이번 포스팅은 [도서] 아파치 카프카 애플리케이션 프로그래밍 with 자바를 읽으며 카프카가 장애에 대응하는 여러 방법들이 있다는 것을 한번 정리하고자 포스팅해보았습니다.
이 포스팅은 모든 장애에 대한 대처를 다루지는 않고,
중요하다고 생각되는 레코드(Record), 브로커(Broker), 컨슈머(Consumer), 클러스터(Cluster)와 관련된 장애가 발생할 경우 어떻게 대처가 되어있는지를 다루었습니다.
1. 레코드에 관한 장애에 대처
레코드 단위에서의 장애란
데이터가 제대로 적재되지 않은 경우인 데이터 유실과
데이터가 중복으로 적재된 경우인 데이터 중복을 장애라고 할 수 있다.
이렇게 상상해보자.
쇼핑몰에서 선착순 이벤트에 주문을 하였는데 주문이 되지 않은 경우(데이터 유실)와 한 번 주문했는데 네 번의 주문이 발생하여 네 번의 배송 나가는 경우(데이터 중복)가 발생한다고 상상하면 장애에 대해 이해하기 쉬울 것이다.
카프카는 이러한 레코드 단위의 장애에 대해 프로듀서에서 제공하는 다양한 방법이 있다.
1) acks 옵션
acks 옵션은 0, 1, all (또는 -1)의 값을 가질 수 있다.
acks가 0인 경우 프로듀서는 데이터의 저장이 정상적으로 되었는지 확인하지 않는다.
즉, 데이터의 유실이 발생할 수 있다.
acks가 1인 경우 프로듀서는 데이터를 전달한 리더 파티션까지만 데이터의 저장이 정상적으로 되었는지 확인한다.
즉, '팔로워 파티션에는 데이터가 복제되지 않았을 수도 있다.'라는 가정하에서 리더 파티션이 있는 브로커에 장애가 발생하면 데이터가 아직 복제되지 않은 다른 브로커의 파티션이 리더 파티션이 되면서 데이터의 유실이 발생할 수 있다.
acks가 all인 경우 프로듀서는 데이터를 전달한 리더 파티션 외에도 min.insync.replicas 옵션에 따라 팔로워 파티션까지 데이터의 저장이 정상적으로 되었는지 확인한다.
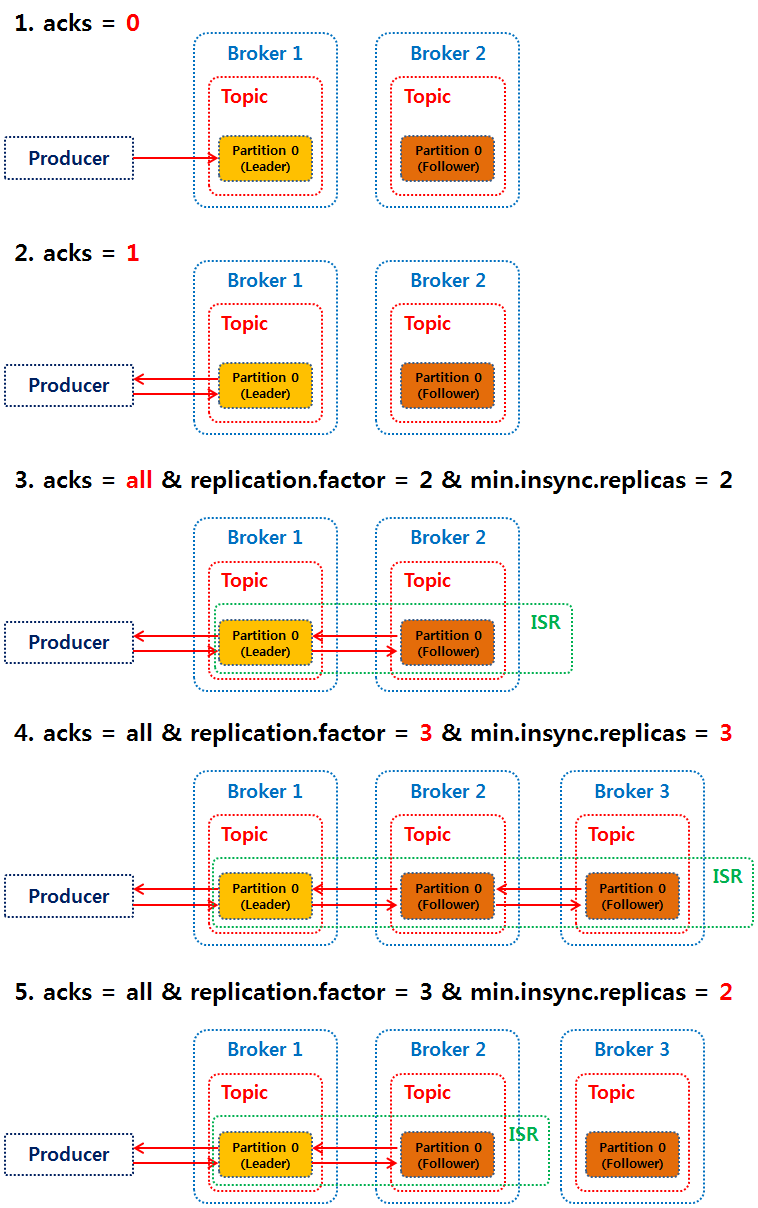 acks가 all 일때, 복제계수(
acks가 all 일때, 복제계수(replication.factor)와 ISR에 포함될 최소 파티션의 수 (min.insync.replicas)가 동일하면 브로커에 장애가 발생시, 최소한의 ISR을 충족하지 못하기 때문에 프로듀서가 더는 데이터를 전송할 수 없게 된다.
