
정의와 성질
해시 자료구조는 키(key)에 대응되는 값(value)을 저장하는 자료구조이다. 아래 예시에서는 카드 번호가 key, 사람의 이름이 value가 된다. 여기에 새로운 카드 번호와 이름 쌍을 넣는다거나, 특정 카드 번호가 누구의 것인지를 찾으려면 어떻게 해야 될까?

가장 쉬운 방법을 떠올려보면, 그냥 배열에 모든 데이터를 다 넣어둔 다음 원하는 데이터를 찾을 때까지 탐색하는 방법이 있다. 이렇게 구현하면 삽입은 배열의 맨 끝에서 일어나므로 O(1), 특정 데이터를 지우는 건 O(N), 그리고 특정 카드 번호가 누구의 것인지 찾는 연산도 O(N)이 걸릴 것이다.
그런데 해시 자료구조에서는 insert, erase, find, update 등의 연산이 모두 O(1)밖에 걸리지 않는다.
보통 자료구조에서는 배열처럼 인덱스를 갖고 특정 원소를 찾으면 O(1), 중간에서 삽입/삭제가 일어나면 O(N), 또는 연결 리스트처럼 삽입/삭제가 O(1)이지만, 탐색하는 데 O(N)이 걸리는 식으로, 특정 연산은 빠르지만 특정 연산은 느린 경우가 많다.
하지만, 해시는 모든 연산이 O(1)이다. 이것이 어떻게 가능한 것일까?!
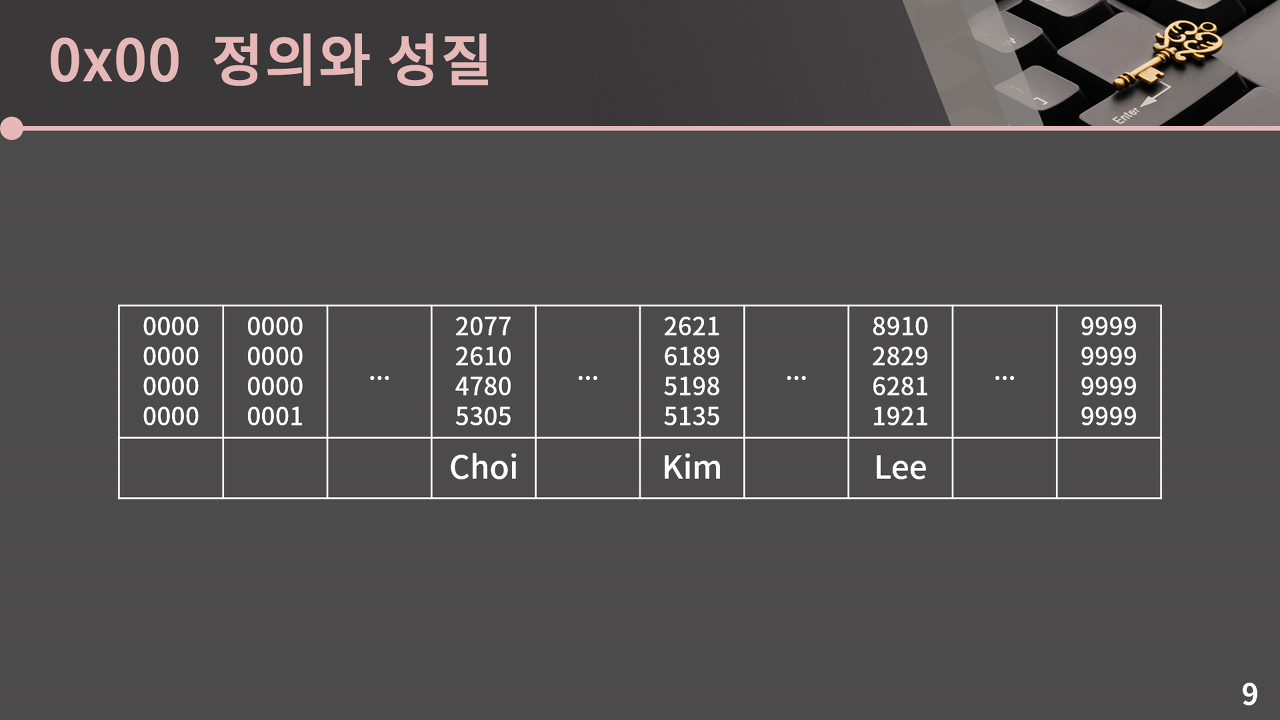
만약 우리가 메모리 공간의 크기가 무한대인 컴퓨터를 갖고 있다면, 배열을 이용하여 앞서 예로 든 카드 번호와 이름의 매칭을 효율적으로 진행할 수 있다. 각 카드 번호를 배열의 인덱스로 사용하는 테이블을 만들면 된다. 하지만, 문제는 카드 번호의 종류가 총 10^16개로 말도 안 되게 많아서 40PB 만큼의 용량을 필요로 한다. 1TB 외장하드를 4만개 준비해야 하는 용량이다. 이것은 현실적으로 불가능하다.
