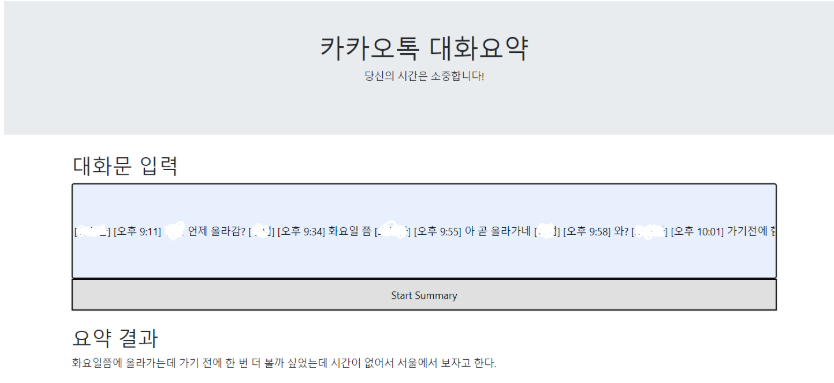
들어가며
카카오톡은 대한민국 국민에게는 빼놓을 수 없는 삶의 일부가 되었다. 통계적으로는 대한민국 국민의 98%가 사용을 한다고 한다. 친구들과의 모든 대화를 카톡으로 이어나가기도 하고, 또 업무도 일정 부분 카톡으로 대화를 하기도한다. 즉, 카카오톡의 활용도가 높다는 것이다.
그렇기 때문에 카카오톡 대화를 요약해주는 서비스가 필요할 것이라고 생각되었다. 이는 업무 관련 내용을 정리해주고, 친구들과 대화를 핵심만 요약해서 정리할 수 있을 것이다. 그래서 이 카카오톡 대화 요약 서비스라는 프로젝트를 진행하게 되었다.
목차
- 모델소개
- 추출 요약 vs 추상요약
- 데이터
1) 데이터 소개
2) 전처리
3) 간단한 EDA - 토큰화
1) 스폐셜 토큰 기법 사용
2) Meta Data 기법 사용
3) 토크나이저 - 모델링
1) fine-tuning
2) MLM기법으로 도메인 적응 - 평가지표
- 생성전략
1) Sampling
2) Beam Search - 허깅페이스 업로드
- 모델 서빙
1) Flask로 웹구현
2) Docker 업로드 - 결과 예시
1. 모델 선정
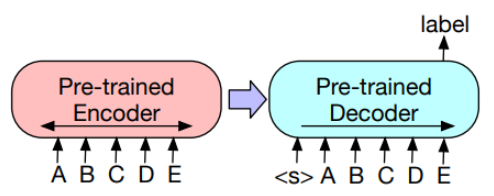
BART는 특정 task가 아닌 다양한 task에 적용할 수 있도록 seq2seq 구조로 만들어진 denoising auto-encoder이다. Encoder에서는 BERT와 같은 구조를, Decoder에서는 GPT와 같은 구조를 가지고 있어 BART는 손상된 text를 입력받아 bidirectional 모델로 인코딩하고, 정답 text에 대한 likelihood를 autoregressive 디코더로 계산한다.
확률은 최대 우도 추정법(Maximum Likelihood Estimation, MLE)과 같은 추정 방법에서 자주 사용된다. 이 방법에서는 주어진 데이터에 대해 확률을 최대화하는 모델 파라미터 값을 찾으려고 한다. 이렇게 하면, 가장 적합한 파라미터 값이 추정되어 모델의 예측 성능이 향상될 수 있다.
결론적으로 Encoder에서 대화문의 특성을 학습하고 이를 바탕으로 Decoder 에서 자귀 회귀적으로 생성하기 때문에 자연어 이해와 생성 모두 필요한 생성 요약에서 BART가 적합하다고 판단되었다.
2. 추출 요약 vs 추상요약
추출 요약은 문장에서 모델이 핵심이라고 판단하는 부분을 발췌하는 형식이다. 반면 추상요약은 핵심 모델이 핵심되는 문맥을 파악해 문장을 생성해내는 것이다. 그렇다면 카카오톡 대화는 추출 요약으로 진행해야할까? 추상 요약으로 진행해야할까? 필자의 경우는 대화문의 경우는 추상 요약을 해야한다고 판단했다.
이유는 간단하다. 추출 요약의 경우는 문장이 완성되어 있고, 정보가 변조되면 안되는 전문 지식 데이터일 때 추출 요약을 통해서 그대로 요약 하면 될 것이다. 반대로 대화 데이터는 하나의 문장으로 완성되어 있지 않기 때문에 오고가는 여러 대화 데이터의 핵심을 간추려 새로운 문장을 만들어야 하기 때문에 추상 요약을 적용해야한다.
3. 데이터
1) 데이터 소개
(1) AIHub - 한국어 대화 요약
카카오톡 대화 데이터를 활용하여 요약문으로 라벨링한 데이터로 실제 fine-tuning 할때 사용된 데이터이다.
- Train Data : 279992
- Val Data : 35004
(2) AIHub - 한국어 SNS
카카오톡 대화 데이터로 요약문으로 라벨링한 데이터는 존재하지 않아 도메인 적응용으로만 활용된 데이터이다.
