들어가며
드디어 KoBART를 활용한 카카오톡 대화 요약 서비스의 마지막 포스팅이다. 이번에 다룰 주제는 Flask를 활용한 서빙이다. 웹 구현, 서빙을 위한 전처리, 간단한 화면 구현, Dockerfile을 활용한 Docker build를 알아보도록 하겠다.
1. 서빙을 위한 전처리
가장 많이 고민을 한 파트를 뽑으라면 당연 전처리를 뽑을 것이다. 이유는 고객의 입장에서 최대한 사용하기 편리하게 만들기 위해서이다.
(1) 웹에서 카카오톡 대화 복사 붙여넣기
첫 번째로 고려할 대상은 웹에서 카카오톡 대화를 복사 붙여넣기를 할 때 데이터의 형식이 모델을 학습할 때와 다른다는 것이다. 데이터의 형식은 아래와 같다.
[이름][시간] 대화내용
[이름][시간] 대화내용
[이름][시간] 대화내용
위의 데이터에서 [이름][시간]을 빼고 "대화내용[sep]대화내용[sep]대화내용" 이러한 형식으로 전처리를 해주는 것이 첫 번째 과제였었다. 이는 split(',')를 통해서 해결할 수 있었다. 그다음 각각의 대화 내용을 리스트에 담기 위해서 for문을 통해서 입력받은 각 대화 내용을 append를 통해 리스트에 담을 수 있었다.
(2) 삭제된 메시지입니다. & 이모티콘
대화를 그대로 복사 붙여넣기를 하면 이모티콘 부분이 있다. 이는 "[이름][시간] 이모티콘"으로 입력되기 때문에 추상 요약에 있어서 요약이 조금 부자연스러운 현상을 겪기도 하였다. 반대로 진짜로 이모티콘에 관해서 대화를 한 내용일 경우에는 이를 전처리 하였을 때 문장의 핵심을 표현하는 중요한 토큰을 잃게 되는 것이다. 그리고 전혀 다른 문장으로 요약되었다. 그렇기 때문에 결론적으로 "이모티콘" 이 들어가는 경우가 왜곡도 덜하다고 판단되어 "이모티콘"은 전처리 하지 않기로 결정하였다.
"삭제된 메시지입니다."의 경우는 고객이 삭제하고 싶었던 내용이므로 삭제했다는 표현조차 불필요한 데이터로 판단되어 전처리를 진행하였다.
(3) 전처리 속도
원래는 run.py에서 곧바로 for문을 활용하여 전처리를 진행하였었다. 이는 10초라는 시간이 걸렸다. 그래서 for문을 함수에 넣어 동작시킴으로 0.5초로 시간을 단축할 수 있었다.
(4) 코드 - preprocessor.py
import re
def preprocess_sentence(sentence, v2=False):
if v2==False:
#sentence = sentence.lower() # 텍스트 소문자화
sentence = re.sub(r"삭제된 메시지입니다.", "", sentence)
sentence = re.sub(r'[ㄱ-ㅎㅏ-ㅣ]+[/ㄱ-ㅎㅏ-ㅣ]', '', sentence) # 여러개 자음과 모음을 삭제한다.
sentence = re.sub(r'\[.*?\] \[.*?\]', ',', sentence) # 여러개 자음과 모음을 삭제한다.
sentence = re.sub(r"[^가-힣a-z0-9#@,-\[\]\(\)]", " ", sentence) # 영어 외 문자(숫자, 특수문자 등) 공백으로 변환
sentence = re.sub(r'[" "]+', " ", sentence) # 여러개 공백을 하나의 공백으로 바꿉니다.
#sentence = sentence.strip() # 문장 양쪽 공백 제거
sentence = sentence.split(',')
if v2 :
#sentence = re.sub(r'\[[^)]*\]', '', sentence)
sentence = sentence.strip() # 문장 양쪽 공백 제거
return sentence
def remove_empty_pattern(text_list): # 빈 ''가 발생하여 [sep]가 중복되는 경우가 생겨서 이를 제거하기 위함
return [x for x in text_list if x.strip() != '' ]#and not re.search(r'^\'\'$', x)
def preprocess_result(sentence, v2=True):
result = []
for i in range(len(sentence)):
result.append(preprocess_sentence(sentence[i], v2).lower())
return result2. 화면구현
(1) 소개
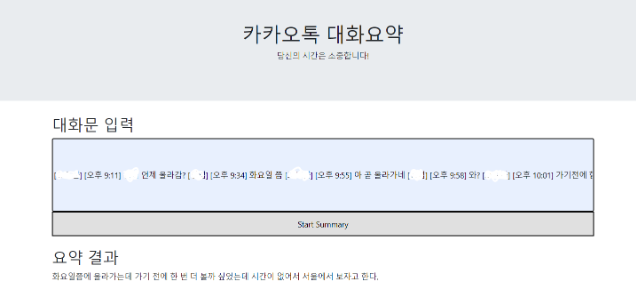
화면 구현은 bootstrap4의 탬플릿을 활용하여 input data를 받아 전처리 및 추상 요약을 진행하고 이 결과를 output data를 출력할 수 있도록 구현하였다.