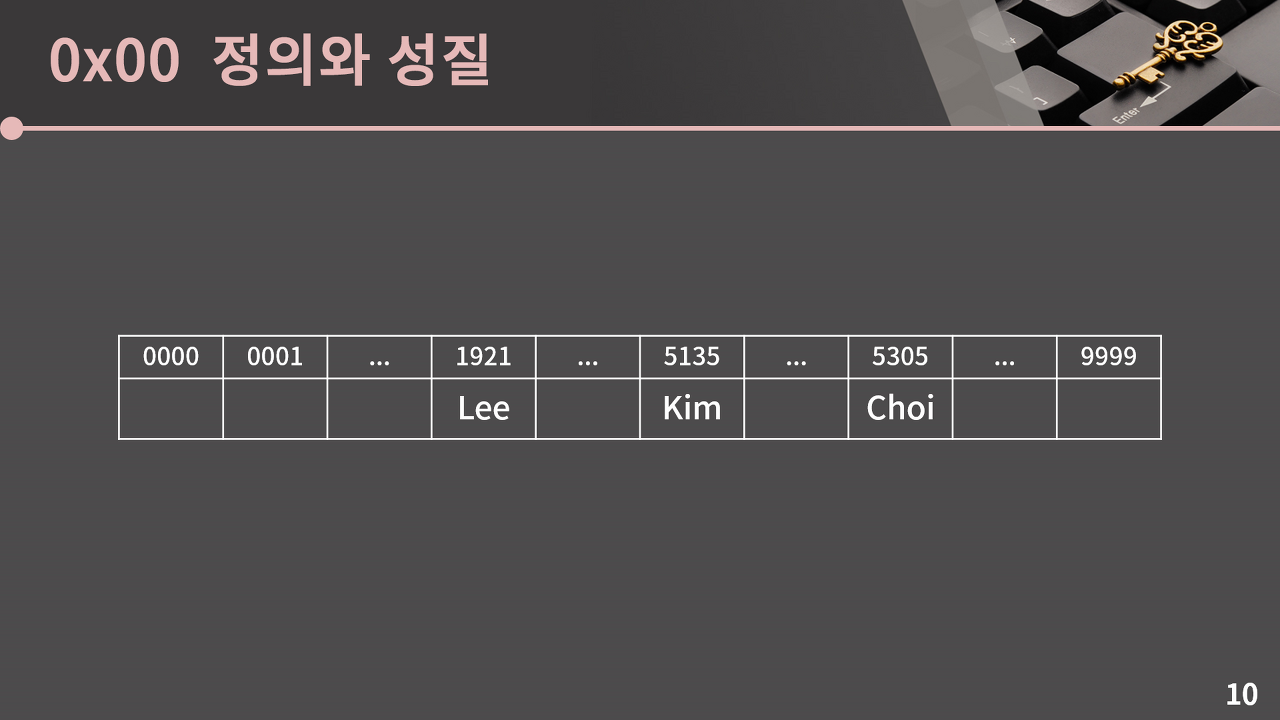
그런데, 비록 카드 번호의 종류가 총 10^16개라고 해도, 우리는 그 중에서 아주 일부의 카드 번호만 저장할 수도 있다. 예를 들어, 16자리 전체 번호를 저장할 필요 없이, 번호의 맨 뒷자리 4개만 배열의 인덱스로 사용하는 게 훨씬 합리적이다. 그러면 insert, erase, find 연산 모두 주어진 카드 번호의 맨 뒷자리 4개를 보고, 그에 해당하는 처리를 O(1)에 해줄 수 있기 때문이다.
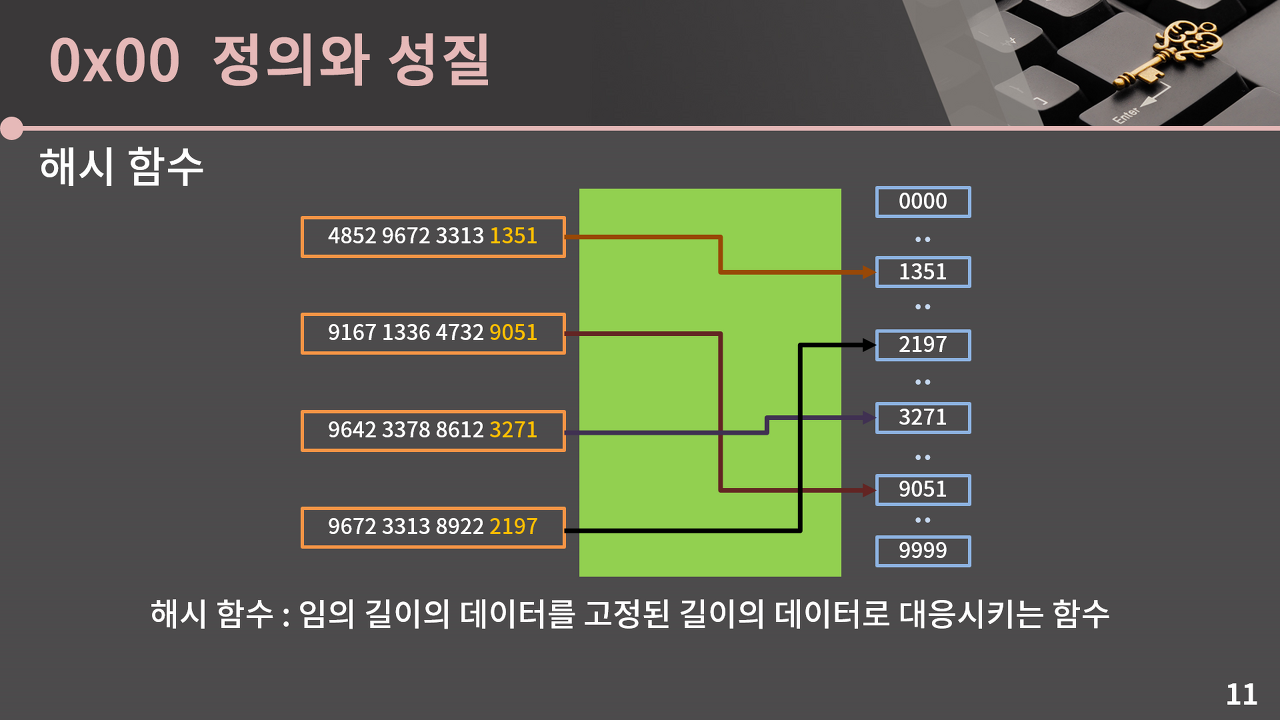
해시 자료구조에서는 해시 함수라는 게 사용된다. 해시 함수는 마치 16자리 카드 번호에서 뒷 4자리만 배열의 인덱스로 사용한 것과 같이, 임의의 길이의 데이터를 고정된 길이의 데이터로 대응시키는 함수이다.