그러므로, acks=all을 사용할 때는 replication.factor와 min.insync.replicas 값의 설정에 주의한다.
2) 멱등성 프로듀서
멱등성 프로듀서는 데이터를 정확히 한번 전달하기 위해 enable.idempotence 옵션을 제공한다.
enable.idempotence = false가 기본값이며, 데이터를 정확히 한번 전달하는 옵션을 사용하지 않는다.
즉, 데이터의 중복이 발생할 수 있다.
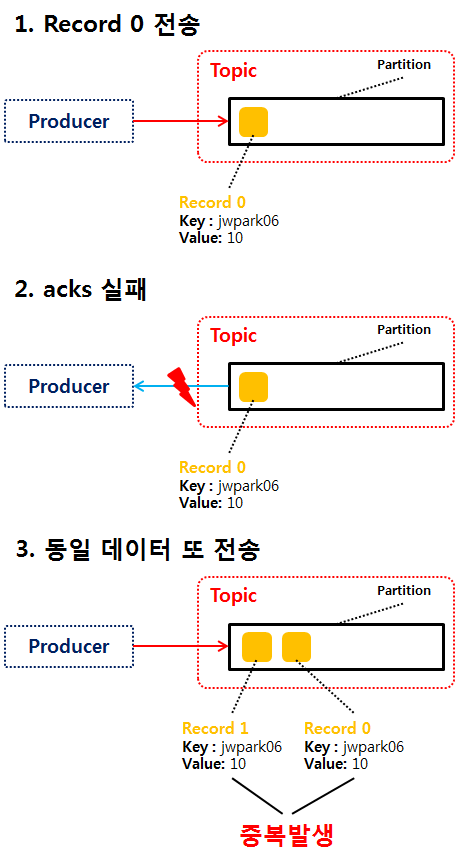
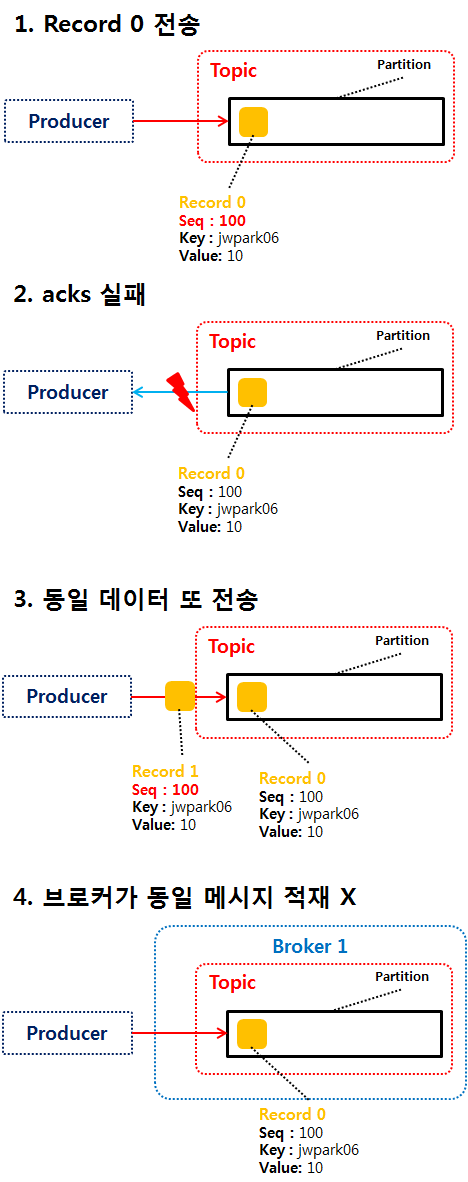
enable.idempotence = true 설정시, 데이터를 정확히 한번 전달한다.
