Integer를 비교할 때는 무엇을 사용해야 하는가??
보통 Integer 와 같은 Wrapper class는 자료구조에서 타입을 명시할 때 가장 많이 사용하곤 한다. 특히 코딩테스트라던가 로직상 값을 비교할 때 아무 생각없이 사용하는데 이는 큰 문제를 만들 수 있다는 것을 알게 되었다.
HashMap<Integer, Integer> hm = new HashMap<>();
hm.put(key1, 100);
hm.put(key2, 100);
if(hm1.get(key1) == hm.get(key2)) ~~~~위와 같은 단순한 조건문이 있다고 생각해보자. 우리는 당연하게도 객체의 비교는 .equals() 메소드를 사용해야 하는 것을 알고 있다. 그러나 사람은 언제나 망각의 동물이다. 아무 생각 없이 == 연산자를 사용했다가 원하는 결과가 안나오게 되면 그제서야 코드를 수정하러 가는 것이다.
하지만 문제는 위 코드는 원하는 결과가 나와 버린다는 것이다.
잘못 작성한 비교문이 테스트 코드에서 true 를 반환하고 아! 문제가 없구나 하고 넘어가버린다면??
Java Integer caching
왜 true 가 반환되는 것인가. 객체의 비교는 객체 주소, 즉 참조값을 비교한다. 동일한 객체라면 주소가 같으므로 == 연산이 true 라는 것이다. 앞서 위 결과가 true 라고 말했다. 그렇다는 뜻은
key1, key2 의 Integer 주소가 같다는 뜻이다.
이 부분을 이해할려면 Java에서 제공하는 Integer caching 을 알아야 한다.
Integer class는 IntegerCache를 관리하는데 -128 ~ 127 범위의 Integer 는 캐싱하여 사용한다는 뜻이다.
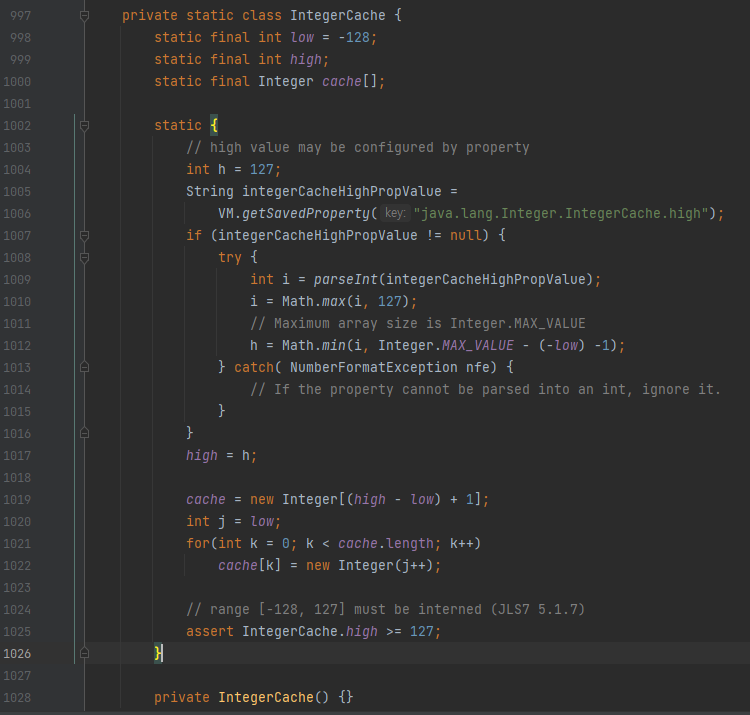
위 코드는 Integer 내부의 static class 이다. 캐시 범위의 low, high 가 -127, 128로 저장되어 있다. 이후 line 1019 ~ 1022 를 확인해보면 해당 범위에 미리 new Integer로 객체를 할당하는 것을 확인할 수 있다. 결국 해당 범위에 속하는 값이라면 새로운 객체를 생성하는 것이 아닌 미리 저장한 객체를 사용하는 것이다.
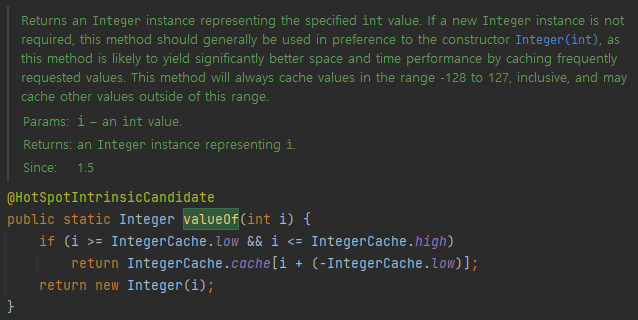
Integer 의 경우 값을 반환할 때 valueOf() 메소드를 사용한다. 해당 메소드의 설명을 읽어보자 단순히 코드를 확인해보면 캐싱 범위일 경우 기존에 존재하는 배열에서 객체를 반환하고
아니라면 new Integer(i) 로 반환하는 것을 확인할 수 있다.