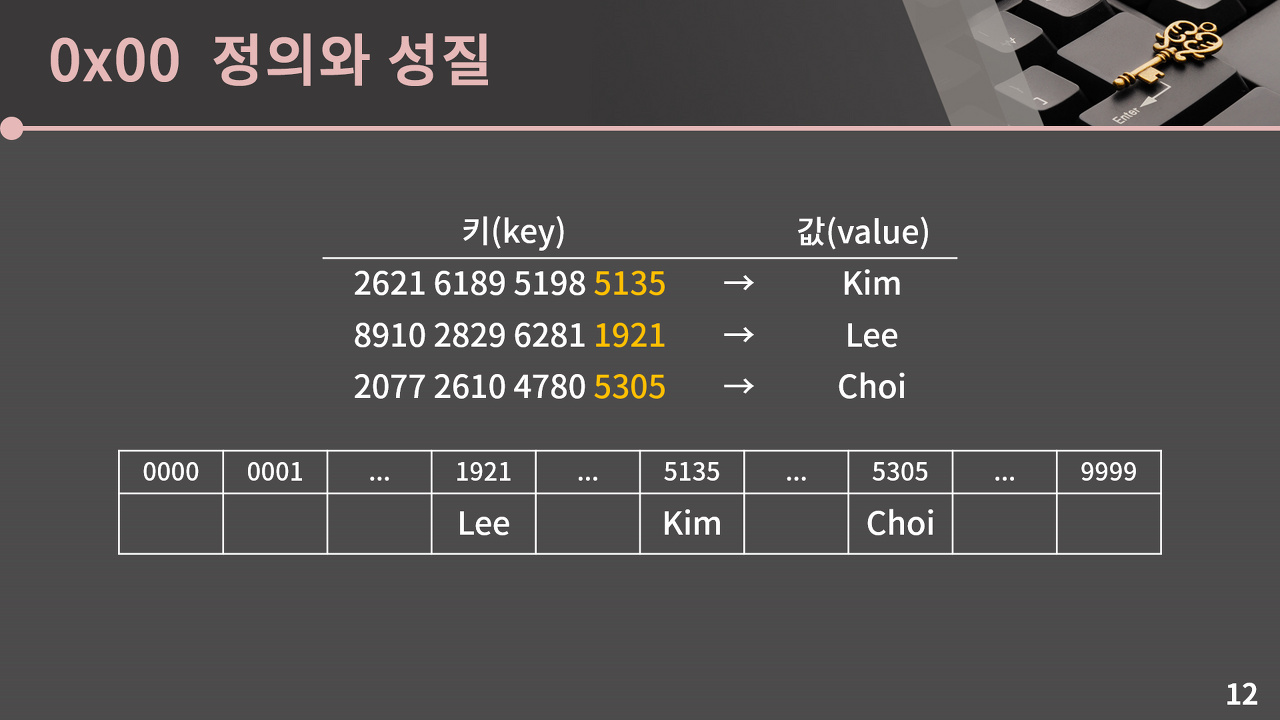
즉, 해시 자료구조는 키를 적당히 배열의 인덱스로 보내는 해시 함수를 하나 둬서 이렇게 테이블로 관리하는 자료구조인 것이다. 참고로 이러한 테이블을 해시 테이블이라고 부른다. 이걸 이용하면 insert, erase, find 등과 같은 연산을 모두 O(1)에 수행할 수 있다.
그런데, 자연스럽게 이런 의문이 들 수 있다.
만약 서로 다른 사람에 대해 카드 번호의 뒷 4자리가 동일하면 어떡하지?
이처럼 서로 다른 키가 같은 해시 값을 가지는 것을 '해시 충돌'이라 부르며, 이를 잘 처리해주는 것이 해시 자료구조의 성능에 가장 큰 영향을 준다!!
