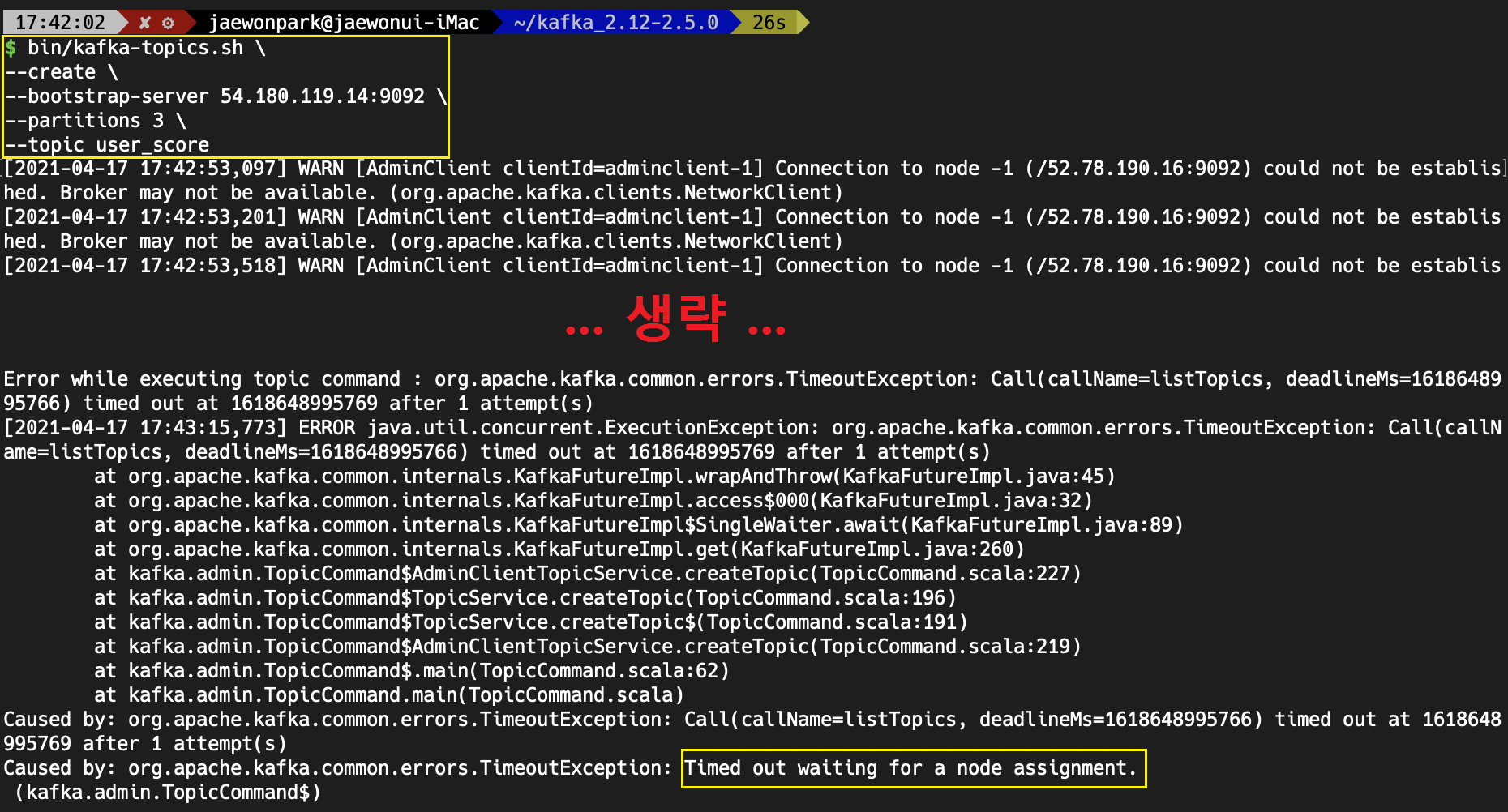 "Timed out waiting for a node assignment."라는 에러 메시지가 적혀 있습니다.
"Timed out waiting for a node assignment."라는 에러 메시지가 적혀 있습니다.
쉽게 말해서 타임아웃이 발생한겁니다.
카프카가 설치된 ip와 port에 접근을 시도는 할 수 있었는데, 연결하는데 타임아웃이 발생한 것이니 뭔가 통신 부분에 문제가 발생했다고 생각이 듭니다.
원인은 제가 이번 포스팅에서 카프카 인스턴스를 새롭게 생성한것이 아닌
이전 포스팅에서 생성했던 인스턴스를 그대로 사용하려고 하다보니 브로커 설정파일(/config/server.properties)의 advertised.listener 옵션이 잘못 설정되어 있음을 알아차렸습니다.