이때, 멱등성 프로듀서에서 전달하는 데이터에는 현재 프로세스의 id인 PID와 현재 전달될 데이터의 시퀀스 번호인 seq가 같이 전달된다.
이 밖에, 트랜잭션 프로듀서라는게 있는데 이 부분이 궁금하다면 직접 구글링해보도록한다.
2. 브로커에 관한 장애 대처
일반적으로 클러스터의 다수 브로커 중 한 대의 브로커는 컨트롤러의 역할을 하게 된다.
클러스터의 브로커 중 컨트롤러가 아닌 브로커에 장애 발생시, 컨트롤러는
① 클러스터의 다른 브로커의 상태를 체크하고
② 장애가 발생한 브로커에 존재하는 리더 파티션을 다른 브로커로 재분배한다.
③ 그리고 나면 새롭게 선출된 리더 파티션을 가진 브로커의 정보를 클러스터 내의 모든 브로커로 전달한다.
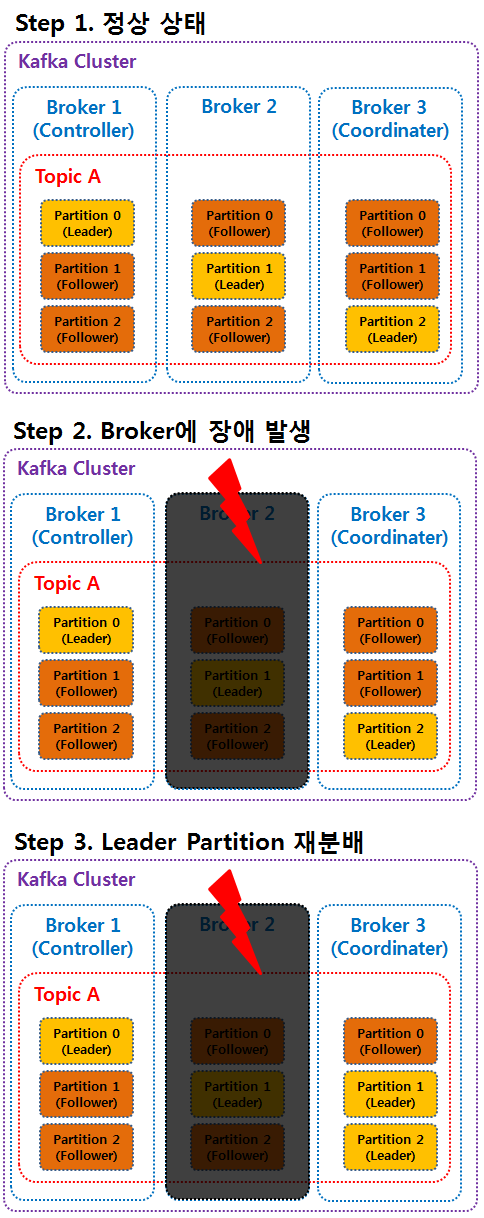 만약 컨트롤러인 브로커에 장애가 발생하면 주키퍼의 설정에 따라 새로운 컨트롤러를 선출한다.
만약 컨트롤러인 브로커에 장애가 발생하면 주키퍼의 설정에 따라 새로운 컨트롤러를 선출한다.
이 부분은 참고 링크를 통해 추가적인 내용을 확인하시면 됩니다.
3. 컨슈머에 관한 장애 대처
일반적으로 클러스터의 다수 브로커 중 한 대의 브로커는 코디네이터의 역할을 하게 된다.
컨슈머 그룹의 컨슈머가 장애 발생 시, 코디네이터는
① 컨슈머 그룹의 상태를 체크하고
② 장애가 난 컨슈머가 할당받은 파티션을 동일 컨슈머 그룹 내의 (정상동작하는) 컨슈머에 재할당되도록 분배한다. 이러한 재할당 과정을 리밸런스(Rebalance)라고 한다.