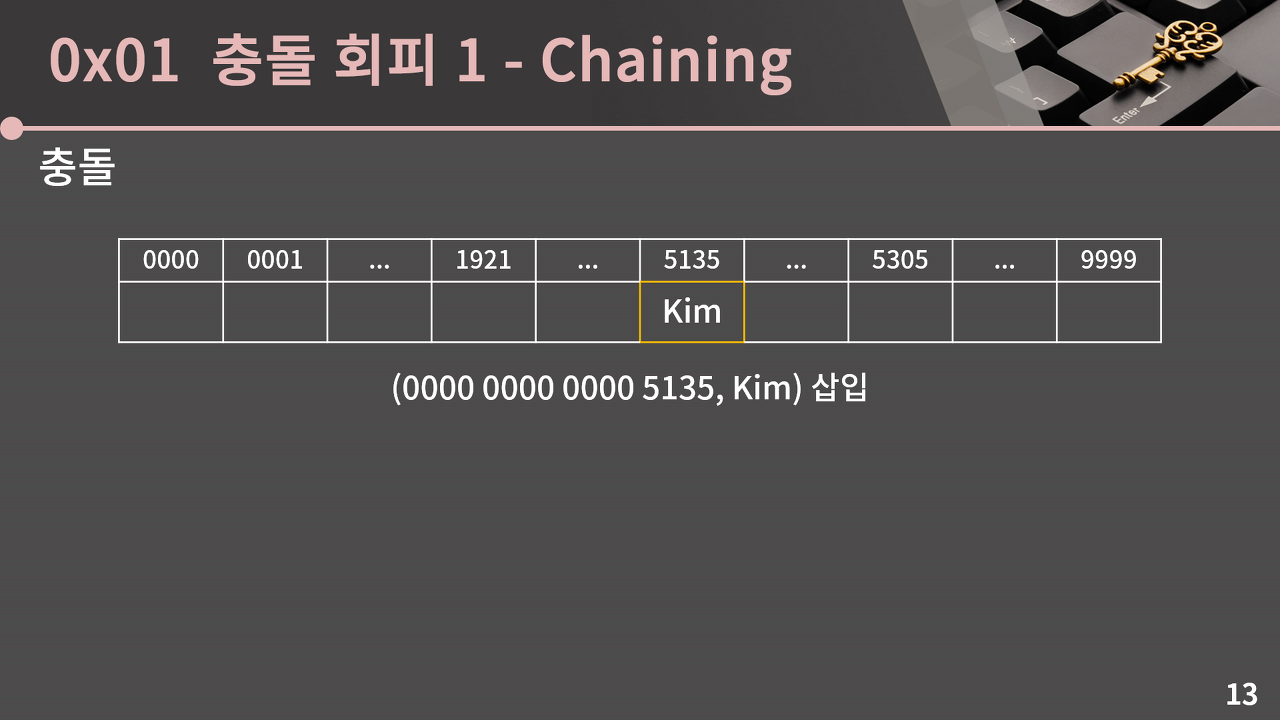
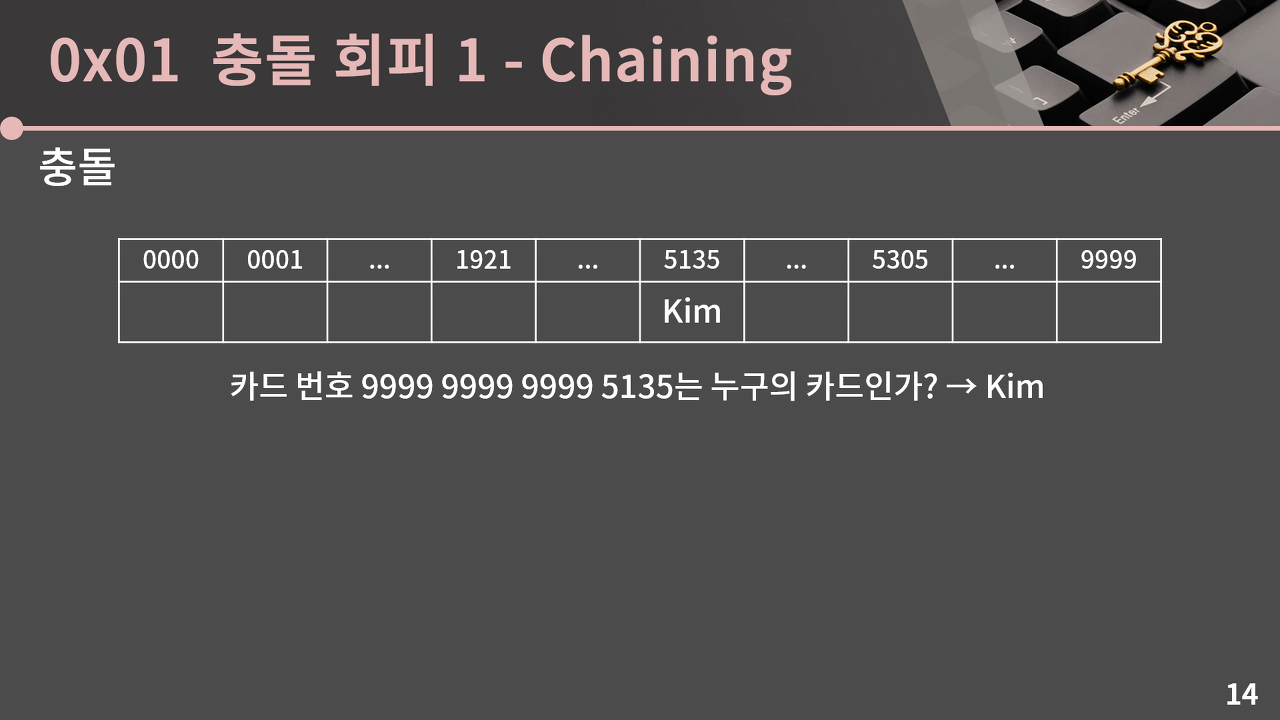
예를 들어, (0000 0000 0000 5135, Kim) 쌍을 해시 테이블의 인덱스 5135 위치에 넣었는데, 그 다음으로 9999 9999 9999 5135가 누구의 카드인지 묻는 질문이 들어왔다고 해보자.
그러면 카드 번호의 뒷 4자리에 따라 배열의 5135 인덱스를 볼 것이고, 그에 해당하는 값인 Kim을 답할 것이다. 하지만, 실제로는 테이블에 적힌 Kim이 '0000 0000 000 5135'에 대응되는 값인지, '9999 9999 9999 5135'에 대응되는 값인지 알 방법이 없다.
해시 함수를 적절히 잘 잡아서 충돌이 아예 발생하지 않게 할 수는 없을까? 라는 의문이 들 수도 있는데, 해시 함수의 목적 자체가 원래 함수의 입력으로 주어지는 정의역의 크기가 너무 커서, 이걸 바로 배열의 인덱스로 활용할 수 없으니 이 범위를 줄이고자 하는 데 있다. 앞선 예시와 같이 원래 카드 번호의 종류가 10^16개이지만, 뒷 4자리만 활용하여 10^4개로 줄인 것처럼 말이다. 따라서, 해시 충돌이 발생하는 것 자체는 달리 막을 방법이 없다.