위 포스팅에서의 ip는 54.180.81.28 이었고,
인스턴스를 재실행하면서 새롭게 할당받은 ip는 54.180.119.14 였습니다.
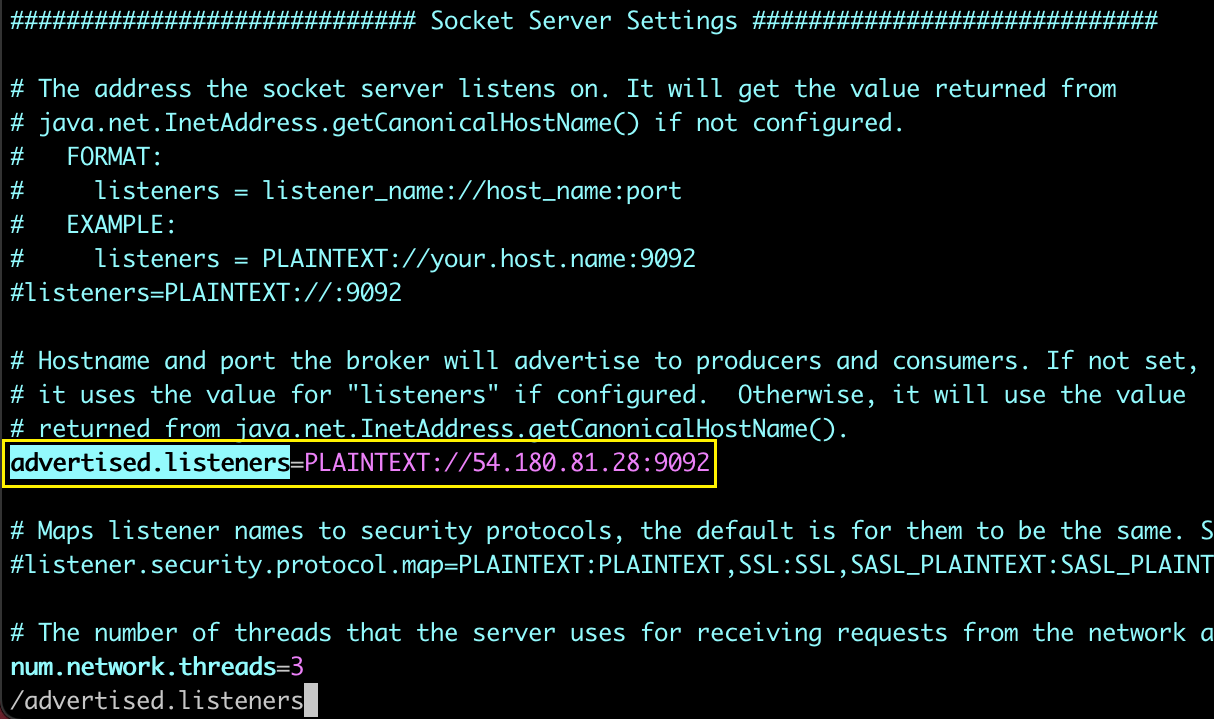 제 ip인 54.180.119.14로 바꿔주고,
제 ip인 54.180.119.14로 바꿔주고,
브로커의 설정파일이 변경되었으니 당연히 카프카도 재실행 해주어야 합니다.
/home/ec2-user/kafka_2.12-2.5.0/bin/kafka-server-start.sh -daemon /home/ec2-user/kafka_2.12-2.5.0/config/server.properties
2) 정상적으로 user_score 토픽 생성
다시 명령어를 입력해봅니다.
bin/kafka-topics.sh \
--create \
--bootstrap-server 54.180.119.14:9092 \
--partitions 3 \
--topic user_score 정상적으로 user_score 토픽이 생성되었다고 합니다.
정상적으로 user_score 토픽이 생성되었다고 합니다.
혹시 모르니, 한번만 확인해보겠습니다.
bin/kafka-topics.sh \
--bootstrap-server 54.180.119.14:9092 \
--list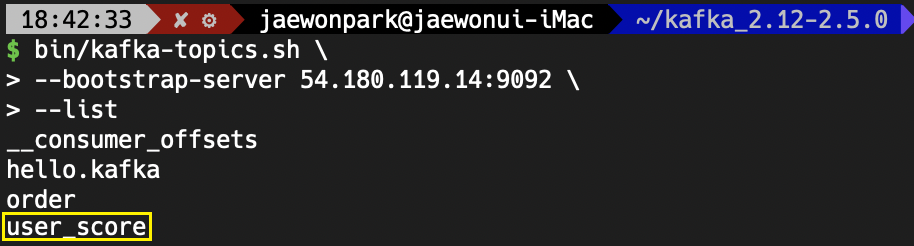 데이터를 가져올 토픽이 생성되었으니, user_score에 데이터를 넣어보도록 하겠습니다.