(2) 코드 - templates/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>dialog text summary</title>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@4.6.2/dist/css/bootstrap.min.css">
<script src="https://cdn.jsdelivr.net/npm/jquery@3.6.1/dist/jquery.slim.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/popper.js@1.16.1/dist/umd/popper.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@4.6.2/dist/js/bootstrap.bundle.min.js"></script>
<style>
.fakeimg{
height: 200px;
background: #FFFFFF;
}
.text_input {
height: 150px;
width: 100%;
background: #FFFFFF;
}
.submit_button{
width: 100%;
height: 50px;
background: #E0E0E0;
}
</style>
</head>
<body>
<div class="jumbotron text-center" style="margin-bottom:0">
<h1>카카오톡 대화요약</h1>
<p>당신의 시간은 소중합니다!</p>
</div>
<div class="container" style="margin-top:30px">
<div class="row">
<div class="col-sm-12">
<div>
<h2>대화문 입력</h2>
<form method="POST" class="fakeimg" >
<input class="text_input" type="text" name="size" placeholder="text input"/><br>
<input class="submit_button" type="submit" value="Start Summary"/>
</form>
</div>
<br>
<h2> 요약 결과</h2>
<div class="fakeimg">{{text_output}}</div>
<br>
</div>
</div>
</div>
<div class="jumbotron text-center" style="margin-bottom:0">
<p>KoBart Summary</p>
</div>
</body>
</html>3. 실행
(1) 소개
입력받은 대화 내용을 전처리 후 HuggingFace에 업로드한 모델을 통해 추상 요약을 진행하여 그 결과를 다시 화면에 출력할 수 있도록 구현하였다. 실행을 위해서는 python run.py를 입력하면 된다.
(2) 코드 - run.py
from flask import Flask, render_template, request
from transformers import pipeline
from preprocessor import preprocess_sentence, preprocess_result, remove_empty_pattern
#from time_check import do_something
import math
import time
app = Flask(__name__)
model_name = "jx7789/kobart_summary_v3"
gen_kwargs = {"length_penalty": 1.2, "num_beams":8, "max_length": 128}
@app.route('/', methods=['GET','POST'])
def home():
#do_something()
text_input = False
text_input = str(request.form.get('size'))
if text_input:
result = preprocess_sentence(text_input)
result = remove_empty_pattern(result)
result = preprocess_result(result) #내 생각과는 다르게 사용을 하지 않아도 [이름][시간]다 제거되었음,
#start = time.time()
#print(result)
pipe = pipeline("summarization", model=model_name)
text_output = pipe('[sep]'.join(result), **gen_kwargs)[0]["summary_text"]
#end = time.time()
#print("걸린시간",end - start)
#print("test하기",text_output)
return render_template('index.html', text_output=text_output)
if __name__ == '__main__':
app.run(host="0.0.0.0", port=int(3000), debug=True)4. 도커 빌드
(1) 소개
도커에 쉽게 빌드 할 수 있도록 Dockerfile을 만들었다. 사용법은 아래와 같다.
docker build -t flask .
docker run -d -p 3000:3000 flask(2) 코드 - Dockerfile
FROM python:3.9.4
WORKDIR /app
COPY . /app
RUN apt update
RUN apt install python3-pip -y
RUN pip3 install Flask
RUN pip3 install transformers==4.25
RUN pip3 install torch==1.13
EXPOSE 3000
CMD python ./run.py5. 최종 결과

다음은 성능 향상을 위한 여러 기법을 제시할 때마다 다음과 같이 성능을 향상하고 있는 것을 알 수 있을 것이다. 다만 참고할 점은 5% 데이터를 사용하였기 때문에 변화의 추이만 살펴보고 여기에 표시된 rouge는 최종 실제 모든 데이터로 학습할 때의 데이터가 아닌점을 감안해주었으면 좋겠다.

마치며
서빙을 위해 Flask를 활용하여 간단히 웹 구현 및 도커 빌드를 함으로써 KoBART를 활용한 카카오톡 대화 요약 서비스 프로젝트를 마칠 수 있었다. 다음에는 새로운 프로젝트로 다시 돌아오도록 하겠다.
github로 이동 : KoBART를 활용한 카카오톡 대화 요약 서비스