하지만 똑똑한 사람들이 해시 충돌이 발생했을 때의 회피 방안에 대해 많은 연구를 진행했다. 크게 Chaining, Open addressing으로 나눌 수 있으며, 이에 대해 알아보자!
충돌 회피
Chaining
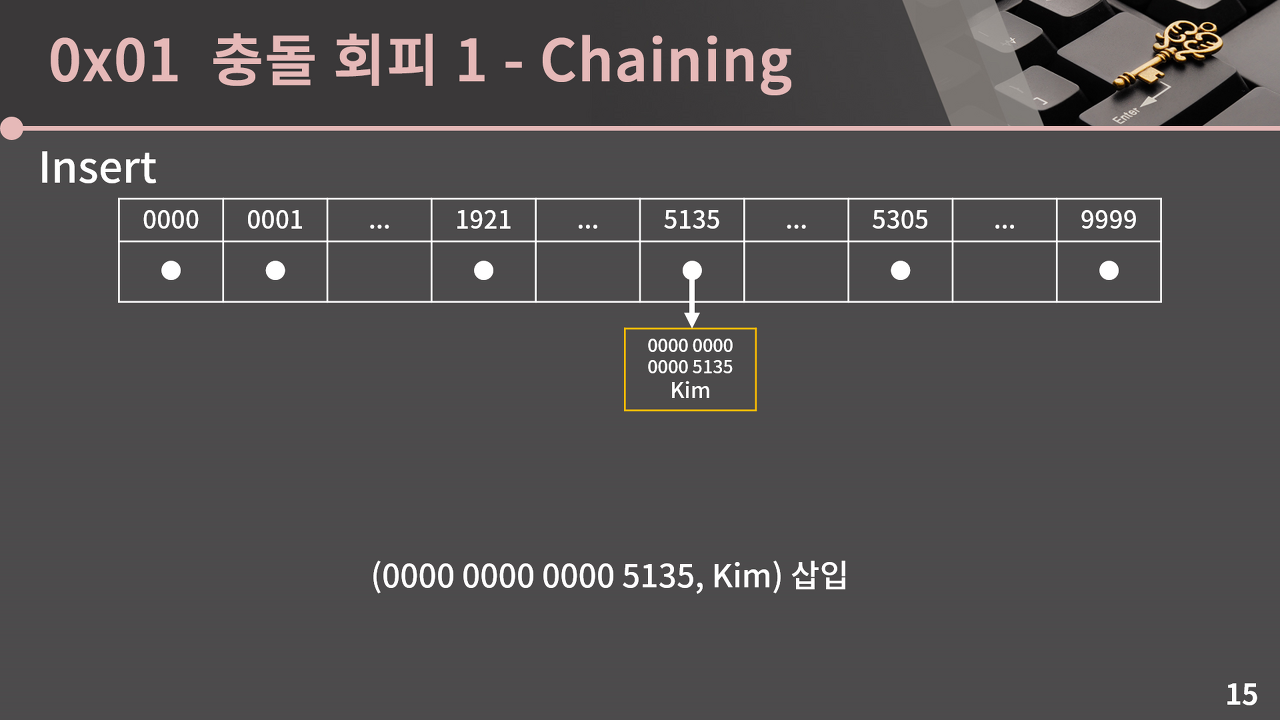
체이닝 기법에서는 해시 테이블의 각 인덱스마다 연결 리스트를 하나씩 둔다. (연결 리스트 대신 C++의 vector 같은 동적 배열도 사용 가능) 그리고 삽입이 발생하면 해당하는 인덱스의 연결 리스트에 값을 추가한다.
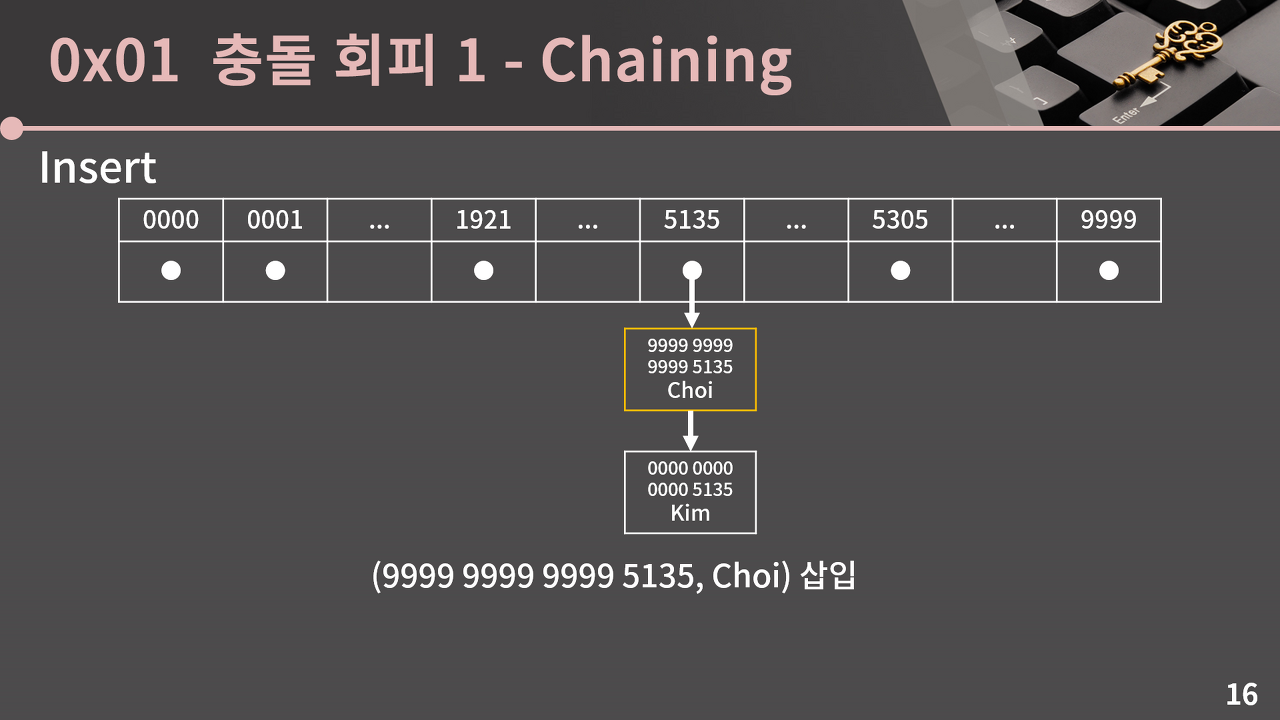
이렇게 하면 동일한 인덱스에 여러 개의 키 값을 저장할 수 있으므로 충돌을 회피할 수 있다.