데이터를 가져올 토픽이 생성되었으니, user_score에 데이터를 넣어보도록 하겠습니다.
여기서, '왜 pass_user_score 토픽은 생성하지 않느냐?'라고 생각하실 수 있습니다.
굳이 생성하지 않은 이유는 카프카의 경우 토픽을 생성하지 않고 데이터를 전송할 때 토픽명을 지정하면 기존에 없는 토픽인 경우에는 기본 설정을 이용하여 토픽을 생성하고 데이터를 저장하기 때문입니다.
3) user_score 토픽에 데이터 produce
아래와 같은 명령어로 4개의 record를 데이터로 집어넣겠습니다.
bin/kafka-console-producer.sh \
--bootstrap-server 54.180.119.14:9092 \
--property "parse.key=true" \
--property "key.separator=:" \
--topic user_score
>jwpark06:15
>wychoi01:20
>gdkim03:8
>jwpark06:3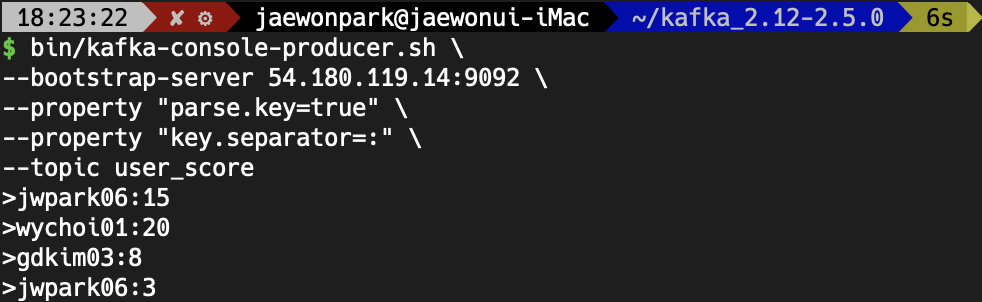 KStream, KTable의 차이는 key에서 발생하는 것이므로,
KStream, KTable의 차이는 key에서 발생하는 것이므로, key:value의 형태로 데이터를 produce하였습니다.
4) user_score 토픽에 데이터 확인하기
아래와 같은 명령어로 현재 user_score 토픽에 들어있는 데이터를 확인해보겠습니다.
bin/kafka-console-consumer.sh \
--bootstrap-server 54.180.119.14:9092 \
--topic user_score \
--property print.key=true \
--property key.separator="-" \
--from-beginning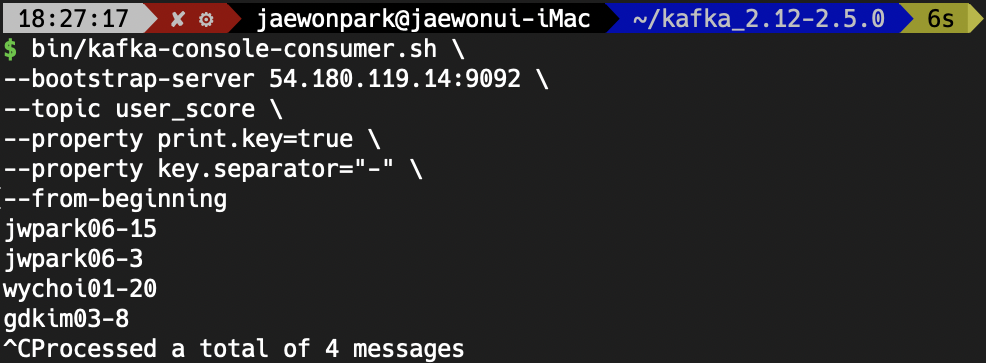 위 사진과 같이 4개의 데이터가 정상적으로 들어있는 것을 확인할 수 있습니다.
위 사진과 같이 4개의 데이터가 정상적으로 들어있는 것을 확인할 수 있습니다.
3. 로컬 환경에서 스트림즈 DSL 애플리케이션 작성하기
아래 예제에서는 소스 프로세서에서 데이터를 가져올 때, KStream으로 데이터를 가져오는 명령어인 .stream() 메서드를 사용하였습니다.