지정된 int 값을 나타내는 Integer 인스턴스를 반환합니다. 새 Integer 인스턴스가 필요하지 않은 경우 이 방법은 일반적으로 생성자 Integer(int)보다 우선적으로 사용되어야 합니다. 이 방법은 자주 요청되는 값을 캐싱하여 훨씬 더 나은 공간 및 시간 성능을 제공할 가능성이 높기 때문입니다. 이 메서드는 항상 -128에서 127까지의 범위에 있는 값을 캐시하고 이 범위 밖의 다른 값을 캐시할 수 있습니다.
아하! 이제서야 의문이 해결될 수 있다. 제일 처음에 작성한 HashMap 의 Integer가 해당 캐싱 범위에 존재하기 때문에 == 연산이 가능했던 것이다!

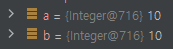
실제로 Integer 객체를 생성하여 주소값을 확인해보면 캐싱 범위일 경우 Integer@716 이라는 동일한 주소값을 가진다.

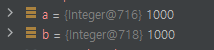
그러나 캐싱 범위가 넘어가면 위와 같이 다른 주소값을 가지는 것을 볼 수 있다.
하지만 사칙 연산의 경우 또 다르게 생각해야 한다
우리는 앞서 Integer class 를 뒤적거린 덕분에 깔끔하게 == 연산이 가능했던 이유를 알게 되었다. 그러나 또 다른 생각할 점이 있다. 만약 두 Integer class 에 사칙연산을 적용하여 비교한다면???
Integer a = 1000;
Integer b = 1000;
if(a - b == 0) sout ~~~~위 결과는 무엇을 반환할까?? 정답은 true 이다. 생각해보면 당연하다. 일반적으로 객체 사칙 연산은 에러를 반환한다. 따로 해당 부분을 처리하는 메소드가 존재하지 않는다면 말이다. 하지만 Integer 와 같은 class는 당연히 auto-unboxing 으로 연산을 처리한다. 이제는 이 객체의 주소는 상관없다. 우리는 해당 객체가 가지고 있는 값만 연산할거니까!
왜 하필 -128 ~ 127 일까?
하나를 해결하면 또 다른 의문점이 생기는 법이다. 아니 캐싱하는 방식은 알겠다. 근데 왜 하필 저 범위냐? 라는 생각이 떠나질 않는다. 위에서 valueOf() 메소드에서는 자주 요청되는 값 을 기준으로 설정했다고 말한다.
아니 사용하는 범위는 주관적인 것 아닌가? 아니면 Java 구버전 시대 컴퓨터 스펙으로는 저 범위가 최선이었던 것일까?? 다시 또 찾으러 가는 수 밖에 없다...
이곳 저곳 구글링하면서 찾은 답변은 다음과 같다.
The reason for caching small integers, if that's what you're asking, is that many algorithms use small integers in their calculations, so avoiding the object-creation overhead for these values tends to be worthwhile.
-> 많은 알고리즘이 작은 값을 계산한다! object creation 부하를 방지하기 위해 큰 값을 설정하지 않는다!
그렇다면 캐싱되는 정수는 대체 무엇인가? 상수를 생각해보자 흔히 논리값과 유사하게 사용하는 상수값은 0, 1 이다. 우리가 상수를 1000, 100000, 989999 를 자주 사용하지는 않기 때문이다. 이와 같은 논리로 캐싱 범위는 설정되었다. 물론 임의적일수 있다.
이상적으로는 주어진 기본 값 p를 박싱하면 항상 동일한 참조가 생성됩니다. 실제로 이것은 기존 구현 기술을 사용하여 실현 가능하지 않을 수 있습니다. 위의 규칙은 실용적인 절충안입니다. 위의 마지막 절에서는 특정 공통 값이 항상 구분할 수 없는 개체에 포함되도록 요구합니다. 구현은 이를 게으르게 또는 적극적으로 캐시할 수 있습니다. 다른 값의 경우 이 공식은 프로그래머 측에서 boxed 값의 ID에 대한 가정을 허용하지 않습니다. 이렇게 하면 이러한 참조의 일부 또는 전부를 공유할 수 있습니다(필수는 아님).
이렇게 하면 대부분의 일반적인 경우에 특히 작은 장치에서 과도한 성능 저하 없이 동작이 원하는 동작이 됩니다. 예를 들어 메모리 제한이 덜한 구현은 -32K에서 +32K 범위의 int 및 long 값뿐만 아니라 모든 char 및 short 값을 캐시할 수 있습니다.
https://docs.oracle.com/javase/specs/jls/se7/html/jls-5.html#jls-5.1.7
결국 일반적인 상황에서 해당 값이 가장 이상적이었다. 라는 결론이다. 물론 사용자가 임의로 범위를 설정할 수 있다곤 한다. 그러나 내가 그 부분까지 설정할 일은 없으리라 생각한다.
아 추가적으로 이러한 캐싱은 Integer 뿐만 아니라 Byte, Short, Long, Character 모두 해당되는 이야기이다. Float, Double 같은 경우 실수 범위 예측이 어려워 해당되지 않는다고 한다 :)
결론
- Integer 와 같은 Wrapper class 는 값 캐싱을 지원한다.
Float, Double 제외 - 해당 범위의 동일한 값이라면 미리 생성한 객체를 반환하기 때문에 == 연산이 true 가 된다
- 사칙 연산의 경우 auto-unboxing 이 이뤄지기 때문에 a - b == 0 과 같은 비교는 true 가 된다.