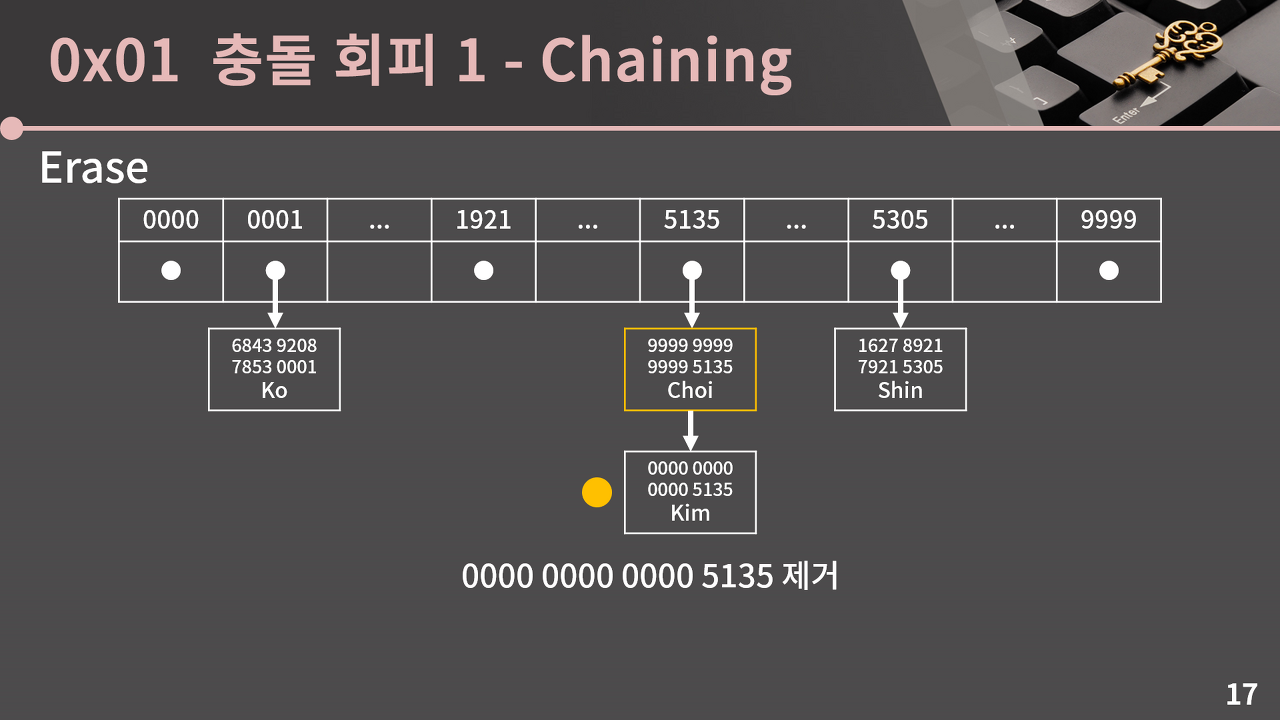
원소를 지울 때도 카드 번호 뒷 4자리에 해당하는 인덱스를 찾아서, 그에 해당하는 연결 리스트에 있는 특정 원소를 제거하면 된다.
이렇게 각 인덱스마다 연결 리스트를 둬서 충돌을 회피하는 방법을 체이닝이라 부르며, 실제로 C++ STL에 있는 해시 자료구조는 체이닝 기법을 이용하고 있다.
그리고 극단적인 예시를 한 가지 생각해보면, 만약 운이 안 좋아서 키에 대한 해시 값이 모두 일치한다고 해보자. 그러면 그냥 연결 리스트 1개에서 insert, erase, find, update 연산을 다 하는 상황이 된다. insert는 매번 헤더에 붙인다고 치면 O(1), 나머지는 리스트에서 원하는 위치까지 이동해야 하므로 O(N)이 걸린다.
따라서, 해시 자료구조는 이상적인 상황에서는 O(1)이지만, 충돌이 빈번할수록 성능이 저하되고, 모든 키의 해시 값이 같은 최악의 상황에서는 O(N)이 된다. 이후에 나올 Open addressing 방법도 마찬가지이다.
그렇기 때문에 해시에서는 각 키의 해시 값이 최대한 균등하게 퍼져야 성능이 좋아지고, 이를 위해서는 주어진 데이터에 대한 좋은 해시 함수를 정하는 것이 중요하다.