KTable로 데이터를 가져오려면 .table() 메서드를 사용하시면 되며, GlobalKTable로 데이터를 가져오려면 .globalTable() 메서드를 사용하면 됩니다.
1) gradle 프로젝트 생성 및 디펜던시 추가
 위와 같이 gradle 기반의 프로젝트를 생성해준 뒤,
위와 같이 gradle 기반의 프로젝트를 생성해준 뒤,
maven repository에서 kafka-streams를 검색하여 2.5.0 버전에 맞는 dependency를 build.gradle 파일에 복사합니다.

2) 스트림즈 애플리케이션 파일(StreamsFilter.java) 추가 및 코드 작성
main
ㄴ java
-- ㄴ com
---- ㄴ example
------ ㄴ StreamsFilter.java 생성
아래의 자바 코드를 복사하여 본인의 IP와 생성한 토픽명으로 수정하여 작성을 완료합니다.
package com.example;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import java.util.Properties;
public class StreamsFilter {
private static String APPLICATION_NAME = "streams-filter-application"; // 애플리케이션 아이디로 사용할 애플리케이션 이름
private static String BOOTSTRAP_SERVERS = "54.180.119.14:9092"; // 카프카 서버 정보
private static String TOPIC_USER_SCORE = "user_score"; // 카피해올 데이터가 있는 토픽명
private static String TOPIC_PASS_USER_SCORE = "pass_user_score"; // 카피한 데이터를 저장할 토픽명
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
/*
메시지의 키와 값에 직렬화/역직렬화 방식 설정.
스트림즈 애플리케이션에서는 데이터를 처리할 때, 메시지의 키 또는 값을 역직렬화 하고
데이터를 최종 토픽에 전달할 때, 직렬화해서 데이터를 저장한다.
*/
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// 스트림 토폴로지를 정의하기 위한 StreamsBuilder