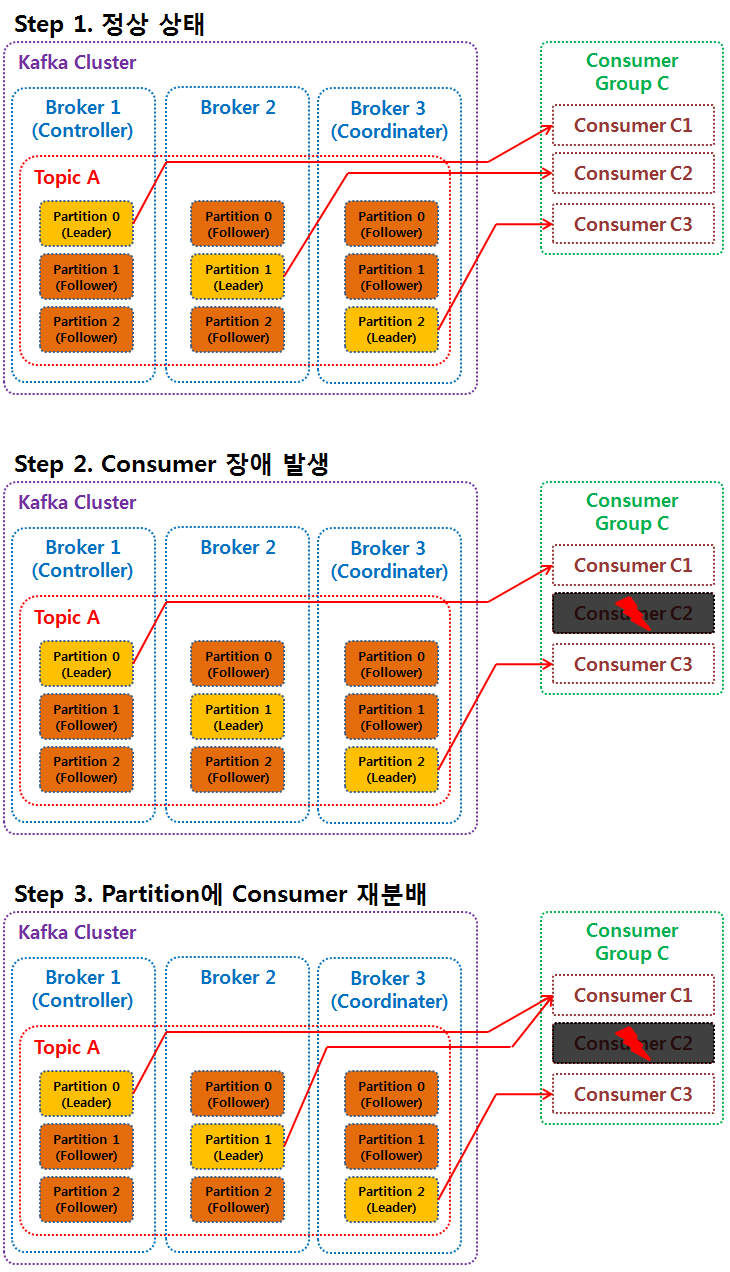 장애가 발생한 컨슈머가 처리했던 데이터가 어디까지 처리되었는지는 offset 개념을 찾아보도록 한다.
장애가 발생한 컨슈머가 처리했던 데이터가 어디까지 처리되었는지는 offset 개념을 찾아보도록 한다.
4. 클러스터에 관한 장애 대처
카프카는 클러스터의 장애에 대처할 수 있도록 미러메이커2(MirrorMaker2)라는 애플리케이션을 활용할 수 있다.
미러메이커2는 서로 다른 두 개의 카프카 클러스터 간에 토픽을 복제하는 애플리케이션이다.
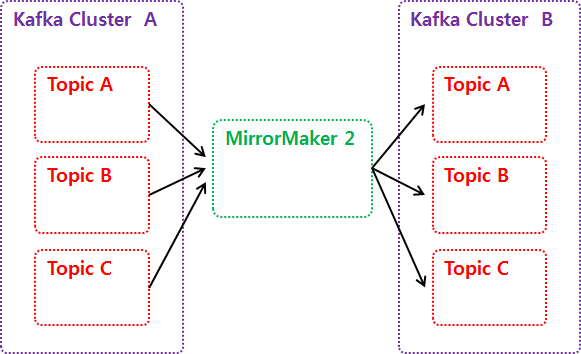 위 사진은 클러스터 A의 토픽들을 클러스터 B로 복제하는 단방향 토픽 복제를 예로 들었다.
위 사진은 클러스터 A의 토픽들을 클러스터 B로 복제하는 단방향 토픽 복제를 예로 들었다.
하지만, 미러메이커2는 미러케이커2의 설정파일의 일부 설정을 수정하면 양방향 토픽 복제도 가능하다.
또한, 미러메이커2라는 것은 미러메이커1이 있다는 이야기이다.
어떤 점을 보완하여 미러메이커2가 나왔는지 궁금하다면, 이 포스팅과 이 포스팅을 참고한다.
해당 글 작성에 참고한 링크

알기 쉽게 정리해 주셔서 감사합니다!