Open addressing
이 방법은 각 인덱스마다 연결 리스트를 뒀던 체이닝과 다르게, 그냥 테이블의 인덱스에 (키, 값) 쌍을 바로 넣는다. 그런데 어떻게 충돌을 회피한다는 건지 알아보자!

예를 들어, 먼저 3333 인덱스에 (0000 0000 0000 3333, Kim) 쌍을 삽입한다.

그리고 (6278 5651 9104 3333, Lee)를 3333번지에 넣고 싶지만, 비어있지 않기 때문에 바로 다음 칸에 내용을 적는다.

그리고 (7298 1127 6004 3334, Bae)를 삽입할 때는 3334번지에 넣고 싶지만, 이번에도 비어있지 않기 때문에 그 다음 칸에 적는다.

이러한 과정을 반복하고 나서, (3492 0658 8348 3333)은 누구의 카드인지 찾고 싶다면?
우선 3333 인덱스를 먼저 확인한다. 하지만, 해당 칸에 적힌 값은 우리가 원하는 값과 다르다. 따라서, 그 다음 칸인 3334번지를 확인한다. 이런 다음 칸으로 이어지며 탐색하다가 동일한 값을 발견하면 탐색을 종료한다.

반면에, 해시 테이블에서 계속 칸을 이동하며 해당하는 값을 찾다가 빈 공간이 나오면, 해당 카드 번호가 해시 테이블에 저장되어 있지 않다는 걸 확신할 수 있다.

그렇다면, 해시 테이블에서 원소를 지울 때는? 결론부터 말하자면 인덱스에 해당하는 값을 지우고 그 자리를 그냥 비워두면 안 된다!
왜냐하면 예를 들어 이후 (7298 1127 6004 3334)를 찾는다면, 3334번지가 비어있을 때 그 다음으로 넘어가지 않고 바로 값이 테이블에 존재하지 않는다고 판단하기 때문이다.

따라서, Open addressing 방식에서는 삭제 시 그냥 값을 날려서 빈칸을 만들지 않고, 해당 칸에 쓰레기 값을 두거나 별도의 배열을 두거나 해서 해당 칸이 빈칸이 아니라, 원래 값이 있었지만 제거된 상태임을 명시해줘야 한다.
그래야 find, erase 연산에서 쓰레기 값이 들어있는 칸을 만나면, 빈칸과 다르게 계속 탐색을 이어나갈 수 있다. 그리고 insert 연산 수행 시에는 빈칸 뿐만 아니라 dummy가 들어있는 칸에도 새로운 값을 삽입할 수 있다.
Linear Probing

Open addressing에서 한 가지 더 알아둘 것은 Probing인데, 이는 '탐사'라는 뜻을 갖고 있다. 방금 예시에서 앞에서 충돌이 발생하면 오른쪽으로 한칸 이동하여 그 칸을 확인했는데, 이런 방식을 Linear Probing 이라고 한다.
이 방식은 계속 인접한 배열 칸을 확인하니까 Cache hit rate가 높다. 하지만, 단점으로는 Clustering을 들 수 있다. 이는 '군집'이라는 뜻인데, 위의 그림에서 주황색 영역처럼 데이터가 서로 뭉쳐있는 것을 의미한다. Linear Probing에서는 데이터가 추가될 때마다 위의 빨간색 영역처럼 Clustering의 크기가 1씩 늘어나게 된다. 이러한 클러스터링의 크기가 커질수록 인덱스가 해당 군집에 걸렸을 때 빈칸을 찾을 때까지 이동하는 횟수가 늘어나서, 결과적으로 성능을 저하시킨다.
Quadratic Probing
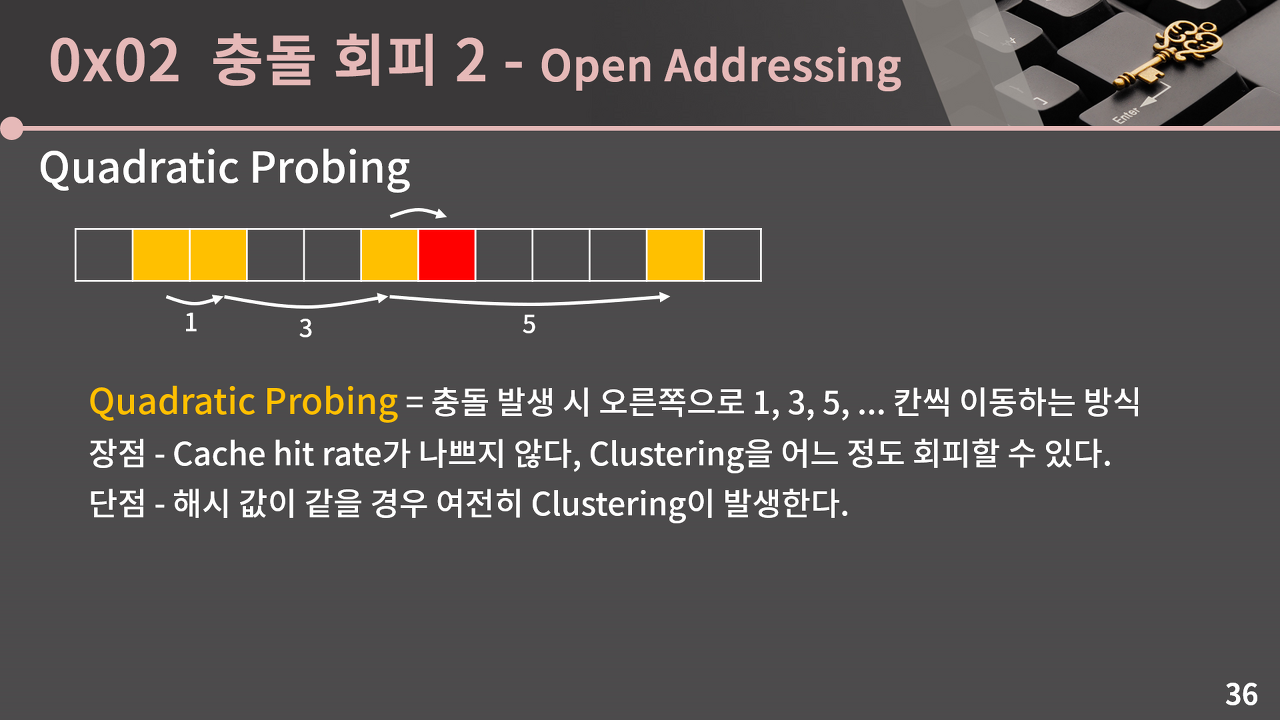
두번째 방법은 Quadratic Probing인데, 충돌이 발생하면 오른쪽으로 1칸, 3칸, 5칸 이동하는 방법이다. quadratic은 제곱이라는 뜻인데, 처음 위치를 기준으로 생각하면 1칸, 4칸, 9칸 이동하는 것이고 이는 1의 제곱, 2의 제곱, 3의 제곱이므로 Quadratic Probing이라고 부른다.