StreamsBuilder builder = new StreamsBuilder();
/*
- 소스 프로세서 동작
user_score 토픽으로부터 KStream 객체를 만든다.
*/
KStream<String, String> userScore = builder.stream(TOPIC_USER_SCORE);
/*
- 스트림 프로세서 동작
user_score 토픽에서 가져온 데이터 중 value가 10을 넘는 경우의 값만 남도록 필터링하여 KStream 객체를 새롭게 생성
*/
KStream<String, String> filteredStream = userScore.filter(
(key, value) -> Integer.parseInt(value) > 10
);
/*
- 싱크 프로세서 동작
pass_user_score 토픽으로 KStream 데이터를 전달한다.
*/
filteredStream.to(TOPIC_PASS_USER_SCORE);
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}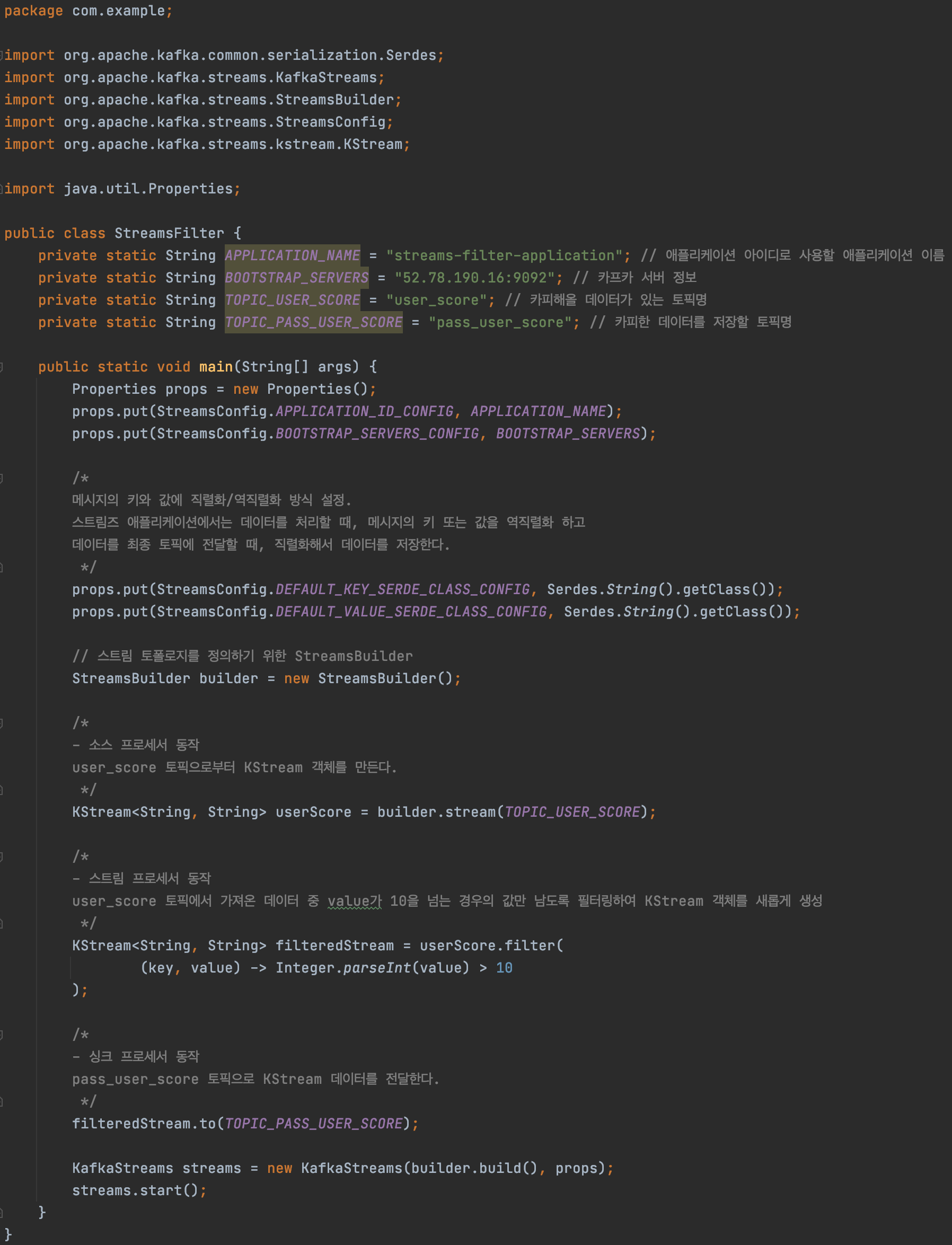 코드 작성을 완료하였다면, 실행하여 봅니다.
코드 작성을 완료하였다면, 실행하여 봅니다.
3) 실행하기
먼저, pass_user_score 토픽이 정상적으로 생성되었는지 확인해보겠습니다.
bin/kafka-topics.sh \
--bootstrap-server 54.180.119.14:9092 \
--list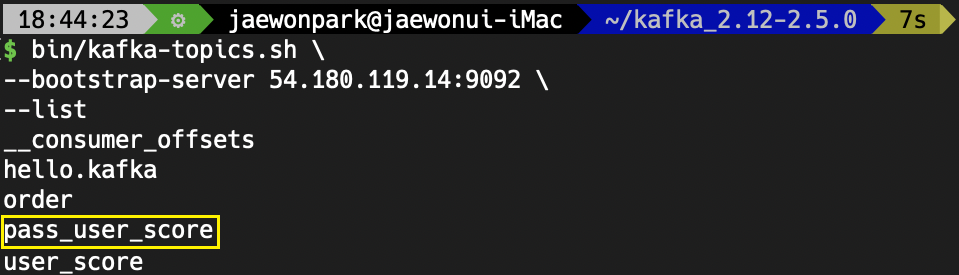 pass_user_score 토픽이 생성된 것을 보니 정상적으로 동작하였을 것 같습니다.
pass_user_score 토픽이 생성된 것을 보니 정상적으로 동작하였을 것 같습니다.
이제, pass_user_score에 아래와 같은 명령을 통해 어떤 레코드들이 들어있는지 확인해보겠습니다.
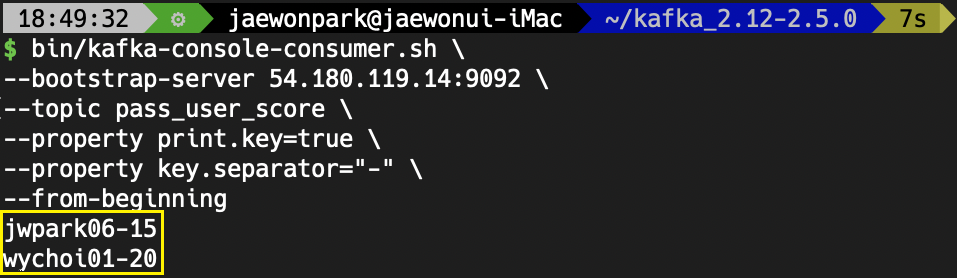 WoW... 10점을 넘은 레코드들만 전달된 것을 확인할 수 있습니다.
WoW... 10점을 넘은 레코드들만 전달된 것을 확인할 수 있습니다.
4. 로컬환경에서 프로세서 API 애플리케이션 작성하기
위의 스트림즈 DSL을 작성할때 사용하였던 Topic인 user_score는 그대로 사용하겠습니다.