- Train Data : 1599992
- val Data : 200004
2) 데이터 전처리
실제 서비스를 배포하기 위해서는 고객의 입장에서 많은 질문들을 던지며 개선해나가야 한다. 그중 데이터 전처리는 중요한 의미를 내포하고 있다고 생각한다. 서비스에 있어서 중요한 것은 고객의 정보가 누설되지 않는 것이다. 왜냐하면 정보가 누설되면 고객의 입장에서는 정보 조작의 의심을 할 수 있고, 본인이 표현하고 싶은 말을 다 담아 주지 않고 임의로 제거를 하니 불쾌할 것이다. 즉, 전처리는 최소한만 진행할 것이고 요약에 방해 되는 것만 전처리하고자 한다.
- 영어 텍스트 소문자
- 여러개의 자음과 모음 예)ㅋㅋㅋㅋㅋ
- 여러개의 공백을 하나의 공백으로
- 문장 양쪽 공백 제거
def preprocess_sentence(sentence):
sentence = sentence.lower() # 텍스트 소문자화
sentence = re.sub(r'[ㄱ-ㅎㅏ-ㅣ]+[/ㄱ-ㅎㅏ-ㅣ]', '', sentence) # 여러개 자음과 모음을 삭제한다.
sentence = re.sub(r'[" "]+', " ", sentence) # 여러개 공백을 하나의 공백으로 바꿉니다.
sentence = sentence.strip() # 문장 양쪽 공백 제거
return sentence3) 간단한 EDA
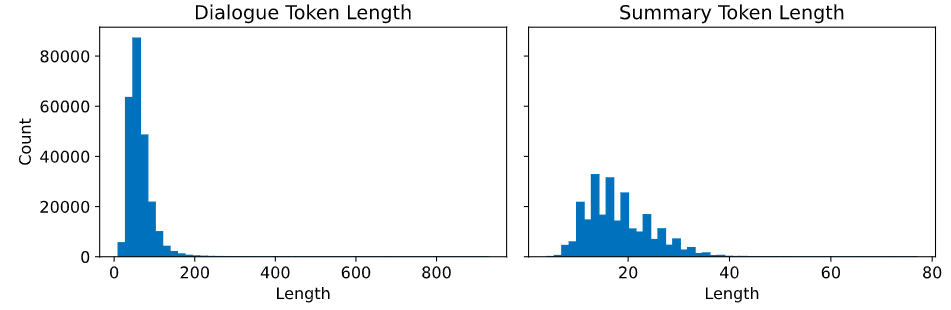
max_len을 정하기 위하여 간단한 tokenizer.encode를 활용하여 토큰의 갯수를 세리는 EDA를 진행한다.
4. 토큰화
1) 스폐셜 토큰 기법
해당 프로젝트는 불용어 처리 vs 스폐셜 토큰 기법중 스폐셜 토큰을 사용하기로 하였다. 이유는 데이터에 보완을 위해서 #@주소#, #@이모티콘#등으로 처리된 데이터가 굉장히 많다. 이러한 데이터는 라벨링 과정에서 보완을 위해 어쩔 수 없이 마스킹 하였지만 실제 문맥을 파악하기 위해서는 유의미한 데이터이기 때문에 불용어 처리를 하면 성능 저하 및 고객의 정보가 양성에서 음성으로 표현되는 아찔한 상황이 펼쳐질 수 있기 때문이다.
2) Typed Entity Marker 기법
메타 데이터에 앞뒤로 #을 넣어줌으로(ex. #쇼핑#) 이론상 Train Data 학습시 성능을 올려주는 역할을 한다. 실제로 프로젝트에 적용하여 성능을 향상 시킬 수 있었다. 성능이 향상되는 이유는 다음과 같다. 같은 카테고리속의 요약문은 어느정도 상관관계를 가지고 있다. 이러한 카테고리속 상관성을 학습하게 해주었기 때문에 성능이 향상될 수 있었던 것이다.
3) 토크나이저
토크나이저는 input_ids, attention_mask, decoder_input_ids, decoder_attention_mask, labels를 만들었다. input_ids와 attention_mask에는 인코더 입력 토큰이다. 이를 토큰화할 때는 다음 대화로 넘어갈 때 [sep] 토큰을 입력하여 대화간 구분을 지었다. decoder_input_ids와 decoder_attention_mask는 디코더 입력 토큰이다. 이는 decoder_input_ids의 시작 부분에 [bos] 토큰을 넣어 시작 지점을 구분하였다. labels의 예측해야 하는 결과의 토큰으로 [eos]로 끝지점을 구분하였고 pad부분은 -100으로 치환하여 손실함수를 계산하지 않도록 하였다.
decoder_input_ids에는 예측을 시작하는 지점을 표시하기 위해서 [bos], labels에는 예측을 끝내는 지점을 위해[eos]를 지정하였다.
마치며
이번 포스팅에서는 모델 소개, 추출 요약과 추상 요약 소개, Data에 대한 설명 및 토큰화까지 알아보았다. 즉, 개요와 데이터를 다루는 기법들 알아보았다. 다음 포스팅에서 나머지 모델링 기법, 평가 지표까지 모델 학습과 평가에 대해서 알아보도록 하겠다.
github로 이동 : KoBART를 활용한 카카오톡 대화 요약 서비스