이 방식의 장점은 Linear Probing 만큼은 아니지만, Cache hit rate가 나쁘지 않다는 것이고, Clustering도 어느 정도 회피할 수 있다는 것이다.
다만, 단점은 해시 값이 같을 경우 계속 똑같은 경로를 따라가기 때문에 여전히 Clustering이 발생한다는 것이다.
Double Hashing

마지막 방법은 Double Hashing이다. 이것은 해시 함수를 하나 더 둬서 충돌이 발생했을 때, 몇 칸 점프할지를 이 새로운 해시 함수의 값으로 계산하는 방법이다.
예를 들어, 카드 번호 예시에서 뒷 4자리를 해시 함수로 사용하여 인덱스를 정했는데, 충돌이 발생했을 때 이동할 칸의 개수는 카드 번호의 앞 4자리로 정하는 것이다.
이 방식의 장점은 Clustering을 아주 효과적으로 회피할 수 있다는 것이다. 예를 들어, (1234 2222 5555 5555), (3333 3000 3210 5555) 이 두 개의 카드는 뒷 4자리가 같아서 충돌이 발생하지만, 앞의 4자리에 의해 (1234 2222 5555 5555)는 1234칸, (3333 3000 3210 5555)는 3333칸 뛰어서 각자 갈 길을 가게 된다.
그렇지만, Cache hit rate는 극악으로 안 좋아지는 게 단점이다.
C++ STL
내부적으로 해시 자료구조로 구현되어 있는 C++의 STL에 대해 알아보자.
unordered_set
void unordered_set_example() {
unorderd_set<int> s;
s.insert(-10);
s.insert(100);
s.insert(15); // -10 100 15
s.insert(-10); // -10 100 15 (중복 허용 X)
cout << s.erase(100) << "\n"; // 제거된 요소의 개수 반환 (1)
cout << s.erase(20) << "\n"; // 제거된 요소의 개수 반환 (0)
if(s.find(15) != s.end()) cout << "15 in s\n";
else cout << "15 not in s\n";
cout << s.size() << "\n"; // 2
cout << s.count(50) << "\n"; // 0
for(auto e: s) cout << e << " ";
}unordered_multiset
void unordered_multiset_example() {
unorderd_multiset<int> ms;
ms.insert(-10);
ms.insert(100);
ms.insert(15); // -10 100 15
ms.insert(-10);
ms.insert(15); // -10 -10 100 15 15 (중복 허용 O)
cout << ms.size() << "\n"; // 5
for(auto e: ms) cout << e << " ";
// {-10, -10, 100}, 제거된 요소의 개수 반환 (2)
// 발견된 원소를 모두 지운다는 것에 주의!!
cout << ms.erase(15) << "\n";
// {-10, 100}, 첫번째로 발견된 원소 하나만 삭제
ms.erase(ms.find(-10));
// {-10, 100, 100}
ms.insert(100);
cout << ms.count(100) << "\n"; // 2
}unordered_map
void unordered_map_example() {
unordered_map<string, int> m;
m["hi"] = 123;
m["bkd"] = 1000;
m["gogo"] = 165;
cout << m.size() << "\n"; // 3
m["hi"] = -7; // 기존의 값 대체 (중복 허용 X)
if(m.find("hi") != m.end()) cout << "hi in m\n";
else cout << "hi not in m\n";
m.erase("bkd");
for(auto e: m)
cout << e.first << " " << e.second << "\n";
}7785번. 회사에 있는 사람
https://www.acmicpc.net/problem/7785
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#include <unordered_set>
#include <set>
using namespace std;
typedef pair<int, int> pii;
typedef long long ll;
int main() {
ios_base::sync_with_stdio(0);
cin.tie(0);
int N;
cin >> N;
// 배열을 이용한 삭졔: O(N)
// 해시를 이용한 삭제: O(1)
unordered_set<string> s;
for(int i = 0; i < N; i++){
string name, dir;
cin >> name >> dir;
if(dir == "enter"){
s.insert(name);
}else{
// 이름이 중복되지 않으므로 해당하는 이름 하나만 삭제
s.erase(name);
}
}
vector<string> ans(s.begin(), s.end());
// 내림차순 정렬
sort(ans.begin(), ans.end(), greater<string>());
for(auto name: ans) cout << name << "\n";
return 0;
}