똑같은 기능을 프로세서 API로 구현하는 것이기에 소스 프로세서가 데이터를 저장할 토픽명만 pass_user_score2라는 Topic으로 지정하려 합니다.
(죄 짓는 변수명 짓기입니다. 공부하실 때만 이렇게 하세요.)
1) gradle 프로젝트 생성 및 디펜던시 추가
'3 ~ 3-1' 과정에서 gradle 프로젝트를 생성하고 디펜던시를 추가하는 과정을 따라하시면 됩니다.
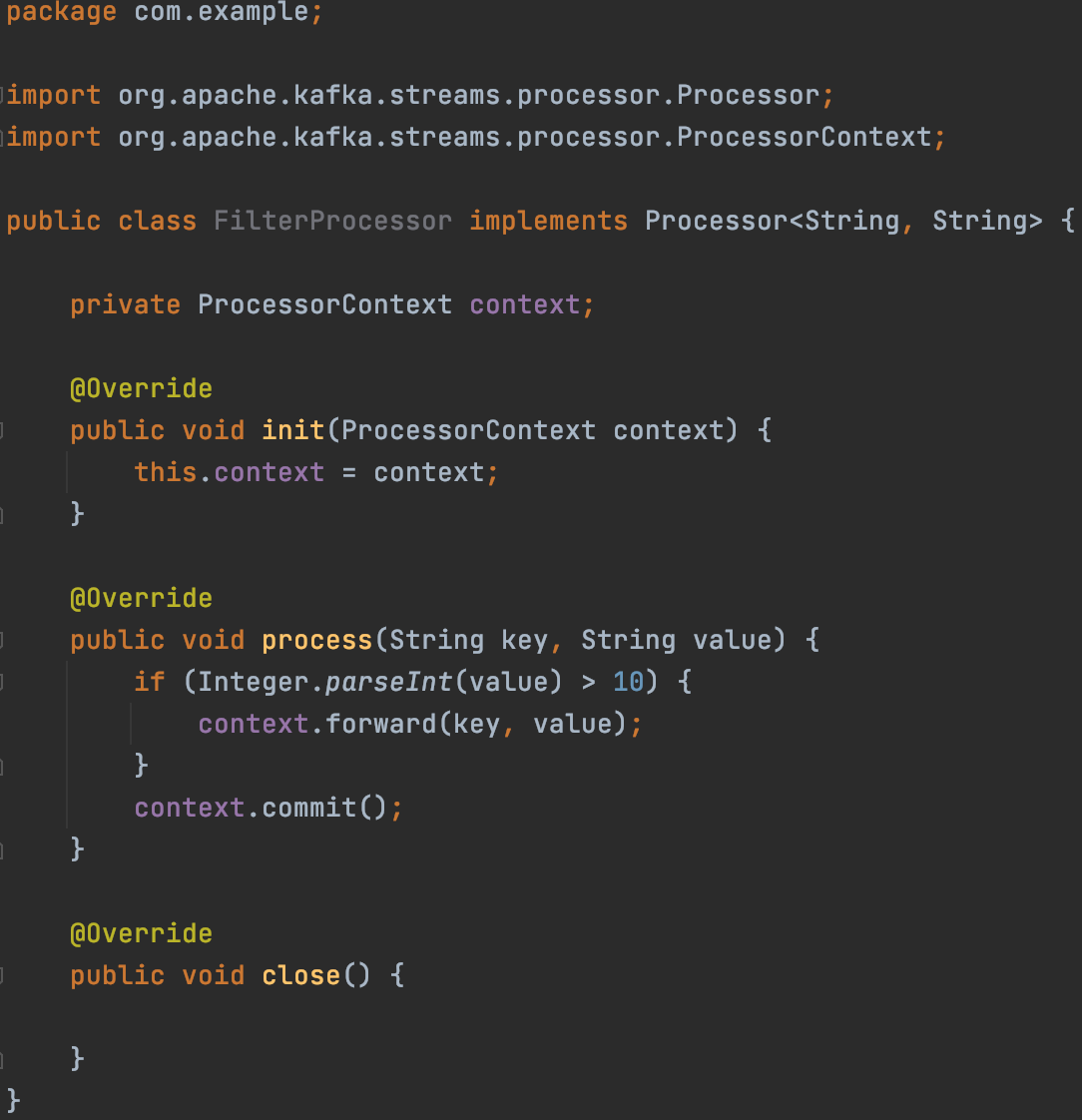
2) 스트림즈 프로세서 클래스(FilterProcessor.java) 생성
package com.example;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorContext;
public class FilterProcessor implements Processor<String, String> {
private ProcessorContext context;
@Override
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public void process(String key, String value) {
if (Integer.parseInt(value) > 10) {
context.forward(key, value);
}
context.commit();
}
@Override
public void close() {
}
}
3) 스트림즈 애플리케이션 실행 파일(SimpleKafkaProcessor) 생성
package com.example;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import java.util.Properties;
public class SimpleKafkaProcessor {
private static String APPLICATION_NAME = "processor-application"; // 애플리케이션 아이디로 사용할 애플리케이션 이름
private static String BOOTSTRAP_SERVERS = "54.180.119.14:9092"; // 카프카 서버 정보
private static String TOPIC_USER_SCORE = "user_score"; // 카피해올 데이터가 있는 토픽명
private static String TOPIC_PASS_USER_SCORE2 = "pass_user_scoøre2"; // 카피한 데이터를 저장할 토픽명
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
/*
메시지의 키와 값에 직렬화/역직렬화 방식 설정.
스트림즈 애플리케이션에서는 데이터를 처리할 때, 메시지의 키 또는 값을 역직렬화 하고
데이터를 최종 토픽에 전달할 때, 직렬화해서 데이터를 저장한다.
*/
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
Topology topology = new Topology();
topology.addSource("Source", TOPIC_USER_SCORE)
.addProcessor("Process", () -> new FilterProcessor(), "Source")
.addSink("Sink", TOPIC_PASS_USER_SCORE2, "Process");
KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
}
}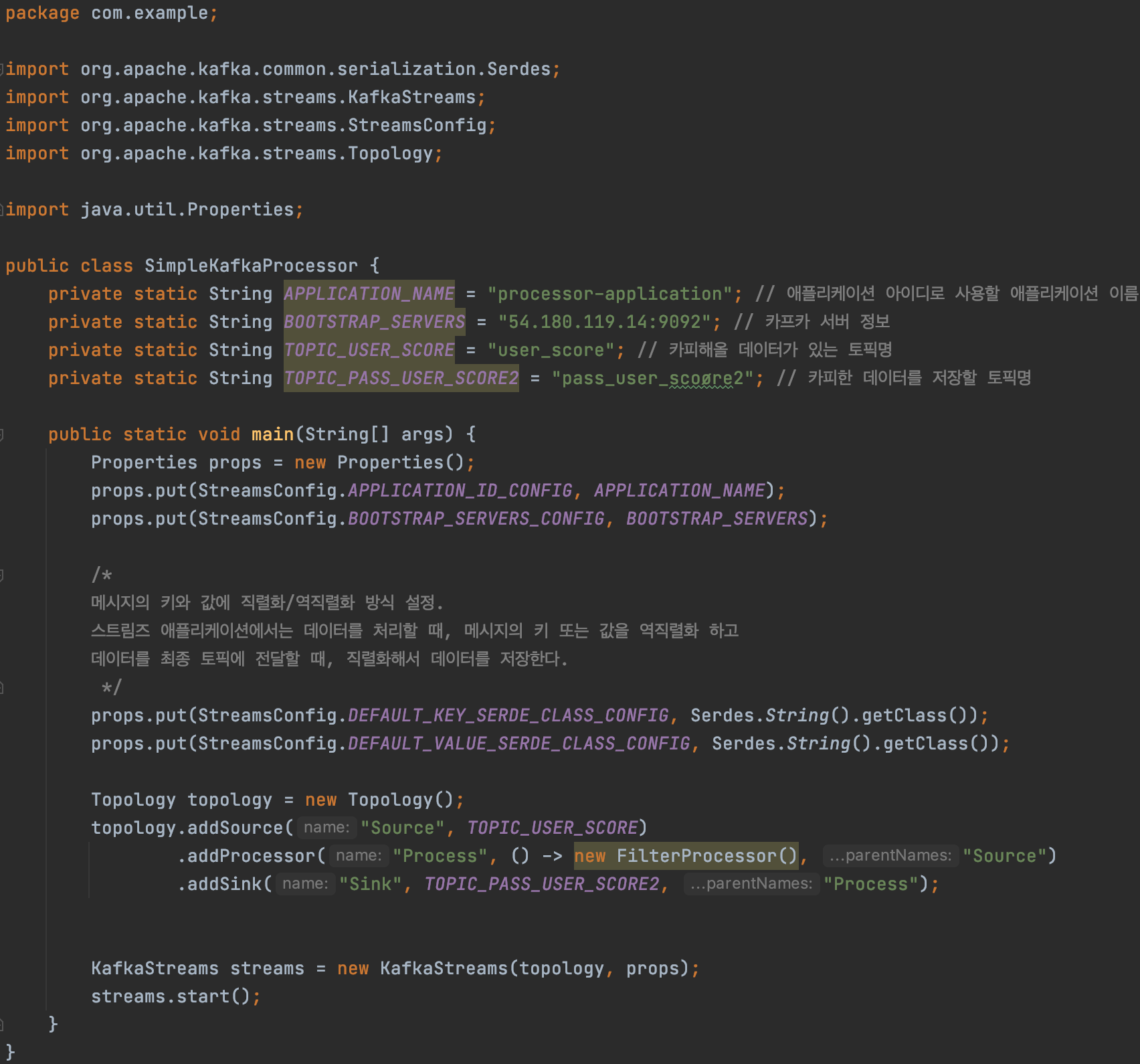 스트림즈 DSL과의 차이점은 아무래도 KStream, KTable, GlobalKTable과 같은 데이터 흐름의 추상화 개념이 없다보니 조금 더 토폴로지 내에서 지정된 메서드들을 호출함으로서 소스 프로세서, 스트림 프로세서, 싱크 프로세서를 간편하게 만들 수 있습니다.
스트림즈 DSL과의 차이점은 아무래도 KStream, KTable, GlobalKTable과 같은 데이터 흐름의 추상화 개념이 없다보니 조금 더 토폴로지 내에서 지정된 메서드들을 호출함으로서 소스 프로세서, 스트림 프로세서, 싱크 프로세서를 간편하게 만들 수 있습니다.
4) 실행하기
먼저, pass_user_score2 토픽이 정상적으로 생성되었는지 확인합니다.
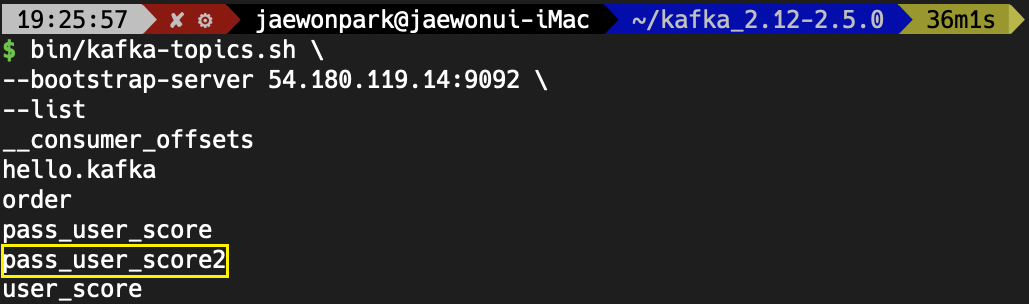 정상적으로 생성되었습니다.
정상적으로 생성되었습니다.
그 다음, pass_user_score2 토픽에 레코드가 정상적으로 들어갔는지 확인해보겠습니다.
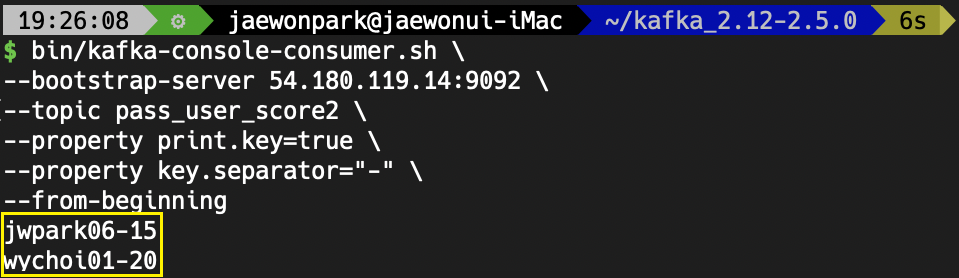 WoW 정상적으로 10점을 초과하는 레코드만 필터링 되었음을 확인할 수 있습니다.
WoW 정상적으로 10점을 초과하는 레코드만 필터링 되었음을 확인할 수 있습니다.
카프카 공부를 하면서 가장 어려웠다고 느꼈던 스트림즈의 구현.
스트림즈 DSL, 프로세서 API를 간단한 스토리의 예제로 구현해보니 무척 뿌듯합니다.
코드를 작성하며 느낀 점이라면,
토폴로지/소스/스트림/싱크 등 각각의 개념도 중요하지만
전체적인 흐름을 이해한다면 두 가지 스트림즈의 구현 방식 모두 빠르게 적용할 수 있을것 같습니다.
해당 글 작성에 참고한 링크
